本文主要是介绍[ADAS预研笔记]感知算法 - 引言及常用数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CNN用于图像分类、目标检测、语义分割等方向;
RNN用于与时序相关的追踪等方向。
现代深度学习算法结构(引言)
在现代深度学习算法研究中, 通用的骨干网络(backbone)+特定任务头(head) 成为一种标准的设计模式。
背景:
- 图像分类算法是其他计算机视觉子任务的基础,目标检测与语义分割都会将问题逐步简化为图像分类问题;
- 因此图像分类的算法主体被迁移过来用作特征提取,称为骨干网络(backbone);
- 原本的图像分类算法也重新进行了划分:全连接层之前的一系列卷积层+池化层即 backbone ,全连接层+softmax即图像分类的 head 。
详细的backbone与head介绍将在下文各类CNN介绍后展开。
常用数据集
模型训练依赖于已经打好标签的数据集作为loss计算的依据以及模型验证,目前主流的开放数据集有如下三类。
ImageNet与ILSVRC
ImageNet:ImageNet是一个超过15 million的图像数据集,大约有22,000类。
ILSVRC:全称ImageNet Large-Scale Visual Recognition Challenge,从2010年开始举办到2017年最后一届,使用ImageNet数据集的一个子集,总共有1000类;
ILSVRC是图像分类领域最具影响力的竞赛,诞生了绝大多数的图像分类算法。
算法研究中常用ILSVRC竞赛数据集来训练模型并验证模型效果,ILSVRC竞赛数据集面向图像分类+目标检测,其输入大小为224*224,深度为3。各年的ILSVRC竞赛所使用的数据集如下:
| 年份 | 图像分类数据集 | 目标检测数据集 |
|---|---|---|
| 2012 | include | not include |
| 2013 | remain 2012 | include |
| 2014 | remain 2012 | more than 2013 |
| 2015 | remain 2012 | remain 2014 |
| 2016 | remain 2012 | remain 2014 |
| 2017 | remain 2012 | remain 2014 |
PASCAL VOC
PASCAL VOC挑战赛主要面向目标检测与语义分割,比赛于2012年停办,但研究者依然可以使用PASCAL VOC数据集训练模型并上传验证结果。
PASCAL VOC数据集输入大小为448*448,主要分为PASCAL VOC 2007和PASCAL VOC2012,两者相互独立;
PASCAL VOC 2007公开了训练集、验证集、测试集;
PASCAL VOC 2012仅公开了训练集、验证集,需提交到官方服务器来评估测试集结果。
训练集用作训练模型;验证集用作自我验证模型效果;测试集用作测试模型效果,不公开可以避免参赛者面向结果编程。
MS COCO
全称为Microsoft Common Objects in Context(MS COCO),面向目标检测、语义分割及其他方向
训练集的不同标注
我们在了解模型时,论文中经常可以看到各种训练集的标注,其含义如下:
- 07+12:使用 VOC2007 的 train+val 和 VOC2012的 train+val 训练,然后使用 VOC2007的test测试;
- 07++12:使用 VOC2007 的 train+val+test 和 VOC2012的 train+val训练,然后使用 VOC2012的test测试;
- 07+12+COCO:先在 MS COCO 的 train+val 上预训练,再使用 VOC2007 的 train+val、 VOC2012的 train+val 微调训练,然后使用 VOC2007的test测试;
- 07++12+COCO:先在 MS COCO 的 train+val 上预训练,再使用 VOC2007 的 train+val+test 、 VOC2012的 train+val 微调训练,然后使用 VOC2012的test测试。
其他语义分割数据集
Cityscapes:50个城市的城市场景语义理解数据集
Stanford Background Dataset:至少有一个前景物体的一组户外场景
Pascal Context:有400多类的室内和室外场景
CamVid:剑桥大学公开发布的城市道路场景的数据集
SUN RGB-D:普灵斯顿大学的 Vision & Robotics Group 公开的一个有关场景理解的数据集
自动驾驶相关数据集
驾驶数据集:
-
DriveSeg:MIT联合丰田公司在2020年6月份发布的,用于动态驾驶场景分割的MIT DriveSeg数据集,并提供完全开放的免费下载。
-
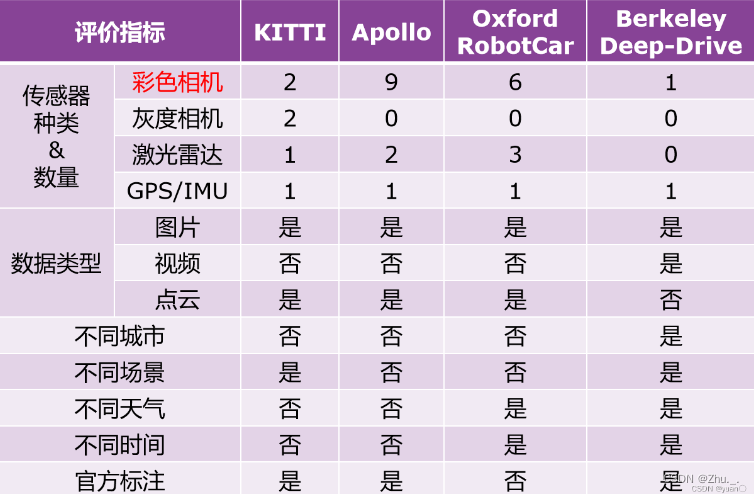
KITTI:目前最知名的自动驾驶数据集之一。
-
CityScapes:50个城市的城市场景语义理解数据集。
-
Mapillary:由瑞典马尔默的Mapillary AB开发,用来分享含有地理标记照片的服务。其创建者想要利用众包的方式来把整个世界(不仅是街道)以照片的形式存储。
-
D²-City:嘀嘀的一个大规模行车视频数据集。
-
ApolloScape:百度的自动驾驶数据集,该数据集包含147k张像素级语义标注图像。
-
Apollo Synthetic Dataset:百度的自动驾驶的合成数据集,场景使用Unity 3D引擎创建。
-
BDD-100k:Berkeley的大规模自动驾驶视频数据集,主要采集于美国城市的一天中的许多不同时间,天气条件和驾驶场景。
-
Oxford RobotCar:牛津大学的项目,数据是对牛津的一部分连续的道路进行了上百次数据采集,收集到了多种天气、行人和交通情况下的数据,也有建筑和道路施工时的数据,长达1000小时以上。
-
nuScenes:由Motional(前身为nuTonomy)团队开发的用于自动驾驶的共有大型数据集。数据集来源于波士顿和新加坡采集的1000个驾驶场景,每个场景选取了20秒长的视频,包括大约140万个图像、39万个激光雷达点云、140万个雷达扫描和4万个关键帧中的140万个对象边界框。
交通标志数据集:
-
KUL Belgium Traffic Sign Dataset:比利时的一个交通标志数据集。
-
German Traffic Sign:德国交通标注数据集。
-
STSD:超过20 000张带有20%标签的图像,包含3488个交通标志。
-
LISA:超过6610帧上的7855条标注。
-
Tsinghua-Tencent 100K:腾讯和清华合作的数据集,100000张图片,包含30000个交通标志实例。
这篇关于[ADAS预研笔记]感知算法 - 引言及常用数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




