本文主要是介绍大模型的实践应用9-利用LoRA方法在单个GPU上微调FLAN-T5模型的过程讲解与实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用9-利用LoRA方法在单个GPU上微调FLAN-T5模型的过程讲解与实现,文本我们将向您展示如何应用大型语言模型的低秩适应(LoRA)在单个GPU上微调FLAN-T5 XXL(110 亿个参数)模型。我们将利用Transformers、Accelerate和PEFT等第三方库。
1. 设置开发环境
这里我使用已设置好的 CUDA 驱动程序,安装PyTorch深度学习框架,还需要安装 安装 Hugging Face 中的第三方库。
# 安装 Hugging Face 中的第三方库
pip install "peft==0.2.0"
pip install "transformers==4.27.2" "datasets==2.9.0" "accelerate==0.17.1" "evaluate==0.4.0" "bitsandbytes==0.37.1" loralib --upgrade --quiet
# 安装所需的附加依赖项
pip install rouge-score tensorboard py7zr
2. 加载并准备数据集
我们将使用数据集:https://huggingface.co/datasets/samsum。
该数据集包含大约 16k 个带有摘要的对话信息数据。
{"id": "13818513","summary": "Amanda baked cookies and will bring Jerry some tomorrow.","dialogue": "Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I'll bring you tomorrow :-)"
}
要加载samsum数据集,我们使用Datasets 库中的方法load_dataset()。
from datasets import load_dataset# Load dataset from the hub
dataset = load_dataset("samsum")print(f"Train dataset size: {len(dataset['train'])}")
print(f"Test dataset size: {len(dataset['test'])}")
为了训练我们的模型,我们需要将输入(文本)转换为Token ID。这是由Transformers Tokenizer 完成的。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLMmodel_id="google/flan-t5-xxl"# Load tokenizer of FLAN-t5-XL
tokenizer = AutoTokenizer.from_pretrained(model_id)
在开始训练之前,我们需要预处理数据。抽象摘要是一项文本生成任务。我们的模型将采用文本作为输入并生成摘要作为输出。我们想要了解我们的输入和输出需要多长时间才能有效地批处理我们的数据。
from datasets import concatenate_datasets
import numpy as np
# 标记后的最大总输入序列长度。长于此的序列将被截断,短于此的序列将被填充。tokenized_inputs = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["dialogue"], truncation=True), batched=True, remove_columns=["dialogue", "summary"])
input_lenghts = [len(x) for x in tokenized_inputs["input_ids"]]max_source_length = int(np.percentile(input_lenghts, 85))
print(f"Max source length: {max_source_length}")tokenized_targets = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["summary"], truncation=True), batched=True, remove_columns=["dialogue", "summary"])
target_lenghts = [len(x) for x in tokenized_targets["input_ids"]]max_target_length = int(np.percentile(target_lenghts, 90))
print(f"Max target length: {max_target_length}")我们在训练之前预处理数据集并将其保存到磁盘。您可以在本地计算机或 CPU 上运行此步骤并将其上传到Hugging Face Hub。
def preprocess_function(sample,padding="max_length"):# add prefix to the input for t5inputs = ["summarize: " + item for item in sample["dialogue"]]# tokenize inputsmodel_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)# Tokenize targets with the `text_target` keyword argumentlabels = tokenizer(text_target=sample["summary"], max_length=max_target_length, padding=padding, truncation=True)# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore# padding in the loss.if padding == "max_length":labels["input_ids"] = [[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]]model_inputs["labels"] = labels["input_ids"]return model_inputstokenized_dataset = dataset.map(preprocess_function, batched=True, remove_columns=["dialogue", "summary", "id"])
print(f"Keys of tokenized dataset: {list(tokenized_dataset['train'].features)}")# save datasets to disk for later easy loading
tokenized_dataset["train"].save_to_disk("data/train")
tokenized_dataset["test"].save_to_disk("data/eval")
3. 使用 LoRA 和 bnb int-8 微调 T5模型
LoRA 技术在上一节课我已经介绍了,可以看《大模型的实践应用8-利用PEFT和LoRa技术微调大模型(LLM)的原理介绍与指南》这篇文章。
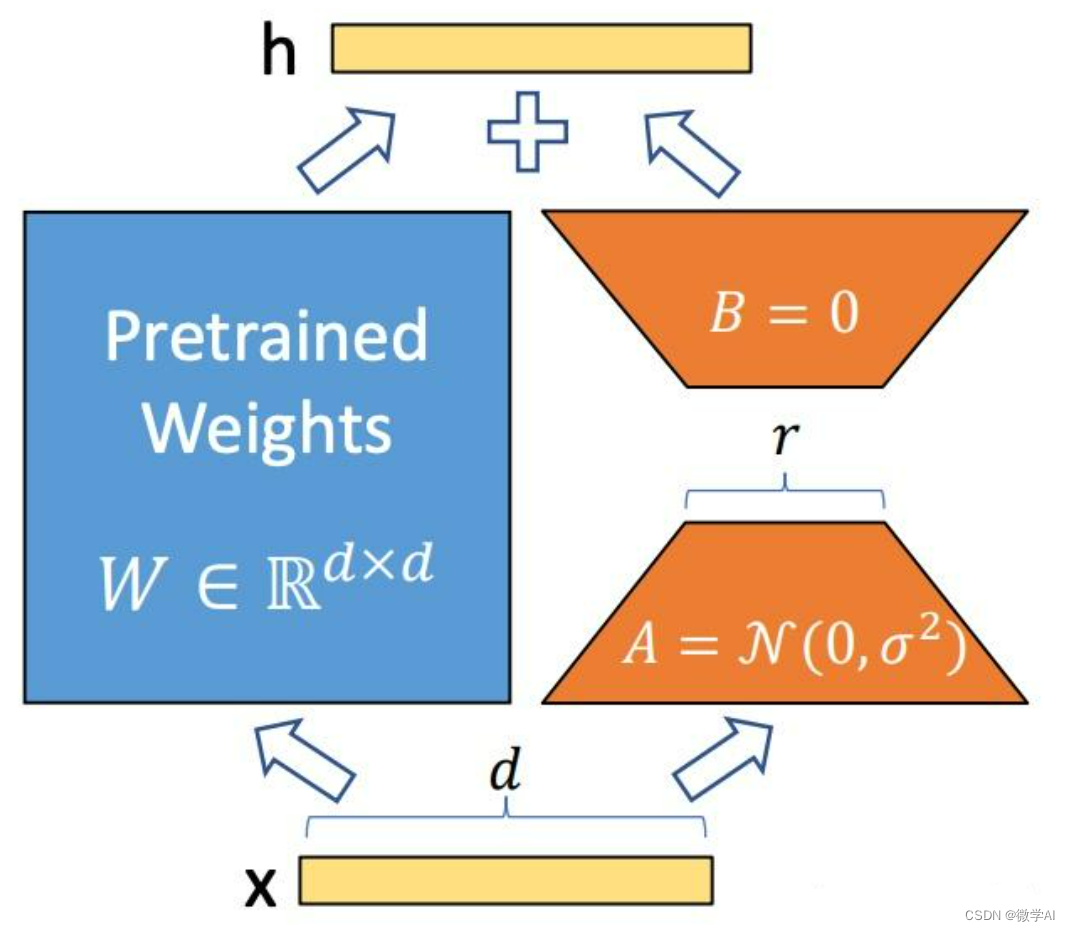
除了 LoRA 技术之外,我们还将使用bitanbytes LLM.int8()将冻结的 LLM 量化为 int8。这使我们能够将 FLAN-T5 XXL 所需的内存减少约 4 倍。
我们训练的第一步是加载模型。我们将使用philschmid/flan-t5-xxl-sharded-fp16 ,它是google/flan-t5-xxl的分片版本。分片将帮助我们在加载模型时不会耗尽内存。
from transformers import AutoModelForSeq2SeqLM
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskTypemodel_id = "philschmid/flan-t5-xxl-sharded-fp16"# 加载模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, load_in_8bit=True, device_map="auto")# 定义 LoRA配置
lora_config = LoraConfig(r=16,lora_alpha=32,target_modules=["q", "v"],lora_dropout=0.05,bias="none",task_type=TaskType.SEQ_2_SEQ_LM
)
# prepare int-8 model for training
model = prepare_model_for_int8_training(model)# add LoRA adaptor
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()trainable params: 18874368 || all params: 11154206720 || trainable%: 0.16921300163961817
正如你所看到的,这里我们只训练了模型参数的0.16%!这种巨大的内存增益将使我们能够在没有内存问题的情况下微调模型。
接下来是创建一个DataCollator负责填充我们的输入和标签的对象。我们将使用Transformers 库中的DataCollatorForSeq2Seq 。
from transformers import DataCollatorForSeq2Seq
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments# we want to ignore tokenizer pad token in the loss
label_pad_token_id = -100
# Data collator
data_collator = DataCollatorForSeq2Seq(tokenizer,model=model,label_pad_token_id=label_pad_token_id,pad_to_multiple_of=8
)output_dir="lora-flan-t5-xxl"# Define training args
training_args = Seq2SeqTrainingArguments(output_dir=output_dir,auto_find_batch_size=True,learning_rate=1e-3, # higher learning ratenum_train_epochs=5,logging_dir=f"{output_dir}/logs",logging_strategy="steps",logging_steps=500,save_strategy="no",report_to="tensorboard",
)# Create Trainer instance
trainer = Seq2SeqTrainer(model=model,args=training_args,data_collator=data_collator,train_dataset=tokenized_dataset["train"],
)
model.config.use_cache = False
现在让我们训练我们的模型并运行下面的代码。对于T5模型,出于稳定性目的保留了一些层float32。
# train model
trainer.train()
我们可以保存模型以用于推理和评估。我们暂时将其保存到磁盘,但你也可以使用该方法将其上传到Hugging Face。
peft_model_id="results"
trainer.model.save_pretrained(peft_model_id)
tokenizer.save_pretrained(peft_model_id)
保存模型以用于推理和评估。我们暂时将其保存到磁盘,但你也可以使用该方法将其上传到Hugging Face。
peft_model_id="results"
trainer.model.save_pretrained(peft_model_id)
tokenizer.save_pretrained(peft_model_id)
最后,我们的 LoRA 检查点只有 84MB大小,他包含了 samsum 的所有学习知识。
这篇关于大模型的实践应用9-利用LoRA方法在单个GPU上微调FLAN-T5模型的过程讲解与实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







