本文主要是介绍机器学习 jupyter Python 监督学习 KNN算法 海伦约会实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.KNN算法介绍
(1)了判断未知实例的类别,以所有已知类别的实例作为参照。
(2)选择合适的K(参数)值。
(3)计算未知类别到已知类别点的距离,选择最近K个已知实例。
(4)根据少数服从多数的投票法则(majority-voting),让未知类别归类为K个最近邻样本中最多数的类别。
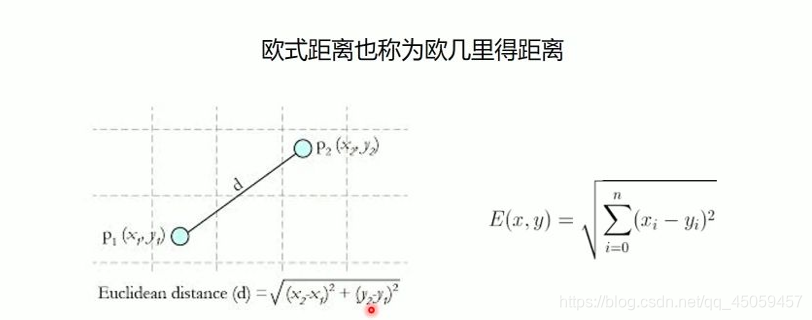
2.简单例子
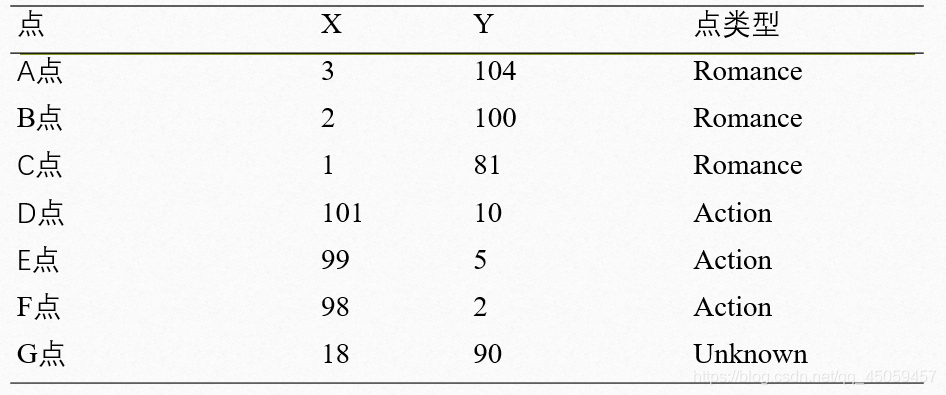
使用KNN算法求G点的类型。
2.1 方法1:自己写的算法
2.1.1 做散点图
import matplotlib.pyplot as plt
import numpy as np
import operator
x1=[3,2,1]
y1=[104,100,81]
x2=[101,99,98]
y2=[10,5,2]
x_test=[18]
y_test=[90]
#画出散点图
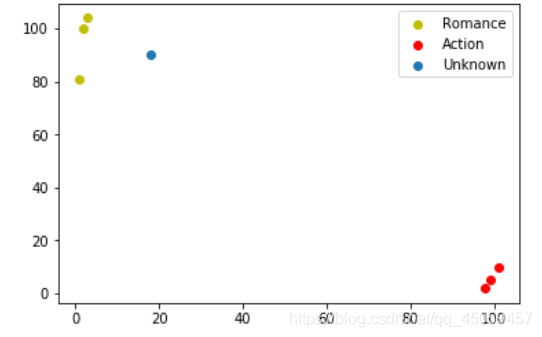
plt.scatter(x1,y1,c='y',label='Romance')
plt.scatter(x2,y2,c='r',label='Action')
plt.scatter(x_test,y_test,label='Unknown')
plt.legend(loc='best')#图例最佳位置
plt.show()
运行结果:
2.1.2 使用KNN算法
2.1.2.1 收集数据
x_data=np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]
])
#print(x_data)
#x_data的行数代表样本点的个数,列数代表特征数
y_data=['Romance','Romance','Romance','Action','Action','Action','Action']
x_test=np.array([18,90])
2.1.2.2 计算未知点到所有已知类别点的距离
#2.KNN算法第二步:计算未知点到所有已知类别点的距离
#2.1复制未知点,复制之前需要知道样本点的个数,才能决定复制几次
#2.1.1求出样本点的长度,shape函数读取矩阵的长度,返回的是一个元组
print(x_data.shape) #结果:(6, 2)dataSetSize=x_data.shape[0]
#np.tile(x_test,(dataSetSize,1)) 1表示在数组里面复制1次,
#tile函数实现数组的复制,tile(a,b) a行数上的复制次数,b列数上的复制次数
diffMat=np.tile(x_test,(dataSetSize,1))-x_data
diffMat
#2.2求平方
sqDiffMat=diffMat**2
print(sqDiffMat)
#2.3求和,sum函数,axis=0 列上求和(默认),axis=1行上求和
sqDistance=sqDiffMat.sum(axis=1)
print(sqDistance)
#2.4开方
distance=np.sqrt(sqDistance)
print(distance)sortedDistance=distance.argsort()
print(sortedDistance)
运行结果:

总结:相减,求平方,相加,开方。
涉及的知识点:
1.tile函数
2.sum函数求和
3.argsort函数
2.1.2.3 找到距离未知点最近的k个点,根据少数服从多数的原则(标签出现的次数),决定类别
#KNN算法第三步:找到距离未知点最近的k个点,根据少数服从多数的原则(标签出现的次数),决定类别
k=5
#不仅需要知道标签,而且需要知道标签出现的次数,key代表标签,value标签出现的次数
dict={}
for i in range(k):votelable=y_data[sortedDistance[i]]#字典里面添加元素dict[key]=value,key:value,get方法,setdefaultdict[votelable]=dict.get(votelable,0)+1#距离测试点最近的k个点的标签
print(dict)
print(dict.items())#转化为列表
sortedDict=sorted(dict.items(),key=operator.itemgetter(1),reverse=True)
print(sortedDict)
sortedDict[0][0]
运行结果:

涉及的知识点:
1.字典添加元素
2.字典转化为列表
2.2.4 总结
优点:
提高自己编程能力。
缺点:
自己写的算法涉及知识点比较多;针对一个未知点进行分类,无法对多个点进行分类。
2.2 方法2:使用sklearn包的KNN算法
2.2.1 导入包
import numpy as np
from sklearn import neighbors#neighbors包含的KNN算法,可以直接调用
2.2.2 收集数据
x_train=np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]])
print(x_train)
y_train=['Romance','Romance','Romance','Action','Action','Action']
x_test=np.array([[18,90]])#必须和训练集的维数一致,针对多个未知点
2.2.3 建模模型
#利用训练集训练样本点
#1.构建模型
model=neighbors.KNeighborsClassifier(n_neighbors=3)#n_neighors代表的是k
#2.训练模型
model.fit(x_train,y_train)
#3.模型训练完之后,做出预测(分类)
prediction=model.predict(x_test)
print(prediction)
运行结果:
[‘Romance’]
2.2.4 总结
注意测试集必须和训练集的维数一致,针对多个未知点。
优点:
算法简单,步骤清晰。
未知点可以为多个,灵活性强。
3.具体案列
3.1 题目 海伦约会实验
根据已经有的数据,推测海伦是否对下一位男生约会。
10%为测试集,90%为训练集。
3.2 部分数据

第一列是里程数,第二列是一周玩游戏的时间,第三列是吃的冰淇淋公斤数,第四列是喜爱程度。
3.3 求解过程
3.3.1 导入数据
import numpy as np
from sklearn import neighbors
from sklearn.model_selection import train_test_split#划分数据,评估模型
from sklearn.metrics import accuracy_score#精度
np.set_printoptions(suppress=True)#显示的数据不是科学计数法
dataSet=np.genfromtxt('datingTestSet.txt',dtype='str')
#x_data是字符串,无法进行计算,所以需要将x_data转化为数值,采用矩阵赋值的办法
x_data=dataSet[:,0:-1]
y_data=dataSet[:,-1]
dataSetnum=len(x_data)
#创建一个空矩阵
dataMat=np.zeros((dataSetnum,3))
#将x_data字符串添加到空矩阵
for i in range(dataSetnum):dataMat[i]=x_data[i]
print(dataMat)
运行结果:

由数据表可以看到,第一列到第三列是数值类型,第四列是字符串类型。在这里采用genfromtxt函数读取文件,输出类型全部为字符串。其次,使用矩阵赋值的办法使得第一列到第三列为数值类型。
从以上的运行结果,可以看到第一列的数值很大,但是在海伦的心目中,三个特征的地位是平等的,但是现在三个特征的权重是不平等的,所以需要进行归一化处理。
3.3.2 进行归一化处理
#归一化处理
# def autoNorm(dataSet):
# minVals=dataSet.min(0)#axis=0,求每个矩阵列的最小值
# maxVals=dataSet.max(0)
# ranges=maxVals-minVals
# m=dataSet.shape[0]#shape求矩阵长度,返回一个元组,原则里面第一个元素是矩阵的行数
# normDataSet=dataSet-np.tile(minVals,(m,1))
# normDataSet=normDataSet/np.tile(ranges,(m,1))
# return normDataSet
# normMat=autoNorm(dataMat)
from sklearn import preprocessing
import numpy as np
np.set_printoptions(suppress=True)#显示的数据不是科学计数法
min_max_scaler=preprocessing.MinMaxScaler()
x_train_minmax=min_max_scaler.fit_transform(x_train)
print(x_train_minmax)
运行结果:

以上提供两种方法进行归一化处理。一是,自己写的算法。二是,sklearn包里面的算法。
3.3.3 划分数据集,建立模型,训练模型,求精度
#建立模型
model=neighbors.KNeighborsClassifier(n_neighbors=3)
#模型评估之前,先划分数据集,分为训练集以及测试集
#sklearn里面划分数据
x_train,x_test,y_train,y_test=train_test_split(normMat,y_data,test_size=0.1)
#10%作为测试集。90%作为训练集
#模型训练
model.fit(x_train,y_train)
#进行预测
predictions=model.predict(x_test)
#求精度,模型评估
s=accuracy_score(y_test,predictions)
print(s)
#模型评估完之后,发现精度(准确度,对/总=精度),模型比较好的
#解决的问题,改善约会网站的配对效果,下次约会,
#海伦只需要知道(里程数,玩游戏的时间,冰淇淋),就知道喜欢还是不喜欢
运行结果:

由于训练集合测试集是随机分配的,所以精度不是每次都一样,但是精度总是保持在90%,总的来说模型建立成功。
这篇关于机器学习 jupyter Python 监督学习 KNN算法 海伦约会实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






