本文主要是介绍【NLP】word2vec处理搜狐新闻文本数据分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
0.前言
1.Word2vec
2.word2vec处理搜狐新闻文本数据分类实验流程
3.word2vec处理搜狐新闻文本数据分类实验
3.1数据读取
3.2数据处理
3.3数据再处理
3.4特征工程
3.5训练模型
4.总结
0.前言
周末匆匆忙忙过去,周一又是新的打工的一周。这周的任务是实现TextCNN文本分类。word2vec作为基础,先简单做一个应用。
在读此文章,做应用之前,建议先了解word2vec到底在做一件什么样的事,之后的代码才方便理解。(我推荐b站上斯坦福的一个NLP的公开课,老师讲的很清楚)当然,你也可能看完了也不是很懂(因为我也是这样的),那就一边实战,一边再转过头去学习理论。
1.Word2vec
首先,你要了解一个东西,叫词嵌入(Embeddings),它是一种将文本词语➡向量(一个词映射到一个向量)的方法。词嵌入主要有三种算法:Embedding Layer、Word2Vec/Doc2Vec、GloVe。
Embedding Layer:Embedding Layer用于神经网络的前端,并采用反向传播算法进行监督。 它就是最简单的one-hot编码,比如,“我爱科研”中的每一个字都可以用一个向量来表示,我➡[1,0,0,0]、爱➡[0,1,0,0]、科➡[0,0,1,0]、研➡[0,0,0,1],这一种词嵌入方法在某种程度上来讲,也是实现了词到向量的转变,但是,我们可以看到,向量和向量之间的相关性是零(两个向量的点积结果表示两个向量之间的相关性)。所以,我们隆重推出另一种词嵌入方法:word2vec。
word2vec:其核心思想就是基于上下文,先用向量代表各个词,然后通过一个预测目标函数学习这些向量的参数。其包含两种算法,分别是skip-gram和CBOW,它们的最大区别是skip-gram是通过中心词去预测中心词周围的词,而CBOW是通过周围的词去预测中心词。Word2Vec只是简单地将一个单词转换为一个向量,而Doc2Vec不仅可以做到这一点,还可以将一个句子或是一个段落中的所有单词汇成一个向量,为了做到这一点,它将一个句子标签视为一个特殊的词,并且在这个特殊的词上做了一些处理,因此,这个特殊的词是一个句子的标签。
GloVe:是Pennington等人开发的用于有效学习词向量的算法,结合了LSA矩阵分解技术的全局统计与word2vec中的基于局部语境学习(这个我没有了解过,也不是本文的重点,这里就简单介绍,大家就自行了解吧)。
2.word2vec处理搜狐新闻文本数据分类实验流程
整个实验流程如下图所示:
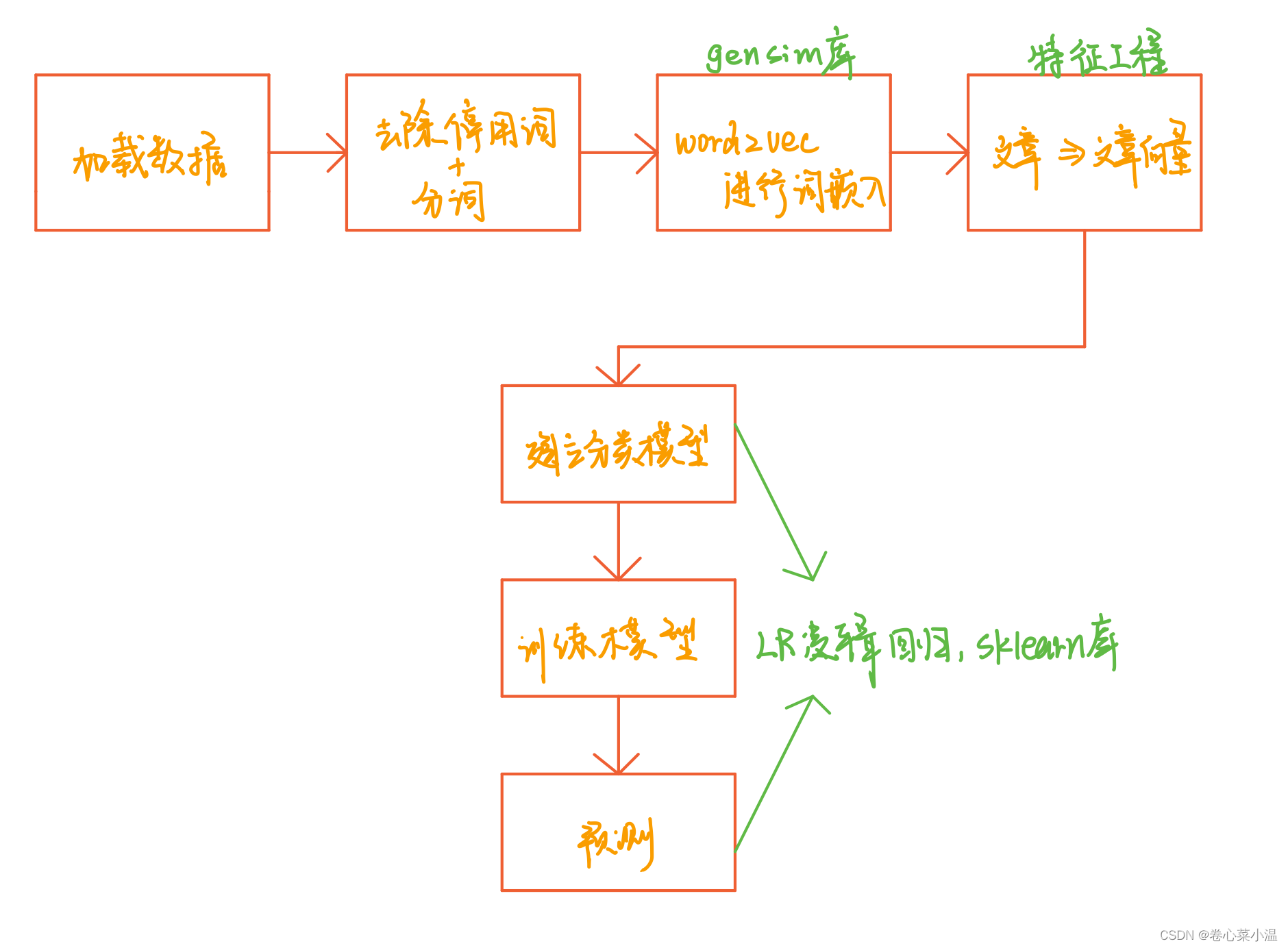
3.word2vec处理搜狐新闻文本数据分类实验
3.1数据读取
我们先准备数据,把数据下载下来,解压到对应的目录下。该文件主要包括一个训练集,一个测试集以及一个停用词库。
链接:https://pan.baidu.com/s/1KdJqic0w6_WwMk4m5F4H1g?pwd=jpqf
内容:训练集共有24000条样本,12个分类,每个分类2000条样本。测试集共有12000条样本,12个分类,每个分类1000条样本。
利用pandas将文件读取出来,并打印出来看看其一些基本信息。
##利用pandas读取数据,并打印前几行
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()可以看到该训练集一共有两列,第一列为类别标签,第二列为文章内容。

##groupby函数可以按标签分类出该标签对应的数据内容
for name, group in train_df.groupby(0):print(name,'\t', len(group)) #len(group)可以获得该类别的文章数据一共有多少条
3.2数据处理
这一步主要做两件事:去除一些无用的停用词+对文章进行分词处理。
##去除无用的停用词
import jieba, time
train_df.columns = ['分类', '文章'] #将数据的第一列定义为分类种类,第二列定义为文章内容
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf-8') if k.strip() != ''] #将停用词放入list##开始分词
cutWords_list = [] #建立一个空列表用于存放已经分好的词
i = 0
startTime = time.time() 3计算该段程序所用时间
遍历样本,将每一篇文章取出来
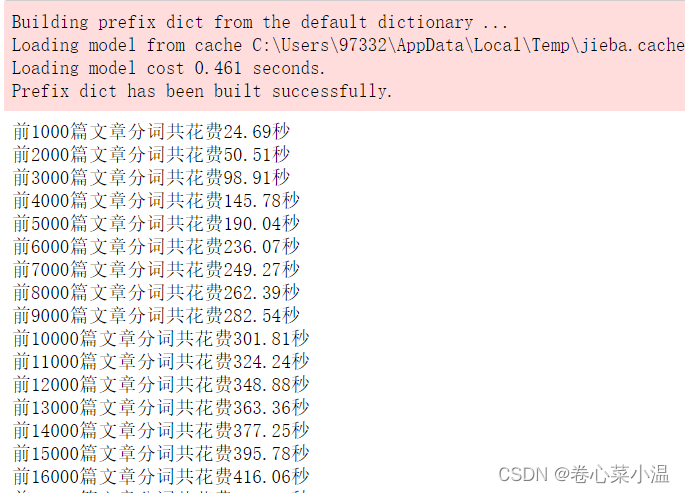
for article in train_df['文章']:cutWords = [k for k in jieba.cut(article) if k not in stopword_list]#判断分词是否为停顿词,如果不为停顿词,则添加进变量cutWord中i += 1if i % 1000 == 0:print('前%d篇文章分词共花费%.2f秒' % (i, time.time() - startTime))cutWords_list.append(cutWords)整个训练集完成分词共花费591.32秒,这里给出训练过程中的部分结果。
然后将分词结果保存为本地文件cutWords_list.txt,这样的好处是当下次使用的时候就可以直接用保存好的文件,不用再去处理一次。
with open('cutWords_list.txt', 'w') as file: for cutWords in cutWords_list:file.write(' '.join(cutWords) + '\n')我们可以把这个文件打开来看看它的分词结果。
with open('cutWords_list.txt') as file:cutWords_list = [ k.split() for k in file ]
print(cutWords_list)可以看到它的分词效果还是挺好的。

3.3数据再处理
这里的数据再处理主要指的是利用word2vec进行词嵌入操作,这个操作主要是依靠gensim包完成的,导入gensim库后,直接调用word2vec函数,训练得到词向量。
这里需要传入的参数:
sentences:需要进行词嵌入的内容;
vector_size:需要转换成词向量的维度;
window:窗口大小,句子中当前单词和预测单词之间的最大距离;
min_count:忽略总频率低于此的所有单词 出现的频率小于min_count不用作词向量。
训练后得到模型word2vec_model。
##为避免warning信息输出,导入warning模块屏蔽warning信息
import warnings
warnings.filterwarnings('ignore')##导入word2vec模块
from gensim.models import Word2Vec
word2vec_model = Word2Vec(sentences=cutWords_list, vector_size=100, window=10, min_count=20)训练好之后,我们利用一些方法来查看词向量的基本信息。
1. 调用word2vec_model模型对象的wv.most_similar方法查看与摄影含义最相近的词。该方法有2个参数,第1个参数是要搜索的词,第2个关键字参数topn数据类型为正整数,是指需要列出多少个最相关的词汇,默认为10,即列出10个最相关的词汇;该方法返回值的数据类型为列表,列表中的每个元素的数据类型为元组,元组有2个元素,第1个元素为相关词汇,第2个元素为相关程度,数据类型为浮点型。
word2vec_model.wv.most_similar('摄影')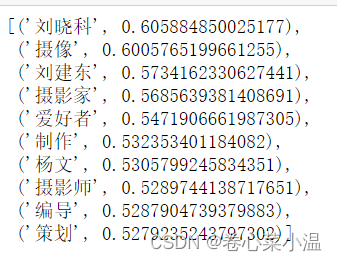
2. 调用word2vec_model模型对象的wv.similarity方法查看两个词之间的相似程度。传入的参数为需要比较的两个词语;返回的值为两个词之间的相似度。
word2vec_model.wv.similarity('摄影', '摄像')
word2vec_model.wv.similarity('男人', '女人')
最后,我们将训练好的模型保存为word2vec_model.w2v,方便下次直接使用而不用再重新训练。
word2vec_model.save('word2vec_model.w2v')3.4特征工程
我已经很久没有做过机器学习这一块的内容了,都快忘了在进行模型训练之前,输入的数据要进行特征工程,而这一步主要是因为考虑到各个样本的长度不一,我们现在有了基于词的word2vec映射数据对应到训练数据,那么以句子或者段输入进网络进行训练应该如何操作。对于每一篇文章,获取文章的每一个分词在word2vec模型都有一个相关性向量。然后把一篇文章的所有分词在word2vec模型中的相关性向量求和取平均数,即此篇文章在word2vec模型中的相关性向量(用一篇文章分词向量的平均数作为该文章在模型中的相关性向量),然后再把文章作为输入传入网络中进行训练。
import time
import numpy as np
import pandas as pddef getVector_v4(cutWords, word2vec_model):i = 0index2word_set = set(word2vec_model.wv.index_to_key) #wv.index_to_key:取出模型中的所有词向量article_vector = np.zeros((word2vec_model.layer1_size)) #先创建一个0矩阵作为文章的向量矩阵##遍历文章中的词,如果已经该词已经在训练好的词向量中,则添加在文章矩阵中,一篇文章之后做均值,返回一篇文章的向量矩阵for cutWord in cutWords:if cutWord in index2word_set:article_vector = np.add(article_vector, word2vec_model.wv[cutWord])i += 1cutWord_vector = np.divide(article_vector, i)return cutWord_vectorstartTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list:i += 1if i % 1000 == 0: print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))vector_list.append( getVector_v4(cutWords, word2vec_model) )X = np.array(vector_list)
print('Total Time You Need To Get X:%.2f秒' % (time.time() - startTime) )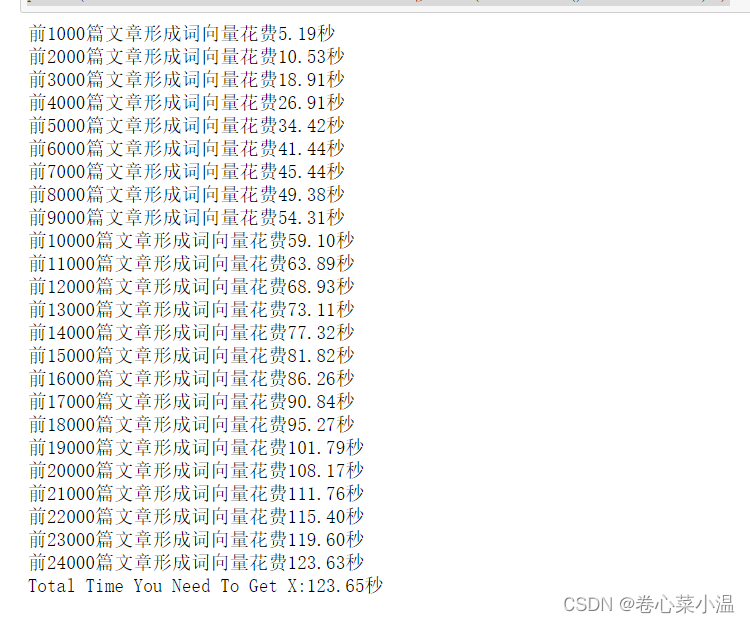 因为形成特征矩阵的花费时间较长,为了避免以后重复花费时间,把特征矩阵保存为文件。使用ndarray对象的dump方法,需要1个参数,为保存文件的文件名;加载则使用np.load方法,输入文件名,直接加载即可。
因为形成特征矩阵的花费时间较长,为了避免以后重复花费时间,把特征矩阵保存为文件。使用ndarray对象的dump方法,需要1个参数,为保存文件的文件名;加载则使用np.load方法,输入文件名,直接加载即可。
#保存矩阵向量
X.dump('articles_vector.txt')
#加载已保存的矩阵向量
X = np.load('articles_vector.txt')3.5训练模型
3.5.1标签编码
对于我们的文本内容,我们进行了数据处理又再处理,使得机器可以读懂这些数据,但是,我们的标签,现在还是一些中文文本,所以,对于标签,我们同样也要进行处理,使得计算机可以读懂。
调用sklearn.preprocessing库的LabelEncoder方法对文章分类做标签编码。
import pandas as pd
from sklearn.preprocessing import LabelEncodertrain_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.columns = ['分类', '文章']
labelEncoder = LabelEncoder() #实例化LabelEncoder()方法
y = labelEncoder.fit_transform(train_df['分类']) #将LabelEncoder方法应用在训练集“分类”一栏3.5.2逻辑回归(LR)模型
逻辑回归模型在sklearn库里都有的,直接调用sklearn.model_selection库的train_test_split方法划分训练集和测试集。调用sklearn.linear_model库的LogisticRegression方法实例化模型对象;使用fit方法对训练集进行训练,使用score方法在测试集得到模型的分数。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splittrain_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=0) #划分训练集以及验证集,其中测试集占比20%,随机数种子为0
logistic_model = LogisticRegression() #实例化LR模型
logistic_model.fit(train_X, train_y) #将LR模型应用在训练集的X(输入)和y(标签)上
logistic_model.score(test_X, test_y) #利用测试集计算模型的分数3.5.3保存模型
对于已经训练好的模型,进行及时的保存,方便下次直接调用。调用joblib方法保存模型为logistic.model文件。
import joblib
joblib.dump(logistic_model, 'logistic.model')3.5.4交叉验证
调用sklearn.model_selection库的ShuffleSplit方法实例化交叉验证对象,调用sklearn.model_selection库的cross_val_score方法获得交叉验证每一次的得分。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score##一共进行5次交叉验证
cv_split = ShuffleSplit(n_splits=5, train_size=0.7, test_size=0.2)
logistic_model = LogisticRegression()
score_ndarray = cross_val_score(logistic_model, X, y, cv=cv_split)
print(score_ndarray)
print(score_ndarray.mean())
3.5.5模型测试
这一步主要是讲测试集的数据按照之前定义的方法进行处理后输入已经训练好的网络,测试模型的训练效果分数。
import pandas as pd
import numpy as np
import joblib
import jieba
##定义一个函数用于处理未处理的文本➡文章向量
def getVectorMatrix(article_series):return np.array([getVector_v4(jieba.cut(k), word2vec_model) for k in article_series])
##载入训练模型
logistic_model = joblib.load('logistic.model')
##载入测试集数据,并将数据分为分类类别以及文章内容
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '文章']
##利用groupby函数取出测试集每个分类以及文章
for name, group in test_df.groupby('分类'):##对于文章,就处理成向量featureMatrix = getVectorMatrix(group['文章'])##对于标签,利用labelEncoder处理为标签target = labelEncoder.transform(group['分类'])print(name, logistic_model.score(featureMatrix, target))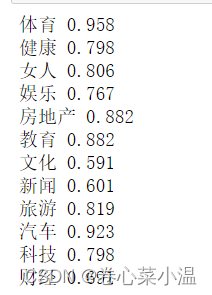
3.5.6模型分数
直接使用sklearn.metrics下的classification_report(),输出此模型的评估报告。
from sklearn.metrics import classification_reporttest_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '文章']
test_label = labelEncoder.transform(test_df['分类'])
y_pred = logistic_model.predict( getVectorMatrix(test_df['文章']) )print(labelEncoder.inverse_transform([[x] for x in range(12)]))
##输出评估报告
print(classification_report(test_label, y_pred))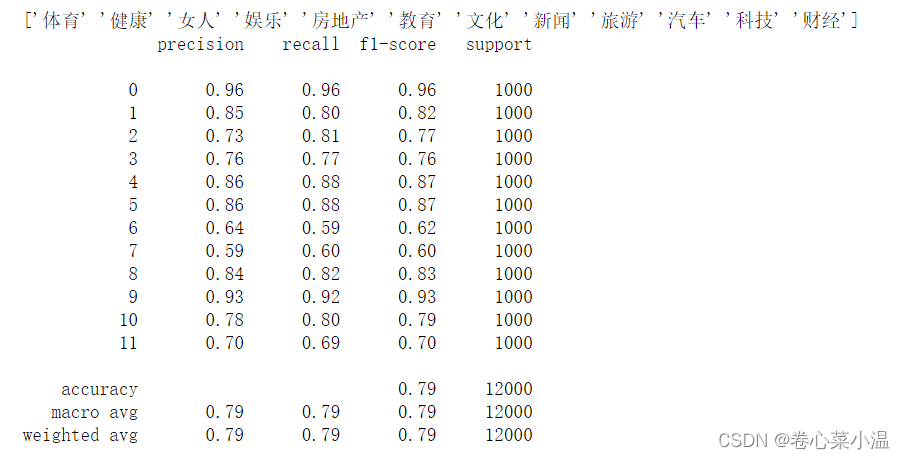
4.总结
做这个应用的初衷是为了学习word2vec的使用,做到这一步原理其实也懂得七七八八了,代码这块,还得再看看,后续再学习一下在深度学习中这一块到底该如何使用。
最后,感谢此文作者提供详细的讲解,该文章是基于此,使用最近的库所写,稍作改动。
利用jieba,word2vec,LR进行搜狐新闻文本分类_weixin_30275415的博客-CSDN博客
这篇关于【NLP】word2vec处理搜狐新闻文本数据分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



