本文主要是介绍深度之眼AI自媒体联合科赛平台银行客户二分类算法比赛参赛经验分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
比赛简介
近段时间参加了"深度之眼"联合"科赛"推出的银行客户二分类算法比赛,在“深度之眼”指导李老师的视频教学指导下,有幸复现出baseline。这里首先感谢平台和李老师。比赛链接:「二分类算法」提供银行精准营销解决方案。
赛题描述
数据集:选自UCI机器学习库中的「银行营销数据集(Bank Marketing Data Set)」
这些数据与葡萄牙银行机构的营销活动相关。这些营销活动以电话为基础,一般,银行的客服人员需要联系客户至少一次,以此确认客户是否将认购该银行的产品(定期存款)。因此,与该数据集对应的任务是「分类任务」,「分类目标」是预测客户是(' 1 ')或者否(' 0 ')购买该银行的产品,可以看出来是典型的二分类问题。
数据与评测算法
本次评测算法为:AUC(Area Under the Curve) 。关于这个评价指标的介绍网上有很多博客,这里不是本文探讨的重点部分。
训练集简单描述
官方给出train_set.csv和test_set.csv,其中train_set.csv供选手用于训练,test_set.csv供选手用于预测。train_set.csv中包含的每列特征信息如下所示。
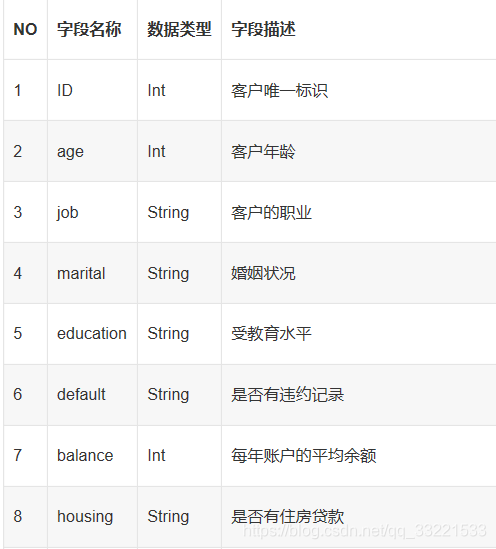
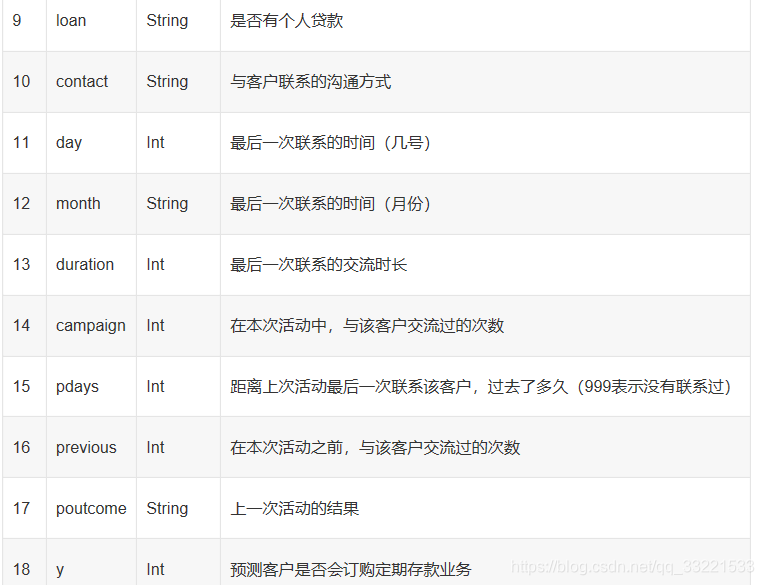
test_set.scv测试集中除了不含有最后需要预测的 'y' 分类这一列,其他所含列信息与train_set.csv类似。训练集一共18个字段,数据的品质很高,没有Nan或脏数据。其中数值型特征有8个,分类型特征有9个,标签为 'y'。
baseline代码
相关模块引入
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
import lightgbm as lgb
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings("ignore")数据读入
#读入数据
dataSet = pd.read_csv("D:\\AI\\game\\2019Kesci二分类算法比赛\\dataSet\\train_set.csv")
testSet = pd.read_csv("D:\\AI\\game\\2019Kesci二分类算法比赛\\dataSet\\test_set.csv")
dataSet.head()
| ID | age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 43 | management | married | tertiary | no | 291 | yes | no | unknown | 9 | may | 150 | 2 | -1 | 0 | unknown | 0 |
| 1 | 2 | 42 | technician | divorced | primary | no | 5076 | yes | no | cellular | 7 | apr | 99 | 1 | 251 | 2 | other | 0 |
| 2 | 3 | 47 | admin. | married | secondary | no | 104 | yes | yes | cellular | 14 | jul | 77 | 2 | -1 | 0 | unknown | 0 |
| 3 | 4 | 28 | management | single | secondary | no | -994 | yes | yes | cellular | 18 | jul | 174 | 2 | -1 | 0 | unknown | 0 |
| 4 | 5 | 42 | technician | divorced | secondary | no | 2974 | yes | no | unknown | 21 | may | 187 | 5 | -1 | 0 | unknown | 0 |
testSet.head()
| ID | age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 25318 | 51 | housemaid | married | unknown | no | 174 | no | no | telephone | 29 | jul | 308 | 3 | -1 | 0 | unknown |
| 1 | 25319 | 32 | management | married | tertiary | no | 6059 | yes | no | cellular | 20 | nov | 110 | 2 | -1 | 0 | unknown |
| 2 | 25320 | 60 | retired | married | primary | no | 0 | no | no | telephone | 30 | jul | 130 | 3 | -1 | 0 | unknown |
| 3 | 25321 | 32 | student | single | tertiary | no | 64 | no | no | cellular | 30 | jun | 598 | 4 | 105 | 5 | failure |
| 4 | 25322 | 41 | housemaid | married | secondary | no | 0 | yes | yes | cellular | 15 | jul | 368 | 4 | -1 | 0 | unknown |
简单查看下数据分布
dataSet.describe()| ID | age | balance | day | duration | campaign | pdays | previous | y | |
|---|---|---|---|---|---|---|---|---|---|
| count | 25317.000000 | 25317.000000 | 25317.000000 | 25317.000000 | 25317.000000 | 25317.000000 | 25317.000000 | 25317.000000 | 25317.000000 |
| mean | 12659.000000 | 40.935379 | 1357.555082 | 15.835289 | 257.732393 | 2.772050 | 40.248766 | 0.591737 | 0.116957 |
| std | 7308.532719 | 10.634289 | 2999.822811 | 8.319480 | 256.975151 | 3.136097 | 100.213541 | 2.568313 | 0.321375 |
| min | 1.000000 | 18.000000 | -8019.000000 | 1.000000 | 0.000000 | 1.000000 | -1.000000 | 0.000000 | 0.000000 |
| 25% | 6330.000000 | 33.000000 | 73.000000 | 8.000000 | 103.000000 | 1.000000 | -1.000000 | 0.000000 | 0.000000 |
| 50% | 12659.000000 | 39.000000 | 448.000000 | 16.000000 | 181.000000 | 2.000000 | -1.000000 | 0.000000 | 0.000000 |
| 75% | 18988.000000 | 48.000000 | 1435.000000 | 21.000000 | 317.000000 | 3.000000 | -1.000000 | 0.000000 | 0.000000 |
| max | 25317.000000 | 95.000000 | 102127.000000 | 31.000000 | 3881.000000 | 55.000000 | 854.000000 | 275.000000 | 1.000000 |
看下String型每列特征值具体有哪些
print(dataSet['job'].unique())['management' 'technician' 'admin.' 'services' 'retired' 'student''blue-collar' 'unknown' 'entrepreneur' 'housemaid' 'self-employed''unemployed']print(dataSet['marital'].unique())['married' 'divorced' 'single']print(dataSet['education'].unique())['tertiary' 'primary' 'secondary' 'unknown']print(dataSet['default'].unique())['no' 'yes']print(dataSet['housing'].unique())['yes' 'no']print(dataSet['loan'].unique())['yes' 'no']print(dataSet['loan'].unique())['no' 'yes']print(dataSet['contact'].unique())['unknown' 'cellular' 'telephone']print(dataSet['month'].unique())['may' 'apr' 'jul' 'jun' 'nov' 'aug' 'jan' 'feb' 'dec' 'oct' 'sep' 'mar']print(dataSet['poutcome'].unique())['unknown' 'other' 'failure' 'success']print(dataSet['y'].unique())[0 1]String类型数据转化
#暂时不构建特征,首先将string类型数据转化成Category类型
for col in dataSet.columns[dataSet.dtypes == 'object']:le = preprocessing.LabelEncoder()le.fit(dataSet[col])dataSet[col] = le.transform(dataSet[col])testSet[col] = le.transform(testSet[col])dataSet.head()
| ID | age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 43 | 4 | 1 | 2 | 0 | 291 | 1 | 0 | 2 | 9 | 8 | 150 | 2 | -1 | 0 | 3 | 0 |
| 1 | 2 | 42 | 9 | 0 | 0 | 0 | 5076 | 1 | 0 | 0 | 7 | 0 | 99 | 1 | 251 | 2 | 1 | 0 |
| 2 | 3 | 47 | 0 | 1 | 1 | 0 | 104 | 1 | 1 | 0 | 14 | 5 | 77 | 2 | -1 | 0 | 3 | 0 |
| 3 | 4 | 28 | 4 | 2 | 1 | 0 | -994 | 1 | 1 | 0 | 18 | 5 | 174 | 2 | -1 | 0 | 3 | 0 |
| 4 | 5 | 42 | 9 | 0 | 1 | 0 | 2974 | 1 | 0 | 2 | 21 | 8 | 187 | 5 | -1 | 0 | 3 | 0 |
可以看出来,所有的String类型特征值已经被转化成相应的数字类别特征值。
数据normalization
scaler = preprocessing.StandardScaler()
scaler.fit(dataSet[['age','balance','duration','campaign','pdays','previous']])
dataSet[['age','balance','duration','campaign','pdays','previous']] = scaler.transform(dataSet[['age','balance','duration','campaign','pdays','previous']])
testSet[['age','balance','duration','campaign','pdays','previous']] = scaler.transform(testSet[['age','balance','duration','campaign','pdays','previous']]dataSet.head()
| ID | age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.194151 | 4 | 1 | 2 | 0 | -0.355546 | 1 | 0 | 2 | 9 | 8 | -0.419241 | -0.246187 | -0.411617 | -0.230404 | 3 | 0 |
| 1 | 2 | 0.100114 | 9 | 0 | 0 | 0 | 1.239579 | 1 | 0 | 0 | 7 | 0 | -0.617708 | -0.565061 | 2.103063 | 0.548333 | 1 | 0 |
| 2 | 3 | 0.570301 | 0 | 1 | 1 | 0 | -0.417885 | 1 | 1 | 0 | 14 | 5 | -0.703321 | -0.246187 | -0.411617 | -0.230404 | 3 | 0 |
| 3 | 4 | -1.216408 | 4 | 2 | 1 | 0 | -0.783913 | 1 | 1 | 0 | 18 | 5 | -0.325845 | -0.246187 | -0.411617 | -0.230404 | 3 | 0 |
| 4 | 5 | 0.100114 | 9 | 0 | 1 | 0 | 0.538857 | 1 | 0 | 2 | 21 | 8 | -0.275255 | 0.710435 | -0.411617 | -0.230404 | 3 | 0 |
可以看出来相应的特征已经被normalization。
构建模型之前预处理
baseline版本暂时没有做深入的特征工程,简单做了下数据预处理之后,使用lightgbm融合xgboost进行建模,具体如下:
dataSet_new = list(set(dataSet.columns) - set(['ID','y']))seed = 42
X_train, X_val, y_train, y_val = train_test_split(dataSet[dataSet_new], dataSet['y'], test_size = 0.2, random_state = seed)train_data = lgb.Dataset(X_train, label = y_train)
val_data = lgb.Dataset(X_val, label = y_val, reference = train_data)建模和参数调节
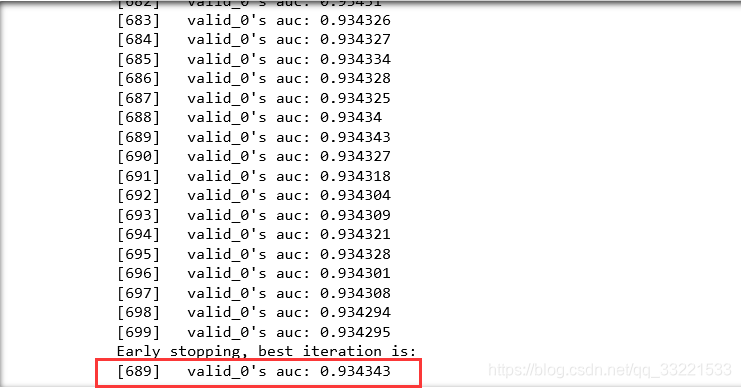
params = {'task': 'train','boosting_type': 'gbdt','objective': 'binary','metric': {'auc'},'verbose': 0,'num_leaves': 30,'learning_rate': 0.01,'is_unbalance': True}model = lgb.train(params,train_data,num_boost_round = 1000,valid_sets = val_data,early_stopping_rounds = 10,categorical_feature = ['job','marital','education','default','housing','loan','contact','poutcome'])训练结果如下,可以看出来,689轮训练之后达到了早停,线上验证集测试auc为:0.934334。
lightgbm模型预测
pred1 = model.predict(testSet[dataSet_new])引入xgboost模型调参
xg_reg = xgb.XGBRegressor(objective = 'reg:linear', colsample_bytree = 0.3, learning_rate = 0.1, max_depth = 8,alpha = 8, n_estimators = 500, reg_lambda = 1)
xg_reg.fit(X_train,y_train)
xgboost模型预测
pred2 = xg_reg.predict(testSet[dataSet_new])生成提交文件
result = pd.DataFrame()
result['ID'] = testSet['ID']
result['pred'] = (pred1 + pred2) / 2
result.to_csv('D:\\AI\\game\\2019Kesci二分类算法比赛\\提交结果\\蜗壳星空_ver1.csv',index=False)查看线上成绩和排名



可以看出来,排名167名,与top1的1.00的成绩还有相当大的差距。本文仅仅是提供一个baseline,并祝愿各位大佬在后面的阶段比赛顺利,取得满意的成绩!!!
这篇关于深度之眼AI自媒体联合科赛平台银行客户二分类算法比赛参赛经验分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





