本文主要是介绍爬虫-基于selenium模块正则解析实现对斗鱼直播数据抓取并持久化存储,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本次通过selenium插件来实现爬虫,selenium个人感觉还是很不错的,官方文档,其实看文档还是很有用的,这个习惯可以有
首先老规矩分析目标网站
目标网站:斗鱼直播 https://www.douyu.com/directory/all
目标数据:直播间名称,直播间类型,主播名称,房间人数(这个不清楚到底是个啥,反正数值很大)
1,首先做个架子
2,分析目标网站
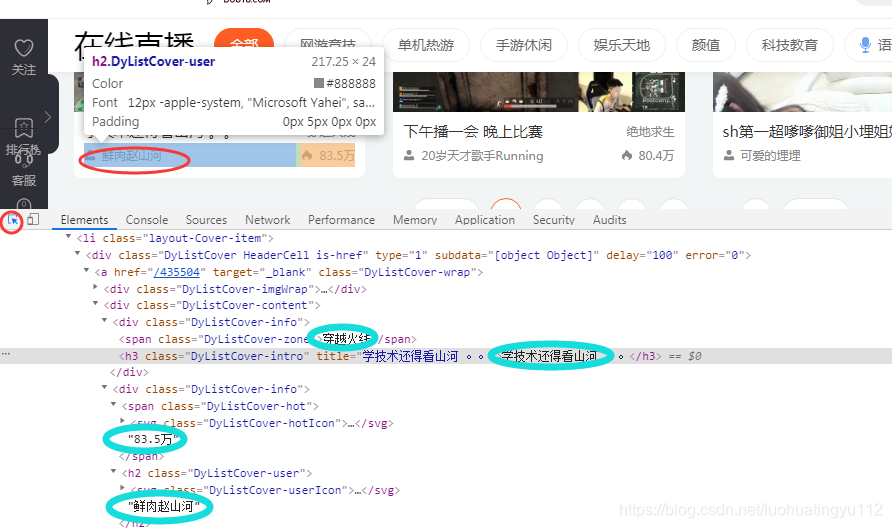
打开开发者模式之后,点击小箭头然后鼠标点击哪里,对应的元素就会高亮,我们先找到目标元素的位置,我这里用的正则去匹配的
其实还有很多的匹配元素的方法呀,基本上我都试过,看个人喜好吧,感兴趣的可以去试一下,这些都不是重点,重点是翻页,斗鱼直播点击下一页的时候它不会跳转的,还有就是你要是一直往下爬的话,你停止的条件时什么,总不能爬取一页吧,这里我们看下网页元素
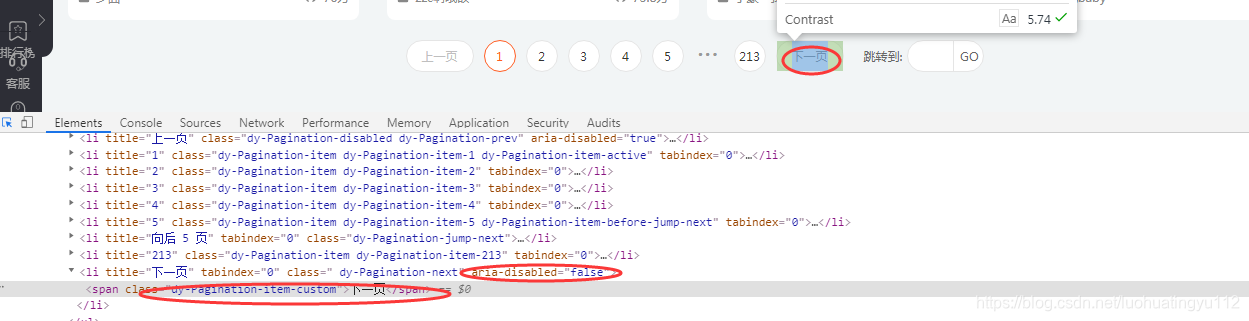
这里可以看到,点击下一页的这个动作,可以由这个span标签的值来执行,我们再去看span上一级 li标签内有个属性的值 是 ‘false’是吧,我翻到最后一页看过,到最后一页还是会有这个span标签,但是这个li 标签内的 false 就变为 true了,我想到这里大家应该明白,这个值可以作为一个来判断是否是最后一页的标准了
(我是这么想的,也是这么做的,有想法的可以去试下…)
这里我们可以总结一下,当 li 标签内的aria-disabled属性的值=false的话,即代表还有下一页,我们可以点击span标签翻页,当aria-disabled属性的值= true 的话,即代表没有 下一页了,暂时先这样理解吧,到底行不行,实践出真知,要善于提出合理性的假设…
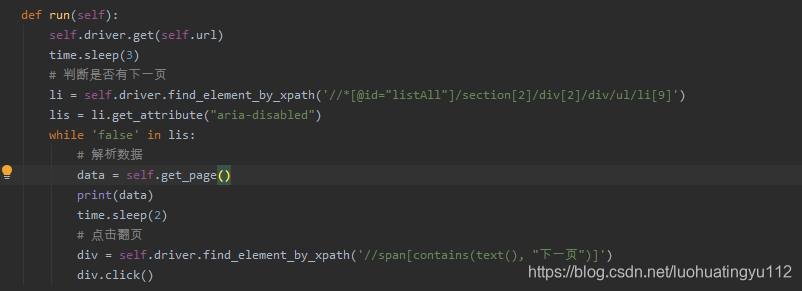
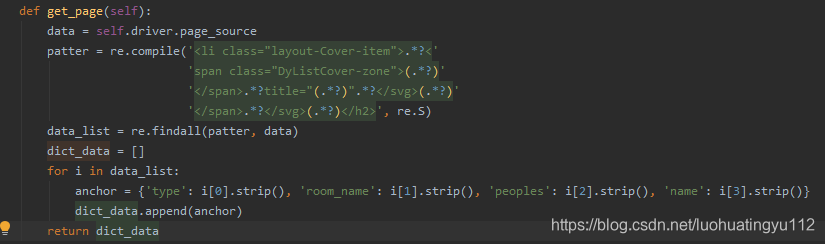
我是先做出判断,后解析数据,这里做判断的时候我是在谷歌上面直接将xpath路径直接复制过来的,将鼠标移至元素位置 右击-copy-copy xpath即可,这样稳妥一点,先上一波源码,其实还可以优化下
from selenium import webdriver
import re
import time
class DouSpider(object):
def __init__(self):self.url = 'https://www.douyu.com/directory/all'self.driver_path = r'E:\DownloadFile\chromedriver.exe'self.driver = webdriver.Chrome(executable_path=self.driver_path)def get_page(self):data = self.driver.page_sourcepatter = re.compile('<li class="layout-Cover-item">.*?<''span class="DyListCover-zone">(.*?)''</span>.*?title="(.*?)".*?</svg>(.*?)''</span>.*?</svg>(.*?)</h2>', re.S)data_list = re.findall(patter, data)dict_data = []for i in data_list:anchor = {'type': i[0].strip(), 'room_name': i[1].strip(), 'peoples': i[2].strip(), 'name': i[3].strip()}dict_data.append(anchor)return dict_datadef next_page(self):passdef save_data(self):passdef run(self):self.driver.get(self.url)time.sleep(3)# 判断是否有下一页li = self.driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/div/ul/li[9]')lis = li.get_attribute("aria-disabled")while 'false' in lis:# 解析数据data = self.get_page()print(data)time.sleep(2)# 点击翻页div = self.driver.find_element_by_xpath('//span[contains(text(), "下一页")]')div.click()
if name == ‘main’:
spider = DouSpider()
spider.run()
结果还是有的,翻到20多页我就停了,后续可以存储到mysql中…
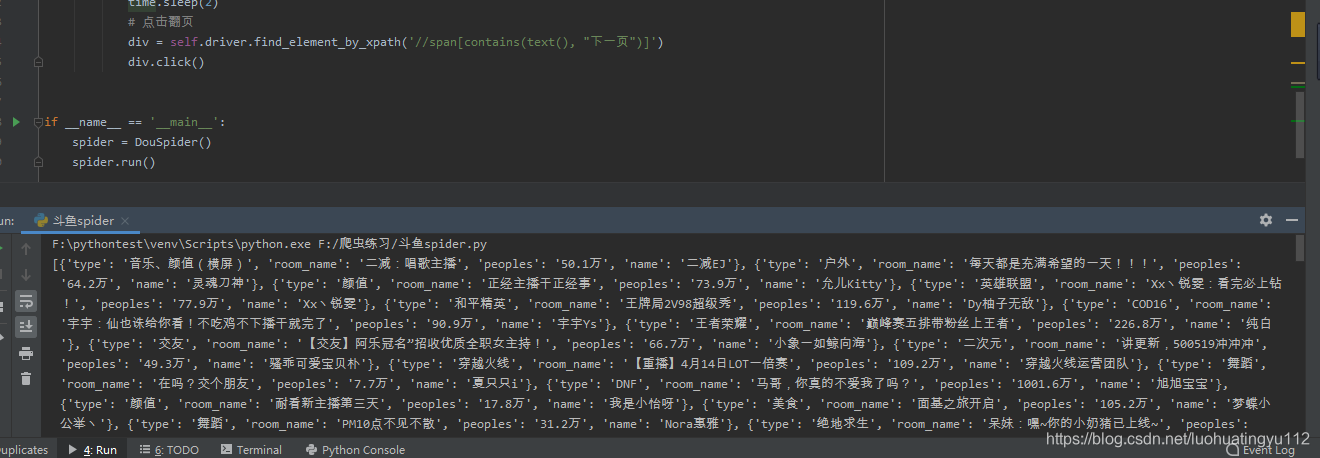
这个代码问题还是有,还有优化空间,整个动图瞅一眼效果咋样,还希望大家留言多多指教…
(这里还需要补充一点,在程序的末尾,我忘记退出浏览器了,应该在 while循环外部 加一个self.driver.quit())

补充完善:
今天优化并补全代码,将抓取到的数据建库存档
首先要先在建立好数据库,这里最好是在数据库里面自己操作比较好,然后在代码里面我们只需要连接就好了,这里代码中添加了一个插入sql语句的函数
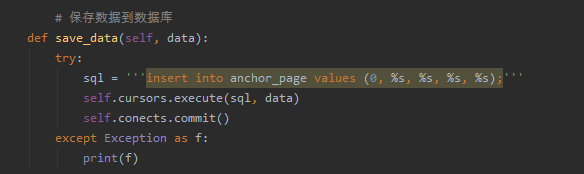
然后在解析函数这里实现调用,解析一行存储一行
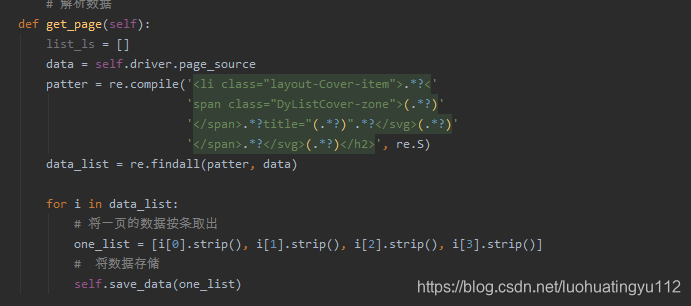
特别注意一点,这里存储的时候很容易报错:1366-Incorrect string value:’\xE6\x9D\x8E\xE5\xAD\xA6…'for column ‘name’ at row 1,我找了很多资料,要把数据库 和表还有字段的编码格式都改成utf8即可,
修改字段编码格式:
alter table anchor_page change 字段 字段 varchar(255) character set utf8;
修改表编码格式:
alter table 表名 default character set utf8;
修改库编码格式:
alter database 库名 character set utf8
代码运行完成之后查看数据库结果

这里还是把修改过的代码放上来
from selenium import webdriver
import re
import time
from pymysql import connect
class DouSpider(object):
def __init__(self):self.url = 'https://www.douyu.com/directory/all'self.driver_path = r'E:\DownloadFile\chromedriver.exe'self.driver = webdriver.Chrome(executable_path=self.driver_path)self.conects = connect(host='localhost', port=3306, user='root', password='19940825', database='test', charset='utf8')self.cursors = self.conects.cursor()# 解析数据
def get_page(self):list_ls = []data = self.driver.page_sourcepatter = re.compile('<li class="layout-Cover-item">.*?<''span class="DyListCover-zone">(.*?)''</span>.*?title="(.*?)".*?</svg>(.*?)''</span>.*?</svg>(.*?)</h2>', re.S)data_list = re.findall(patter, data)for i in data_list:# 将一页的数据按条取出one_list = [i[0].strip(), i[1].strip(), i[2].strip(), i[3].strip()]# 将数据存储self.save_data(one_list)# 判断下一页是否有数据,有则点击下一页
def next_page(self):pass# 保存数据到数据库
def save_data(self, data):try:sql = '''insert into anchor_page values (0, %s, %s, %s, %s);'''self.cursors.execute(sql, data)self.conects.commit()except Exception as f:print(f)def run(self):self.driver.get(self.url)time.sleep(3)# self.create_tables()# 判断是否有下一页li = self.driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/div/ul/li[9]')lis = li.get_attribute("aria-disabled")page = 1while 'false' in lis:# 解析数据self.get_page()# 存储数据print('第 %s 页数据存储成功......' % page)page += 1time.sleep(2)# 点击翻页div = self.driver.find_element_by_xpath('//span[contains(text(), "下一页")]')div.click()self.cursors.close()self.conects.close()self.driver.quit()
if name == ‘main’:
spider = DouSpider()
spider.run()
这篇关于爬虫-基于selenium模块正则解析实现对斗鱼直播数据抓取并持久化存储的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





