本文主要是介绍打造大数据平台底层计算存储引擎 | Apache孵化器迎来Linkis!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

微众银行开源项目Linkis正式通过Apache软件基金会(ASF)的投票表决,全票通过进入ASF孵化器!
Linkis简介
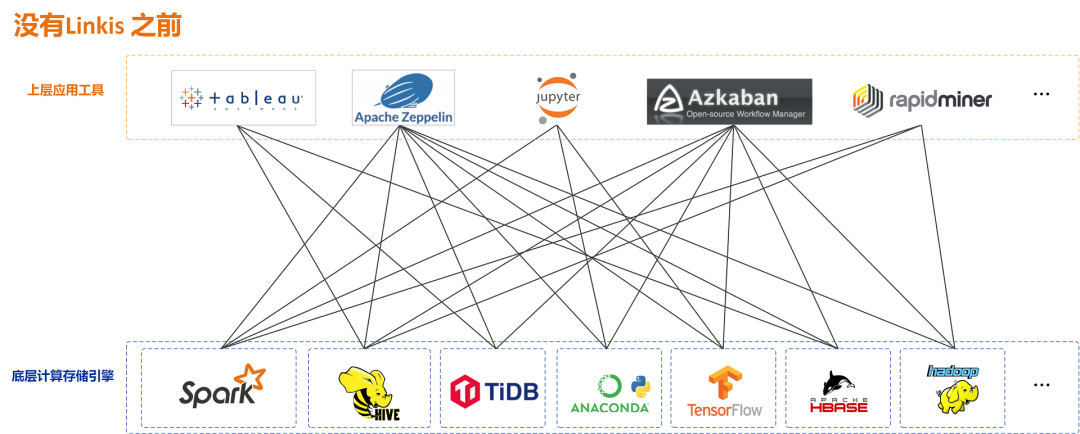
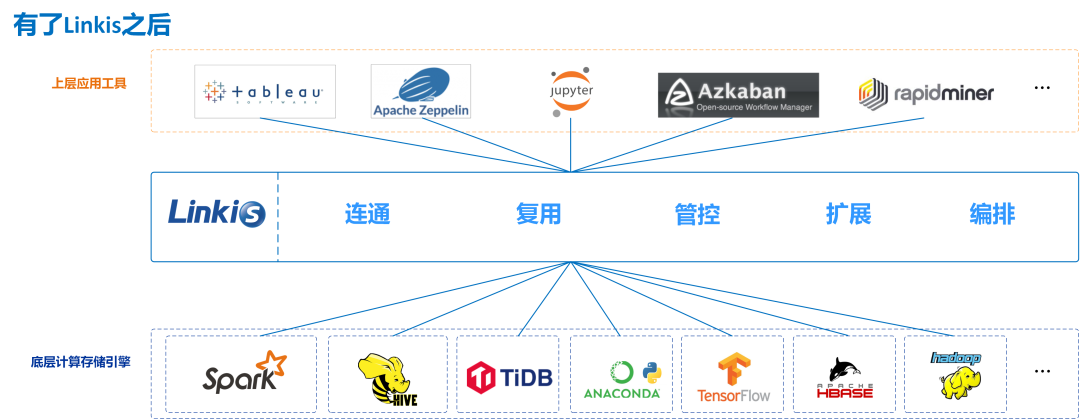
Linkis 在上层应用程序和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问MySQL/Spark /Hive/Presto/ Flink 等底层引擎,同时实现变量、脚本、函数和资源文件等用户资源的跨上层应用互通。
作为计算中间件,Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。通过计算中间件将应用层和引擎层解耦,简化了复杂的网络调用关系,降低了整体复杂度,同时节约了整体开发和维护成本。
Linkis 自2019年开源发布以来,已累计积累了700多家试验企业和1000+沙盒试验用户,涉及金融、电信、制造、互联网等多个行业。许多公司已经将Linkis 作为大数据平台底层计算存储引擎的统一入口,和计算请求/任务的治理管控利器。
核心特点
丰富的底层计算存储引擎支持
目前支持的计算存储引擎:Spark、Hive、Python、Presto、ElasticSearch、MLSQL、TiSpark、JDBC和Shell等。正在支持中的计算存储引擎:Flink、Impala等。支持的脚本语言:SparkSQL, HiveQL, Python, Shell, Pyspark, R, Scala 和JDBC 等。
强大的计算治理能力
基于Orchestrator、Label Manager和定制的Spring Cloud Gateway等服务,Linkis能够提供基于多级标签的跨集群/跨IDC 细粒度路由、负载均衡、多租户、流量控制、资源控制和编排策略(如双活、主备等)支持能力。
全栈计算存储引擎架构支持
能够接收、执行和管理针对各种计算存储引擎的任务和请求,包括离线批量任务、交互式查询任务、实时流式任务和存储型任务;资源管理能力。ResourceManager 不仅具备 Linkis0.X 对 Yarn 和 Linkis EngineManager 的资源管理能力,还将提供基于标签的多级资源分配和回收能力,让 ResourceManager 具备跨集群、跨计算资源类型的强大资源管理能力。
统一上下文服务
为每个计算任务生成context id,跨用户、系统、计算引擎的关联管理用户和系统资源文件(JAR、ZIP、Properties等),结果集,参数变量,函数等,一处设置,处处自动引用;
统一物料
系统和用户级物料管理,可分享和流转,跨用户、系统共享物料。
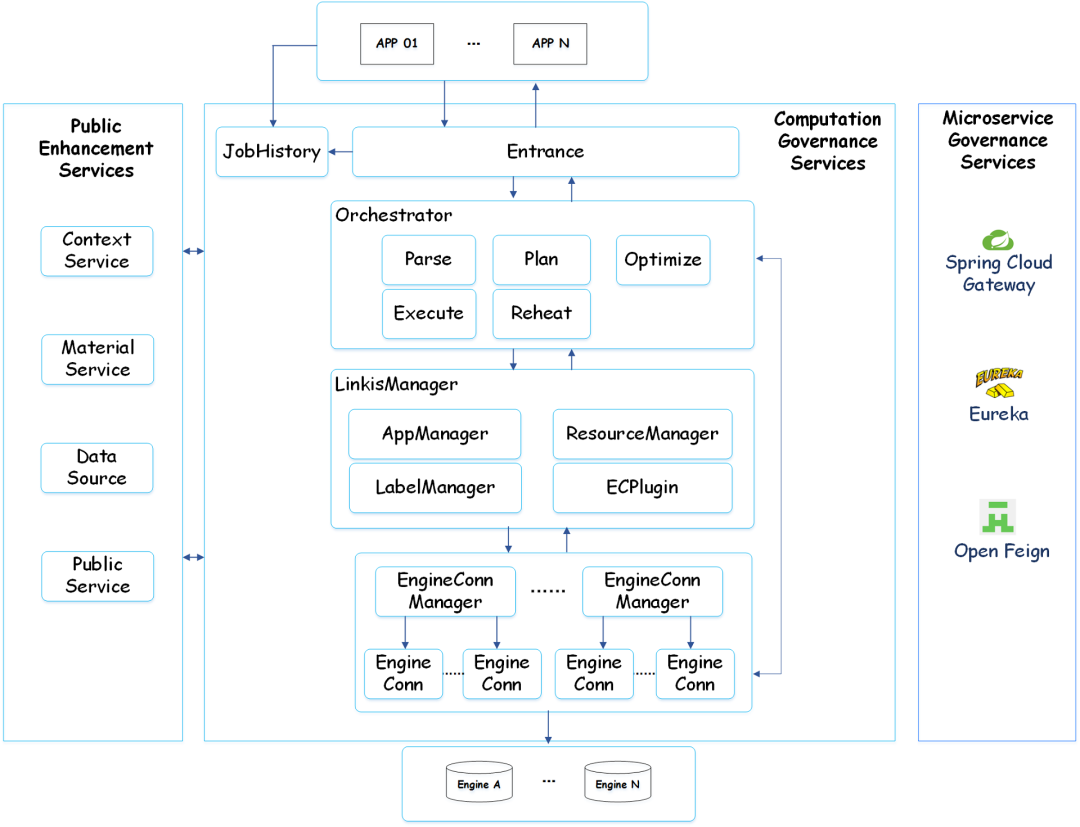
架构概要
Linkis 基于微服务架构开发,其服务可以分为3类:计算治理服务、公共增强服务和微服务治理服务。
计算治理服务,支持计算任务/请求处理流程的3个主要阶段:提交->准备->执行;
公共增强服务,包括上下文服务、物料管理服务及数据源服务等;
微服务治理服务,包括定制化的Spring Cloud Gateway、Eureka、Open Feign。
OK,看到这里你发现什么了没?如果你听说过Zepplin。你可能知道我在说什么,Linkis的出现完全可以替代掉Zepplin,成为做数据平台/中台的利器!
期望Linkis在未来的一段时间内,尽快补齐缺失的部分,比如对Flink最新版本的支持,逐步完善自己的应用生态圈!
地址
仓库地址:https://github.com/WeBankFinTech/Linkis (后续将迁移至Apache组织下,可通过 Linkis 搜索)
邮件列表:
dev@linkis.incubator.apache.org
notification@linkis.incubator.apache.org

八千里路云和月 | 从零到大数据专家学习路径指南
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。
这篇关于打造大数据平台底层计算存储引擎 | Apache孵化器迎来Linkis!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




