本文主要是介绍Llama2通过llama.cpp模型量化 WindowsLinux本地部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Llama2通过llama.cpp模型量化 Windows&Linux本地部署
什么是LLaMA 1 and 2
LLaMA,它是一组基础语言模型,参数范围从7B到65B。在数万亿的tokens上训练的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需求助于专有和不可访问的数据集。特别是,LLaMA-13B在大多数基准测试中都优于GPT-3(175B),并且LLaMA65B与最好的型号Chinchilla-70B和PaLM-540B具有竞争力。
Meta 出品的 Llama 续作 Llama2,一系列模型(7b、13b、70b)均开源可商用。Llama2 在各个榜单上精度全面超过 Llama1,同时也超过此前所有开源模型。
但是对于本机部署大模型,LLaMA要求相对于还是偏高,因此本次使用开源方案llama.cpp进行模型量化,在Windows平台进行CPU量化版本测试,Linux平台进行GPU量化版本测试。
注:以下所有下载步骤均需要科学上网,否则会很折磨。
实验设备详情(供参考)
Windows平台
为笔记本平台,拯救者Y9000P
- CPU: 13th Intel i9-13900HX × \times × 1
- GPU: NVIDIA GeForce RTX4060 (8GB) × \times × 1
- 内存: 32GB
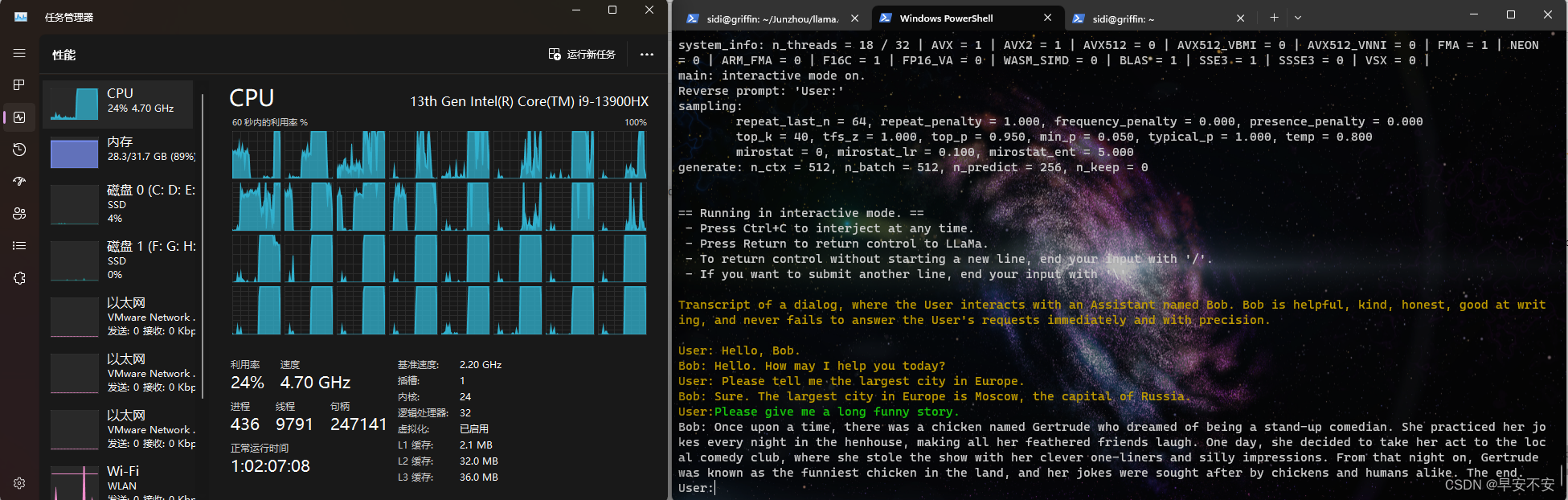
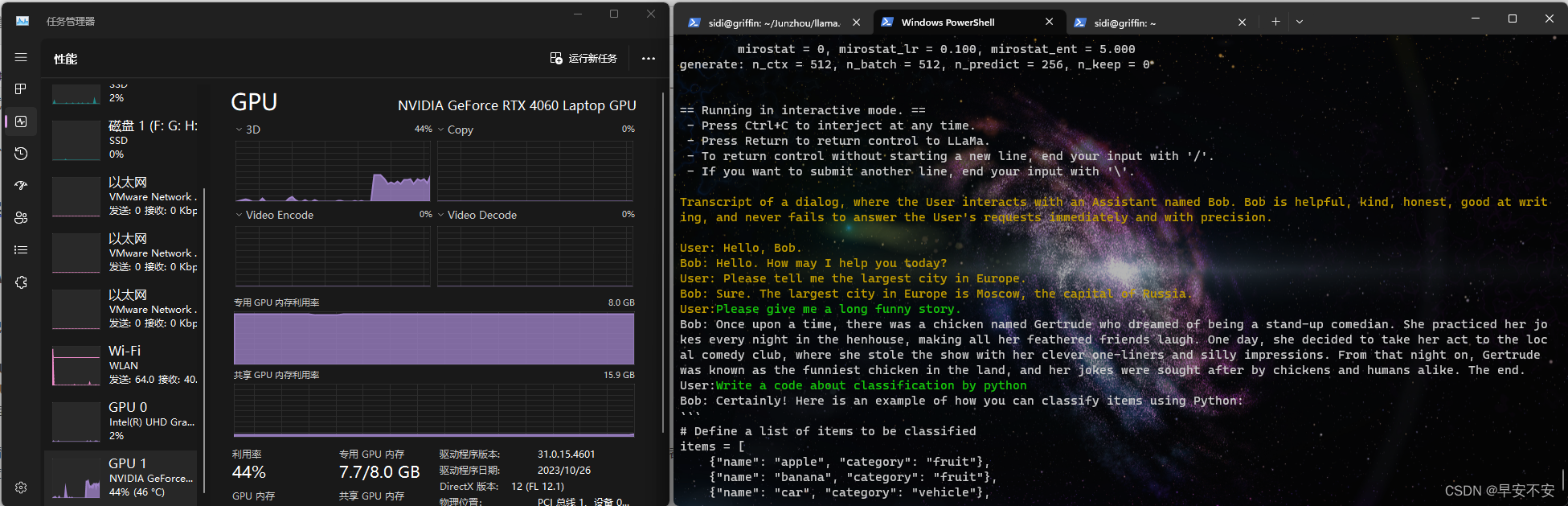
运行情况:CPU流畅运行llama2-13B-chat 8Bit量化版本,卡顿运行16Bit量化版本。GPU版本加速超级快,相当于文心一言或者Chatgpt的生成速度。
运行情况:
Linux平台
实验室服务器
- COU: 9th Intel® Core™ i9-9940X CPU @ 3.30GHz × \times × 14
- GPU: NVIDIA GeForce RTX2080Ti (11GB) × \times × 4
- 内存: 64GB
运行情况:13B和7B都运行十分流程,但70B的不知道为啥突然下载不了了,没法测试。
模型部署详细步骤
下载并配置llama库
-
下载llama
git clone https://github.com/facebookresearch/llama.git -
配置环境
创建虚拟环境,防止之前其他环境安装的包导致的冲突
conda create -n llama python=3.10进入虚拟环境
conda activate llama进入工程目录
cd llama安装环境依赖
pip install -e . -
申请模型下载链接
进入该链接:Mete website申请下载模型,内容如实填写,为了尽快通过,可以填写美国机构和学校,应该会快一些,当时没敢试国内的,怕被拒(被OpenAI搞怕了)
之后会来如下邮件,复制马赛克部分的网址:

-
下载模型
-
Windows平台
sh download.sh -
Linux平台
bash download.sh
之后跟着流程将之前复制的链接粘贴进入即可,然后选择需要下载的模型,关于模型的区别可以自行Bing,chat版本的这里更加推荐,参数量方面7B的一般大部分设备都可以跑,我使用13B版本的也可以正常运行,根据个人所需进行选择。
-
注:Windows平台在下载的时候,可能会面临wget: command not found错误,跟下述链接进行即可
关于在Windows10环境下运行.sh文件报错 wget: command not found的解决办法
-
下载并配置llama.cpp库
-
下载llama.cpp
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp -
编译 Build
-
Linux平台
直接进入工程目录make即可:
make我在autodl服务器和实验室服务器实测都没有问题
-
Windows平台
Windows平台需要安装cmake和gcc,这个我本机此前有安装好,如果有没有安装的请自行百度安装
编译:
mkdir buildcd buildcmake ..cmake --build . --config Release
-
-
CUDA加速版编译,添加一部分指令即可
-
Linux平台
make LLAMA_CUBLAS=1 -
Windows平台
mkdir build cd build cmake .. -DLLAMA_CUBLAS=ON cmake --build . --config Release
-
模型量化
-
准备数据
将llama中下载好的数据 (llama-2-7B-chat) 拷贝到llama.cpp中的./models中,同时将llama主目录中的tokenizer_checklist.chk和tokenizer.model也复制到./models中。
参考以下:
G:. │ .editorconfig │ ggml-vocab-aquila.gguf │ ggml-vocab-baichuan.gguf │ ggml-vocab-falcon.gguf │ ggml-vocab-gpt-neox.gguf │ ggml-vocab-llama.gguf │ ggml-vocab-mpt.gguf │ ggml-vocab-refact.gguf │ ggml-vocab-starcoder.gguf │ tokenizer.model │ tokenizer_checklist.chk │ └─13Bchecklist.chkconsolidated.00.pthconsolidated.01.pthparams.json -
进行量化
进入虚拟环境,安装依赖
cd llama.cppconda activate llama安装依赖
pip install -r requirements.txt进行16Bit转换
python convert.py models/13B/这一步如果报错。修改./models/(模型存放文件夹)/params.json
将最后"vocab_size":中的值改为32000即可-
Linux 4 or 8 bit量化
./quantize ./models/7B/ggml-model-f16.gguf ./models/7B/ggml-model-q4_0.gguf q4_0路径根据自己的路径进行调整,如果进行8bit量化,将命令中的q4_0改为q8_0:
./quantize ./models/7B/ggml-model-f16.gguf ./models/7B/ggml-model-q8_0.gguf q8_08bit肯定比4bit好,但根据设备情况量力而行
-
Windows 4 or 8 bit量化
.\build\bin\Release\quantize.exe .\models\13B\ggml-model-f16.gguf .\models\13B\7B\ggml-model-q4_0.gguf q4_0更改bit也参考上述
-
加载并启动模型
CPU版本
-
Windows平台
.\build\bin\Release\main.exe -m .\models\13B\ggml-model-q4_0.gguf -n 256 -t 18 --repeat_penalty 1.0 --color -i -r "User:" -f .\prompts\chat-with-bob.txt -
Linux平台
./main -m ./models/13B/ggml-model-q8_0.gguf -n 256 -t 18 --repeat_penalty 1.0 --color -i -r "User:" -f .\prompts\chat-with-bob.txt
GPU加速
只需在命令中加上加上-ngl 1
其中可以对数量进行修改,最大为35,我在4060上实测20达到最佳
-
Windows平台
.\build\bin\Release\main.exe -m .\models\13B\ggml-model-q4_0.gguf -n 256 -t 18 --repeat_penalty 1.0 --color -i -r "User:" -f .\prompts\chat-with-bob.txt -ngl 20 -
Linux平台
./main -m ./models/13B/ggml-model-q8_0.gguf -n 256 -t 18 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt -ngl 20
在提示符 > 之后输入你的prompt,cmd/ctrl+c中断输出,多行信息以\作为行尾。如需查看帮助和参数说明,请执行./main -h命令。下面介绍一些常用的参数:
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-ins 启动类ChatGPT对话交流的instruction运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数
具体信息参考:https://github.com/ggerganov/llama.cpp/tree/master/examples/main
这篇关于Llama2通过llama.cpp模型量化 WindowsLinux本地部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







