本文主要是介绍POSTGRESQL中如何利用SQL语句快速的进行同环比?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 引言
在数据驱动的时代,了解销售、收入或任何业务指标的同比和环比情况对企业决策至关重要。本文将深入介绍如何利用 PostgreSQL 和 SQL 语句快速、准确地进行这两种重要分析。
2. 数据准备
为了演示,假设我们有一张 sales 表,存储了销售数据,包括 date(日期)、product_id(产品ID)、revenue(收入)等字段。首先,确保数据准备工作:
CREATE TABLE sales (date DATE,product_id INT,revenue DECIMAL(10, 2)
);INSERT INTO sales VALUES('2020-01-01', 1, 400),('2020-01-02', 1, 300),('2020-01-01', 2, 3000),('2020-01-02', 2, 3200),('2022-01-01', 1, 500),('2022-01-02', 1, 600),('2022-01-01', 2, 1200),('2022-01-02', 2, 1900),('2023-01-01', 1, 1000),('2023-01-02', 1, 1200),('2023-01-01', 2, 800),('2023-01-02', 2, 900);
插入上述数据后,进行数据查询:
SELECT*
FROMsales
ORDER BYproduct_id,DATE;
查询结果如下:
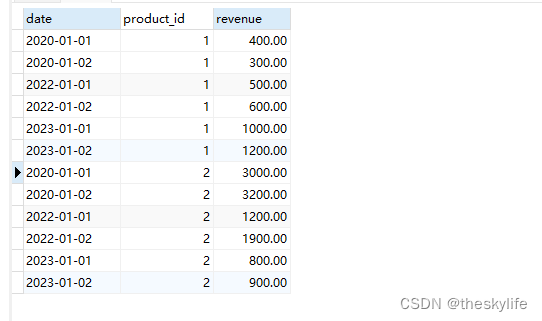
3. 时间序列数据处理
处理时间序列数据是同比和环比分析的关键。确保日期字段以正确的数据类型存储:
ALTER TABLE sales
ALTER COLUMN date SET DATA TYPE DATE;
4. 同比分析
同比分析是比较同一时间段内不同年份数据的变化情况。
4.1 对两年的数据进行对比
比如我们现在想看各年的总收入和平均收入。
SELECTEXTRACT(YEAR FROM date) AS year,sum(revenue) as sum_revenue,count(revenue) as count_revenue,AVG(revenue) AS avg_revenue
FROM sales
GROUP BY year
ORDER BY year;
运行后,结果如下:
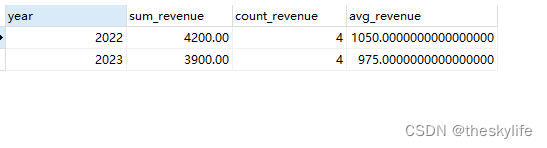
4.2 计算两年的差额和同比
不考虑日期不连续的情况,即销售数据在原始序列中是每年连续的,如数据源中的2022年和2023年收入数据。代码如下:
--计算同比
WITH yearly_revenue AS (SELECTEXTRACT(YEAR FROM date) AS year,sum(revenue) as year_total_revenue,AVG(revenue) AS year_avg_revenueFROM salesWHERE EXTRACT(YEAR FROM date) in (2022,2023)GROUP BY year
)
select
year,
year_total_revenue,
year_avg_revenue,
lag(year_total_revenue) over (partition by null order by year ) as pre_year_total_revenue, --计算去年的收入
COALESCE(year_total_revenue - LAG(year_total_revenue) OVER (ORDER BY year) , 0) AS yoy_growth_value, --计算各年之间的收入差额
COALESCE((year_total_revenue - LAG(year_total_revenue) OVER (ORDER BY year)) / NULLIF(LAG(year_total_revenue) OVER (ORDER BY year), 0) * 100, 0) AS yoy_growth_rate, --计算两年之间的增长比例
lag(year_avg_revenue) over (partition by null order by year ) as pre_year_avg_revenue, --计算去年的平均收入
COALESCE((year_avg_revenue - LAG(year_avg_revenue) OVER (ORDER BY year)) / NULLIF(LAG(year_avg_revenue) OVER (ORDER BY year), 0) * 100, 0) AS yoy_avg_growth_rate --计算平均收入增长比例
from yearly_revenue;
运行上述代码后,可以直接进行计算收入的同比数据,上述代码考虑了去年收入为0和为null的情况,运行后结果如下:

考虑日期不连续的情况,即销售数据在原始序列中是每年连续的,如数据源中的2020年和2022年收入数据。代码如下:
WITH yearly_revenue AS (SELECTEXTRACT(YEAR FROM date) AS year,SUM(revenue) AS year_total_revenue,AVG(revenue) AS year_avg_revenueFROM salesGROUP BY year
)
SELECTcurrent_year.year,current_year.year_total_revenue,previous_year.year_total_revenue AS last_year_total_revenue,previous_year.year_avg_revenue AS last_year_avg_revenue,COALESCE(current_year.year_total_revenue - previous_year.year_total_revenue,0) yoy_growth_value,COALESCE(current_year.year_total_revenue / nullif(previous_year.year_total_revenue,0)-1,0) * 100 yoy_growth_rate
-- ,CASE
-- WHEN previous_year.year_total_revenue IS NOT NULL THEN
-- (current_year.year_total_revenue - previous_year.year_total_revenue) / previous_year.year_total_revenue * 100
-- ELSE
-- NULL
-- END AS year_on_year_growth
FROMyearly_revenue current_year
LEFT JOINyearly_revenue previous_year ON current_year.year = previous_year.year + 1
-- WHERE
-- previous_year.year_total_revenue is not null
ORDER BYcurrent_year.year;
运行代码后,结果如下:
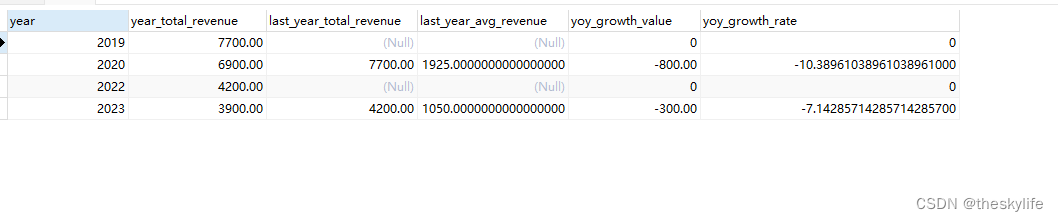
4.3 细分后的同比计算
我们只需要将上述的代码进行简单的修改后,就可以统计细分到任意维度的同比计算。代码如下:
WITH yearly_revenue AS (SELECTEXTRACT(YEAR FROM date) AS year,product_id,SUM(revenue) AS year_total_revenue,AVG(revenue) AS year_avg_revenueFROM salesGROUP BY year,product_id
)
SELECTcurrent_year.year,current_year.product_id,current_year.year_total_revenue,previous_year.year_total_revenue AS last_year_total_revenue,previous_year.year_avg_revenue AS last_year_avg_revenue,COALESCE(current_year.year_total_revenue - previous_year.year_total_revenue,0) yoy_growth_value,COALESCE(current_year.year_total_revenue / NULLIF(previous_year.year_total_revenue, 0) - 1, 0) * 100 yoy_growth_rate
-- ,CASE
-- WHEN previous_year.year_total_revenue IS NOT NULL THEN
-- (current_year.year_total_revenue - previous_year.year_total_revenue) / previous_year.year_total_revenue * 100
-- ELSE
-- NULL
-- END AS year_on_year_growth
FROMyearly_revenue current_year
LEFT JOINyearly_revenue previous_year ON current_year.year = previous_year.year + 1 and current_year.product_id = previous_year.product_id
-- WHERE
-- previous_year.year_total_revenue is not null
ORDER BYcurrent_year.year,current_year.product_id;
运行上述代码后,结果如下:
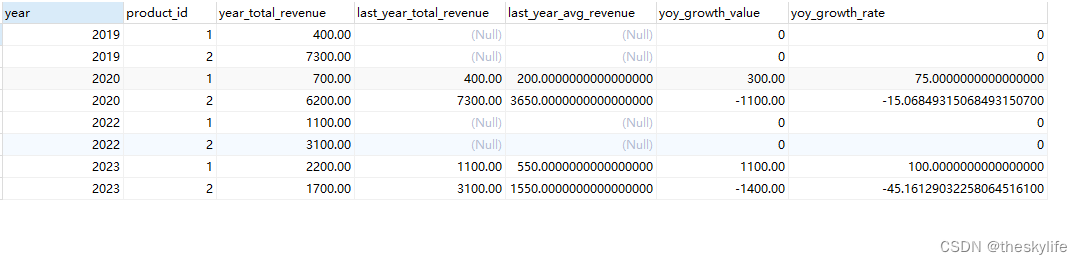
5. 环比分析
环比分析是比较相邻时间段的数据变化情况。
5.1 简单的日期环比计算
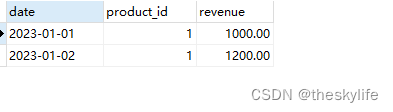
不考虑数据缺失的情况下,如果要对2023年product_id为1的产品进行环比计算,可以使用以下代码进行简单的环比计算:
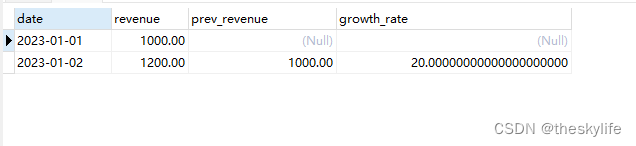
SELECTdate,revenue,LAG(revenue) OVER (ORDER BY date) AS prev_revenue,(revenue - LAG(revenue) OVER (ORDER BY date)) / LAG(revenue) OVER (ORDER BY date) * 100 AS growth_rate
FROM sales
WHEREextract(year from date) in (2023) and product_id in (1);
筛选后的数据:
进行计算后的数据:
5.2 先聚合再进行环比计算
在不考虑日期缺失情况下,如果我们要计算2023年的收入环比,那么我们就需要先按照日期进行聚合,然后再进行环比计算。这里有两种方法,代码如下:
-- 计算写法1
WITH daily_revenue AS (SELECTdate,sum(revenue) as day_total_revenueFROM salesGROUP BY date
)
select
*,
LAG(day_total_revenue) OVER (ORDER BY day_total_revenue) AS prev_revenue,
COALESCE((day_total_revenue - LAG(day_total_revenue) OVER (ORDER BY date)),0) day_growth_value,
COALESCE((day_total_revenue - LAG(day_total_revenue) OVER (ORDER BY date)) / LAG(day_total_revenue) OVER (ORDER BY date) * 100,0) AS day_growth_rate
from daily_revenue
WHERE EXTRACT(YEAR FROM date) in (2023);
#计算写法2
SELECTdate,sum(revenue),LAG(sum(revenue)) OVER (ORDER BY date) AS prev_revenue,COALESCE((sum(revenue) - LAG(sum(revenue)) OVER (ORDER BY date)),0) day_growth_value,COALESCE((sum(revenue) - LAG(sum(revenue)) OVER (ORDER BY date)) / LAG(sum(revenue)) OVER (ORDER BY date) * 100,0) AS growth_rate
FROM sales
WHEREextract(year from date) in (2023)group by date;
无论那个代码都可以,运行后结果如下:

5.3 考虑日期不连续的环比计算
然而在现实统计中,我们的日期往往是不连续的,因此可以考虑下面的思路:
- 1、先按照所需维度进行如何;
- 2、进行日期拼接和计算
代码如下:
-- 1.先聚合到指定维度
WITH daily_revenue AS (SELECT DATE, SUM ( revenue ) AS day_total_revenue FROM sales GROUP BY DATE
)
-- 2.再进行拼接
SELECTcurrent_day.DATE,current_day.day_total_revenue,prev_day.day_total_revenue prev_day_total_revenue,COALESCE ( current_day.day_total_revenue - prev_day.day_total_revenue, 0 ) day_growth_value,COALESCE ( current_day.day_total_revenue / NULLIF ( prev_day.day_total_revenue, 0 ) - 1, 0 ) * 100 day_growth_rate --处理异常情况
FROMdaily_revenue current_dayLEFT JOIN daily_revenue prev_day ON DATE_TRUNC( 'day', current_day.DATE ) = DATE_TRUNC( 'day', prev_day.DATE ) + INTERVAL '1 day'
-- WHERE
-- prev_day.day_total_revenue is not nullORDER BYDATE;
运行后,效果如下:
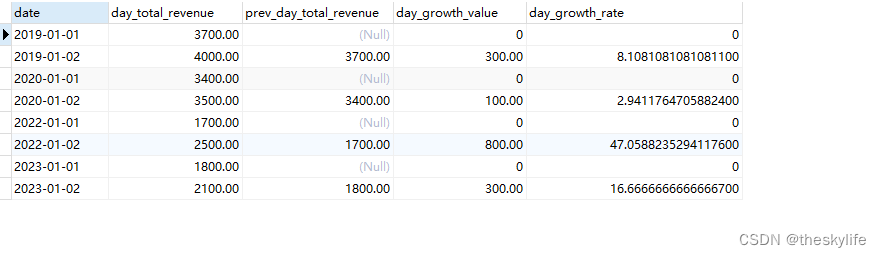
6. 性能优化技巧
数据库性能是关键,特别是在处理大量数据时。
-- 为 date 列创建索引
CREATE INDEX idx_date ON sales (date);
-- 向上方一样,采用视图
WITH daily_revenue AS (SELECT DATE, SUM ( revenue ) AS day_total_revenue FROM sales GROUP BY DATE
) SELECT *
FROMdaily_revenue;
7. 注意事项与常见问题
数据规范性和异常值处理是关键。确保日期格式正确,避免数据异常对分析造成的影响。
8. 结语
本文介绍了在 PostgreSQL 中利用 SQL 进行同比和环比分析的方法。从数据准备到复杂场景下的 SQL 查询,每一步都经过详细解释和示例演示。这些技能不仅能提升数据分析效率,还能为业务决策提供重要支持。利用这些方法,你可以更加准确、快速地分析业务数据,为企业带来更大价值。
希望这篇文章能帮助你更好地利用 SQL 在 PostgreSQL 中进行同比和环比分析!
这篇关于POSTGRESQL中如何利用SQL语句快速的进行同环比?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







