hadoop3.1专题

centos编译hadoop3.1
文章目录 安装本地工具编译protoc编译选项maven仓库编译hadoop 将 Hadoop 编译为本地(native)代码,加速文件编码、压缩、传输 安装本地工具 sudo yum install -y cmake gcc-c++ libtirpc-devel isa-l-devel snappy-devel zlib-devel openssl-devel libpme

window安装maven和hadoop3.1.4
前面的文章已讲解如何安装idea和进行基本设置,本文主要带着大家安装配置好maven和hadoop. 大家不用去官网下载,直接使用我发给大家的压缩文件,注意解压后的文件夹不要放在中文目录下,课堂上我们讲解过原因。 这是我电脑上的路径,大家最好都放在D:\\software目录下。 进行环境变量配置: 最后打开命令行窗口输入 显示版

HDFS编程实践(Hadoop3.1.3)
HDFS编程实践(Hadoop3.1.3) HDFS编程实践(Hadoop3.1.3)一、利用Shell命令与HDFS进行交互1、目录操作2、文件操作 二、利用Web界面管理HDFS三、利用 Java API 与 HDFS 进行交互(一) 在 Ubuntu 中安装 Eclipse(二) 使用 Eclipse 开发调试 HDFS Java 程序1. 在Eclipse中创建项目2. 为项目添加需
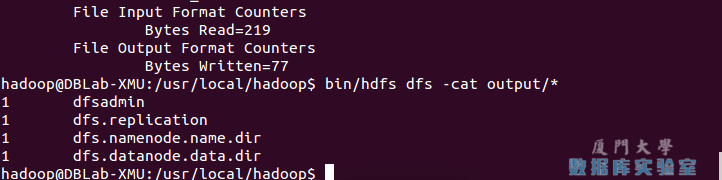
Hadoop安装笔记2单机/伪分布式配置_Hadoop3.1.3——备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项——任务2:离线数据处理
紧接着上一篇博客:Hadoop安装笔记1: Hadoop安装笔记1单机/伪分布式配置_Hadoop3.1.3——备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项——任务2:离线数据处理-CSDN博客https://blog.csdn.net/Zhiyilang/article/details/135236893?csdn_share_tail=%7B%22type%22%3
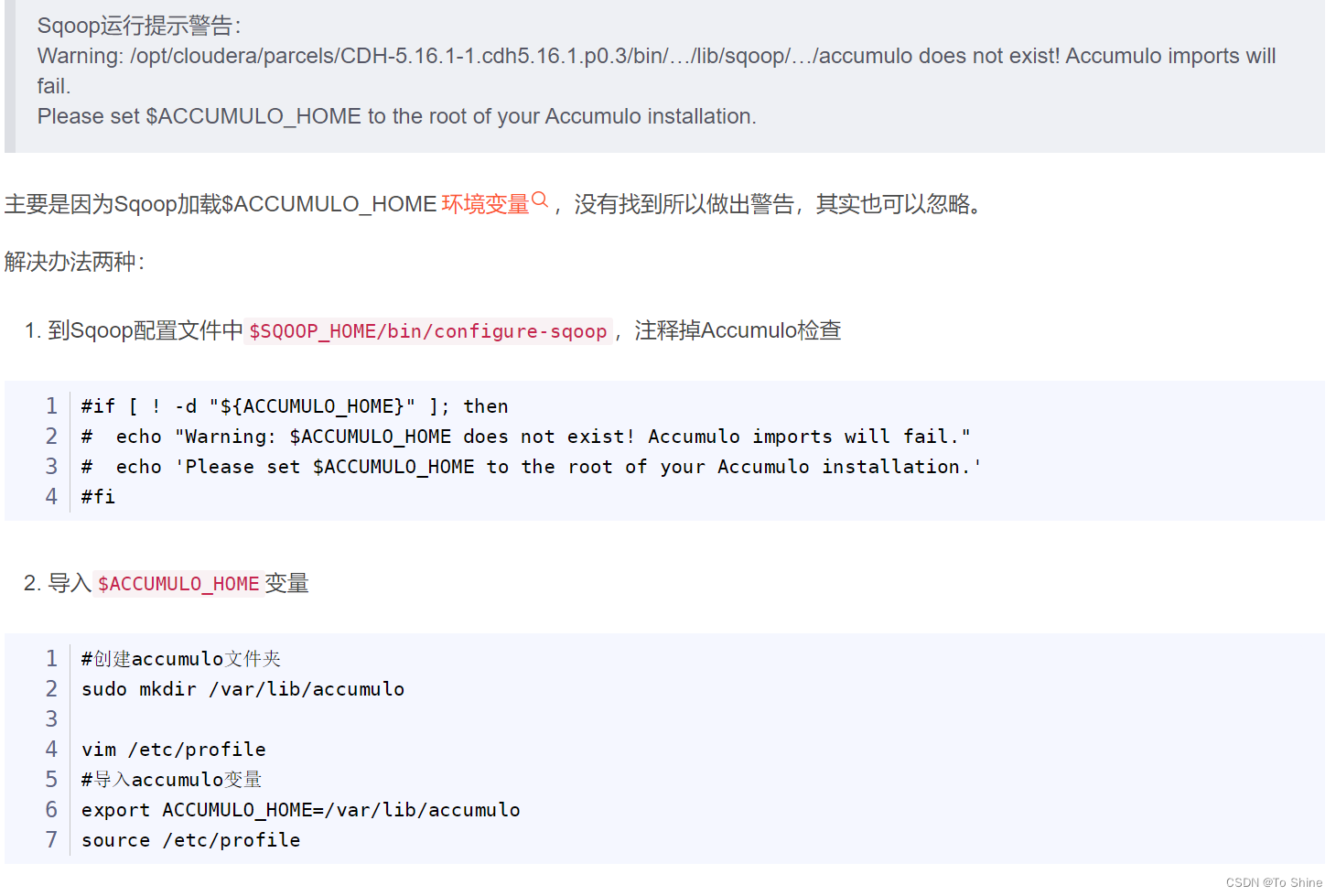
用户行为分析遇到的问题-ubantu16,hadoop3.1.3
用户行为分析传送门 我的版本 ubantu16 hadoop 3.1.3 habse 2.2.2 hive3.1.3 zookeeper3.8.3 sqoop 1.46/1.47 我sqoop把MySQL数据往hbase导数据时候有问题 重磅:大数据课程实验案例:网站用户行为分析(免费共享) 用户行为分析-小数据集 - CSDN App Hmaster节点老掉:配置zookeeper
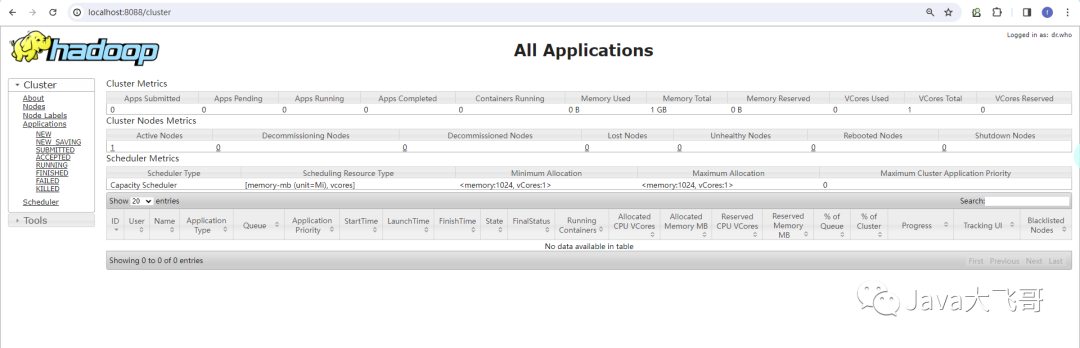
Windows10安装Hadoop3.1.3环境
Windows10安装Hadoop3.1.3环境 文章目录 1.安装包下载1.1.hadoop官网下载1.2下载winutils1.3安装文件 2.配置安装2.1安装配置JDK环境2.2解压hadoop压缩包2.3配置hadoop的环境变量2.3.1配置HADOOP_HOME2.3.2配置Path变量 2.4配置hadoop2.4.1 创建data和temp文件夹2.4.2配置hadoop

flume1.9 + hadoop3.1.3 配置hdfs sink
flume1.9 + hadoop3.1.3 按照这个大佬的方法将hadoop里面的jar包复制到flume的lib下:https://blog.csdn.net/weixin_43215322/article/details/115311773 # Name the components on this agenta2.sources = r2a2.sinks = k2a2.channe

Ambari2.7.3 Hortonworks3 HDP(hadoop3.1.0集群安装)
目录 一、目的: 二、版本选择: 三、hortonworks简介 四、准备工作: 4.1、Ambari、HDP版本介绍 4.2、工具包下载: 4.3、服务器防火墙关闭 4.3.1、关闭掉linux防火墙(所有机器) 4.4、修改主机名及机器隐射(hosts) 4.4.1、通过vi /etc/hostname 进行修改 4.4.2、修改/etc/hosts文件(所有机器) 4