本文主要是介绍视频目标检测 yolov,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
yolov相关介绍
预训练是检测动物世界的动物的,1060显卡单帧需要300毫秒
yolov相关介绍
论文地址: https://arxiv.org/pdf/2208.09686.pdf
代码地址: https://github.com/YuHengsss/YOLOV
| Model | size | mAP@50val | Speed 2080Ti(batch size=1) (ms) | weights |
|---|---|---|---|---|
| YOLOX-s | 576 | 69.5 | 9.4 | |
| YOLOX-l | 576 | 76.1 | 14.8 | |
| YOLOX-x | 576 | 77.8 | 20.4 | |
| YOLOV-s | 576 | 77.3 | 11.3 | |
| YOLOV-l | 576 | 83.6 | 16.4 | |
| YOLOV-x | 576 | 85.5 | 22.7 | |
| YOLOV-x + post | 576 | 87.5 | - |
视频目标检测(VID)具有挑战性,因为目标外观的高度变化以及某些帧中的各种劣化。积极的一面是,与静止图像相比,在视频的某一帧中进行检测可以得到其他帧的支持。因此,如何跨不同帧聚合特征是VID问题的关键。
大多数现有的聚合算法都是为两阶段检测器定制的。但是,由于两阶段的性质,此类检测器通常在计算上很耗时。今天分享的研究者提出了一种简单而有效的策略来解决上述问题,该策略花费了边际开销,并显著提高了准确性。具体来说,与传统的两阶段流水线不同,研究者主张将区域级候选放在一阶段检测之后,以避免处理大量低质量候选。此外,构建了一个新的模块来评估目标框架与其参考框架之间的关系,并指导聚合。
进行了广泛的实验和消融研究以验证新提出设计的有效性,并揭示其在有效性和效率方面优于其他最先进的VID方法。基于YOLOX的模型可以实现可观的性能(例如,在单个2080Ti GPU上的ImageNet VID数据集上以超过30 FPS的速度达到87.5% AP50),使其对大规模或实时应用程序具有吸引力。
视频目标检测可以看作是静止图像目标检测的高级版本。直观地说,可以通过将帧一一输入静止图像目标检测器来处理视频序列。但是,通过这种方式,跨帧的时间信息将被浪费,这可能是消除/减少单个图像中发生的歧义的关键。
如上图所示,视频帧中经常出现运动模糊、相机散焦和遮挡等退化,显着增加了检测的难度。例如,仅通过查看上图中的最后一帧,人类很难甚至不可能分辨出物体在哪里和是什么。另一方面,视频序列可以提供比单个静止图像更丰富的信息。换言之,同一序列中的其他帧可能支持对某一帧的预测。因此,如何有效地聚合来自不同帧的时间消息对于准确性至关重要。从上图可以看出,研究者提出的方法给出了正确的答案。
03
新框架
考虑到视频的特性(各种退化与丰富的时间信息),而不是单独处理帧,如何从其他帧中为目标帧(关键帧)寻求支持信息对于提高视频检测的准确性起着关键作用。最近的尝试是在准确性上的显着提高证实了时间聚合对问题的重要性。然而,大多数现有方法都是基于两阶段的技术。
如前所述,与一级基础相比,它们的主要缺点是推理速度相对较慢。为了减轻这种限制,研究者将区域/特征选择放在单级检测器的预测头之后。
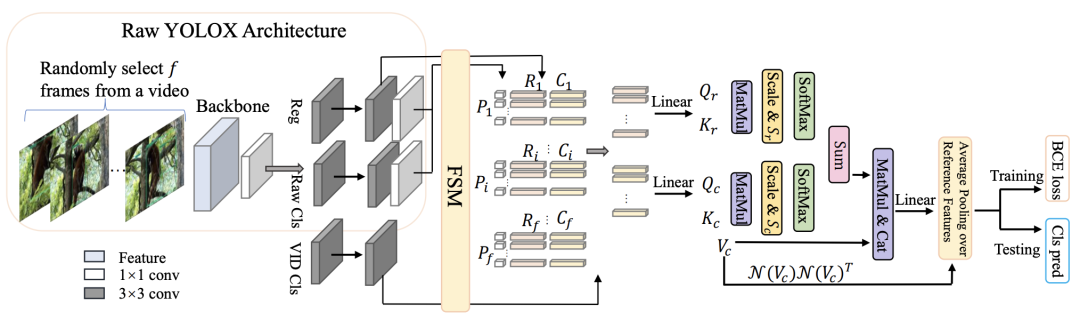
研究者选择YOLOX作为基础来展示研究者的主要主张。提出的框架如上图所示。
让我们回顾一下传统的两阶段管道:
1)首先“选择”大量候选区域作为提议;
2)确定每个提议是否是一个目标以及它属于哪个类。计算瓶颈主要来自于处理大量的低置信区域候选。
从上图可以看出,提出的框架也包含两个阶段。不同的是,它的第一阶段是预测(丢弃大量低置信度的区域),而第二阶段可以被视为区域级细化(通过聚合利用其他帧)。
通过这一原则,新的设计可以同时受益于一级检测器的效率和从时间聚合中获得的准确性。值得强调的是,如此微小的设计差异会导致性能上的巨大差异。所提出的策略可以推广到许多基础检测器,例如YOLOX、FCOS和PPYOLOE。
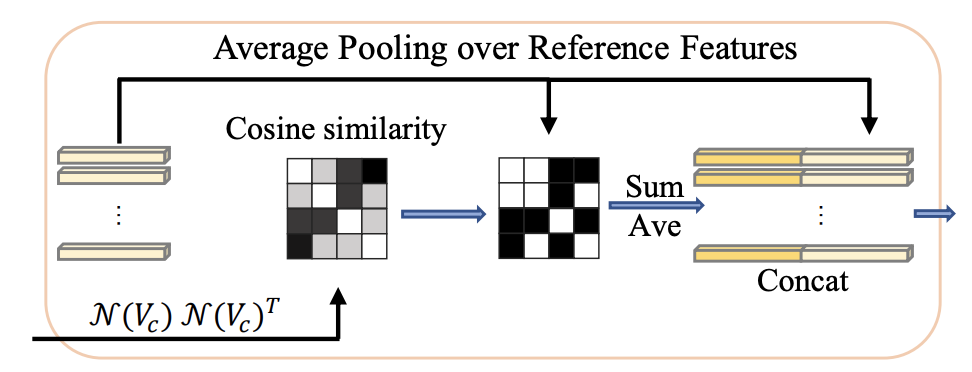
此外,考虑到softmax的特性,可能一小部分参考特征持有大部分权重。换句话说,它经常忽略低权重的特征,这限制了可能后续使用的参考特征的多样性。
为了避免这种风险,研究者引入了平均池化参考特征(A.P.)。具体来说,选择相似度得分高于阈值τ的所有参考,并将平均池化应用于这些。请注意,这项工作中的相似性是通过N (Vc)N(Vc)T计算的。算子N(·)表示层归一化,保证值在一定范围内,从而消除尺度差异的影响。通过这样做,可以维护来自相关特征的更多信息。然后将平均池化特征和关键特征传输到一个线性投影层中进行最终分类。该过程如是上图所示。
有人可能会问,N(Qc)N(Kc)T或N(Qr)N(Kr)T是否可以作为相似度执行。事实上,这是另一种选择。但是,在实践中,由于Q和K之间的差异,它不像我们在训练期间的选择那样稳定。
预训练是检测动物世界的动物的,1060显卡单帧需要300毫秒
视频预测代码:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.import argparse
import os
import time
from loguru import loggerimport cv2import torchfrom yolox.data.data_augment import ValTransform
from yolox.data.datasets import COCO_CLASSES
from yolox.data.datasets.vid_classes import VID_classes
# from yolox.data.datasets.vid_classes import OVIS_classes as VID_classes
from yolox.exp import get_exp
from yolox.utils import fuse_model, get_model_info, postprocess, vis
import randomIMAGE_EXT = [".jpg", ".jpeg", ".webp", ".bmp", ".png"]def make_parser():parser = argparse.ArgumentParser("YOLOX Demo!")# parser.add_argument(# "demo", default="video", help="demo type, eg. image, video and webcam"# )parser.add_argument("-expn", "--experiment_name", type=str, default=None)parser.add_argument("-n", "--name", type=str, default=None, help="model name")parser.add_argument("--path", default=r"C:\Users\Administrator\Videos\f7.mp4", help="path to images or video")parser.add_argument("--camid", type=int, default=0, help="webcam demo camera id")# exp fileparser.add_argument("-f", "--exp_file", default='../exps/yolov/yolov_s.py', type=str, help="pls input your expriment description file", )parser.add_argument("-c", "--ckpt", default='../yolov_s.pth', type=str, help="ckpt for eval")# parser.add_argument("-c", "--ckpt", default='../yoloxs_vid.pth', type=str, help="ckpt for eval")parser.add_argument("--device", default="gpu", type=str, help="device to run our model, can either be cpu or gpu", )parser.add_argument("--dataset", default='vid', type=str, help="Decide pred classes")parser.add_argument("--conf", default=0.05, type=float, help="test conf")parser.add_argument("--nms", default=0.5, type=float, help="test nms threshold")parser.add_argument("--tsize", default=576, type=int, help="test img size")parser.add_argument("--fp16", dest="fp16", default=True, action="store_true", help="Adopting mix precision evaluating.", )parser.add_argument("--legacy", dest="legacy", default=False, action="store_true", help="To be compatible with older versions", )parser.add_argument("--fuse", dest="fuse", default=False, action="store_true", help="Fuse conv and bn for testing.", )parser.add_argument("--trt", dest="trt", default=False, action="store_true", help="Using TensorRT model for testing.", )parser.add_argument('--output_dir', default='out', help='path where to save, empty for no saving')parser.add_argument('--gframe', default=32, help='global frame num')parser.add_argument('--save_result', default=True)return parserdef get_image_list(path):image_names = []for maindir, subdir, file_name_list in os.walk(path):for filename in file_name_list:apath = os.path.join(maindir, filename)ext = os.path.splitext(apath)[1]if ext in IMAGE_EXT:image_names.append(apath)return image_namesclass Predictor(object):def __init__(self, model, exp, cls_names=COCO_CLASSES, trt_file=None, decoder=None, device="cpu", legacy=False, ):self.model = modelself.cls_names = cls_namesself.decoder = decoderself.num_classes = exp.num_classesself.confthre = exp.test_confself.nmsthre = exp.nmsthreself.test_size = exp.test_sizeself.device = deviceself.preproc = ValTransform(legacy=legacy)self.model = model.half()def inference(self, img, img_path=None):tensor_type = torch.cuda.HalfTensorif self.device == "gpu":img = img.cuda()img = img.type(tensor_type)with torch.no_grad():t0 = time.time()outputs, outputs_ori = self.model(img, nms_thresh=self.nmsthre)logger.info("Infer time: {:.4f}s".format(time.time() - t0))return outputsdef visual(self, output, img, ratio, cls_conf=0.0):if output is None:return imgbboxes = output[:, 0:4]# preprocessing: resizebboxes /= ratiocls = output[:, 6]scores = output[:, 4] * output[:, 5]vis_res = vis(img, bboxes, scores, cls, cls_conf, self.cls_names)return vis_resdef image_demo(predictor, vis_folder, path, current_time, save_result):if os.path.isdir(path):files = get_image_list(path)else:files = [path]files.sort()for image_name in files:outputs, img_info = predictor.inference(image_name, [image_name])result_image = predictor.visual(outputs[0], img_info, predictor.confthre)if save_result:save_folder = os.path.join(vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time))os.makedirs(save_folder, exist_ok=True)save_file_name = os.path.join(save_folder, os.path.basename(image_name))logger.info("Saving detection result in {}".format(save_file_name))cv2.imwrite(save_file_name, result_image)ch = cv2.waitKey(0)if ch == 27 or ch == ord("q") or ch == ord("Q"):breakdef imageflow_demo(predictor, vis_folder, current_time, args):gframe = args.gframecap = cv2.VideoCapture(args.path)width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # floatheight = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # floatfps = cap.get(cv2.CAP_PROP_FPS)save_folder = os.path.join(vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time))os.makedirs(save_folder, exist_ok=True)ratio = min(predictor.test_size[0] / height, predictor.test_size[1] / width)save_path = os.path.join(save_folder, args.path.split("/")[-1])save_path='out.mp4'logger.info(f"video save_path is {save_path}")vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height)))frames = []outputs = []ori_frames = []while True:ret_val, frame = cap.read()if ret_val:ori_frames.append(frame)frame, _ = predictor.preproc(frame, None, exp.test_size)frames.append(torch.tensor(frame))else:breakres = []frame_len = len(frames)index_list = list(range(frame_len))random.seed(41)random.shuffle(index_list)random.seed(41)random.shuffle(frames)split_num = int(frame_len / (gframe)) #for i in range(split_num):res.append(frames[i * gframe:(i + 1) * gframe])res.append(frames[(i + 1) * gframe:])for ele in res:if ele == []: continueele = torch.stack(ele)t0 = time.time()outputs.extend(predictor.inference(ele))outputs = [j for _, j in sorted(zip(index_list, outputs))]for output, img in zip(outputs, ori_frames[:len(outputs)]):result_frame = predictor.visual(output, img, ratio, cls_conf=args.conf)if args.save_result:cv2.imshow("sdf",result_frame)cv2.waitKey(0)vid_writer.write(result_frame)def main(exp, args):if not args.experiment_name:args.experiment_name = exp.exp_namefile_name = os.path.join(exp.output_dir, args.experiment_name)os.makedirs(file_name, exist_ok=True)vis_folder = Noneif args.save_result:vis_folder = os.path.join(file_name, "vis_res")os.makedirs(vis_folder, exist_ok=True)if args.trt:args.device = "gpu"logger.info("Args: {}".format(args))if args.conf is not None:exp.test_conf = args.confif args.nms is not None:exp.nmsthre = args.nmsif args.tsize is not None:exp.test_size = (args.tsize, args.tsize)model = exp.get_model()logger.info("Model Summary: {}".format(get_model_info(model, exp.test_size)))if args.device == "gpu":model.cuda()model.eval()if not args.trt:if args.ckpt is None:ckpt_file = os.path.join(file_name, "best_ckpt.pth")else:ckpt_file = args.ckptlogger.info("loading checkpoint")ckpt = torch.load(ckpt_file, map_location="cpu")# load the model state dictmodel.load_state_dict(ckpt["model"])logger.info("loaded checkpoint done.")if args.fuse:logger.info("\tFusing model...")model = fuse_model(model)if args.trt:assert not args.fuse, "TensorRT model is not support model fusing!"trt_file = os.path.join(file_name, "model_trt.pth")assert os.path.exists(trt_file), "TensorRT model is not found!\n Run python3 tools/trt.py first!"model.head.decode_in_inference = Falsedecoder = model.head.decode_outputslogger.info("Using TensorRT to inference")else:trt_file = Nonedecoder = Noneif args.dataset == 'vid':predictor = Predictor(model, exp, VID_classes, trt_file, decoder, args.device, args.legacy)else:predictor = Predictor(model, exp, COCO_CLASSES, trt_file, decoder, args.device, args.legacy)current_time = time.localtime()imageflow_demo(predictor, vis_folder, current_time, args)if __name__ == "__main__":args = make_parser().parse_args()exp = get_exp(args.exp_file, args.name)main(exp, args)
这篇关于视频目标检测 yolov的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








