本文主要是介绍基于强化学习的倒立摆平衡控制系统simulink仿真,可以显示三维虚拟模型动画效果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.算法仿真效果
2.MATLAB核心程序
3.算法涉及理论知识概要
4.完整MATLAB
1.算法仿真效果
matlab2022a仿真结果如下:
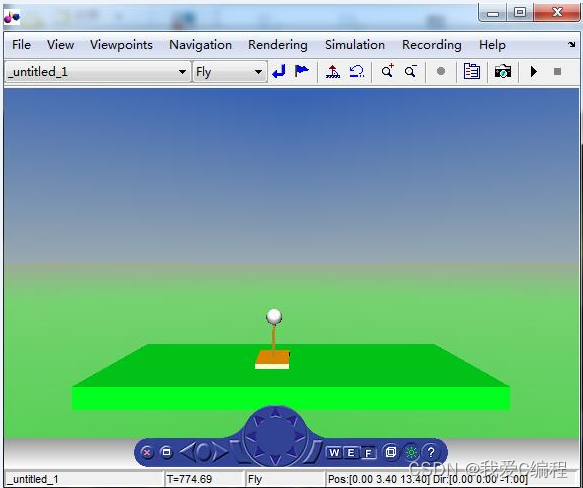
2.MATLAB核心程序

......................................................%从解码器获取状态向量的索引index = decoder(x, x_dot, theta, theta_dot);%初始noise = rand() * 10e-4;y = double(noise < sigmoid(w(index + 1)));%向系统施加力并捕捉其新状态[x, x_dot, theta, theta_dot] = dynamics(y, x, x_dot, theta, theta_dot);e(index+1) = e(index+1) + (1-DELTA) * (y - 0.5); xbar(index + 1) = xbar(index + 1) + (1-LAMBDA);p_t_1 = v(index + 1);%解码器获得状态向量。index = decoder(x, x_dot, theta, theta_dot);if(index < 0)fail_flag = 1; %打开失败标志,以便将状态重置为[0 0 0 0]episode = episode + 1; %增加剧集数量trial = 0; x = 0;x_dot = 0;theta = 0;theta_dot = 0;index = decoder(x, x_dot, theta, theta_dot);%reward -1r = -1;p = 0;elsefail_flag = 0;r = 0;p = v(index + 1);end%Compute the rewardrcap = r + GAMMA * p - p_t_1;%Update the weightsw = w + ALPHA * rcap * e;v = v + BETA * rcap * xbar;for j = 1:num_statesif(v(j) < -1)v(j) = v(j);endendif(fail_flag)e = zeros(162, 1);xbar = zeros(162, 1);elsee = e * DELTA;xbar = xbar * LAMBDA;endtrial = trial + 1;x_ = x;theta_ = theta;e_ = episode;
.............................................................
SpotLight {ambientIntensity 1attenuation 1 0 0beamWidth 1.57color 1 0.942277 0.985569intensity 1location 0 2.5 0radius 102.2
}
DirectionalLight {direction 0 -0.945373 -0.325991
}
Viewpoint {position 0 3.4 13.4
}
DEF Cart Transform {translation 0 0.19 0children [ Shape {appearance Appearance {material Material {ambientIntensity 0.2diffuseColor 0.9 0.55237 0.00733938specularColor 1 1 1}}geometry Box {size 1 0.5 2}}DEF Pendulum Transform {translation 0 0 0children [ Shape {appearance Appearance {material Material {ambientIntensity 0.2diffuseColor 0.53 0.393412 0.100604}}geometry Box {size 0.09 2.8 0.1}}Transform {translation 0 1.5 0children Shape {appearance Appearance {material Material {}}geometry Sphere {radius 0.25}}}]}]
}
..................................................................
A4693.算法涉及理论知识概要
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process, MDP)。按给定条件,强化学习可分为基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL),以及主动强化学习(active RL)和被动强化学习(passive RL)。强化学习的变体包括逆向强化学习、阶层强化学习和部分可观测系统的强化学习。求解强化学习问题所使用的算法可分为策略搜索算法和值函数(value function)算法两类。深度学习模型可以在强化学习中得到使用,形成深度强化学习。
强化学习理论受到行为主义心理学启发,侧重在线学习并试图在探索-利用(exploration-exploitation)间保持平衡。不同于监督学习和非监督学习,强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数。强化学习问题在信息论、博弈论、自动控制等领域有得到讨论,被用于解释有限理性条件下的平衡态、设计推荐系统和机器人交互系统 。一些复杂的强化学习算法在一定程度上具备解决复杂问题的通用智能,可以在围棋和电子游戏中达到人类水平 。
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
强化学习是从动物学习、参数扰动自适应控制等理论发展而来,其基本原理是:
如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。Agent的目标是在每个离散状态发现最优策略以使期望的折扣奖赏和最大。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是Agent对所产生动作的好坏作一种评价(通常为标量信号),而不是告诉Agent如何去产生正确的动作。由于外部环境提供了很少的信息,Agent必须靠自身的经历进行学习。通过这种方式,Agent在行动一一评价的环境中获得知识,改进行动方案以适应环境。
强化学习系统学习的目标是动态地调整参数,以达到强化信号最大。若已知r/A梯度信息,则可直接可以使用监督学习算法。因为强化信号r与Agent产生的动作A没有明确的函数形式描述,所以梯度信息r/A无法得到。因此,在强化学习系统中,需要某种随机单元,使用这种随机单元,Agent在可能动作空间中进行搜索并发现正确的动作。
4.完整MATLAB
V
这篇关于基于强化学习的倒立摆平衡控制系统simulink仿真,可以显示三维虚拟模型动画效果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






