本文主要是介绍集成学习task03-偏差、方差理论、特征提取和模型超参数调优,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、训练均方误差与测试均方误差
均方误差: M S E = 1 N ∑ i = 1 N ( y i − f ^ ( x i ) ) 2 MSE = \frac{1}{N}\sum\limits_{i=1}^{N}(y_i -\hat{ f}(x_i))^2 MSE=N1i=1∑N(yi−f^(xi))2,其中 f ^ ( x i ) \hat{ f}(x_i) f^(xi)是样本 x i x_i xi应用建立的模型 f ^ \hat{f} f^预测的结果。
训练误差与测试误差的关系: 训练均方误差不断降低,测试均方误差一般会先降低后升高。一个模型的训练均方误差最小时,不能保证测试均方误差同时也很小。(具体解释见偏差与方差的权衡)。
重点: 训练均方误差最小,并不能使得测试均方误差最小!
二、偏差与方差的权衡
偏差是指: 为了选择一个简单的模型去估计真实函数所带入的误差。偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
方差: 度量的是同一个模型在不同数据集上的稳定性。
测试误差曲线一般先降低后升高,说明测试误差曲线中有两种力量在互相博弈。可以证明:
E ( y 0 − f ^ ( x 0 ) ) 2 = Var ( f ^ ( x 0 ) ) + [ Bias ( f ^ ( x 0 ) ) ] 2 + Var ( ε ) E\left(y_{0}-\hat{f}\left(x_{0}\right)\right)^{2}=\operatorname{Var}\left(\hat{f}\left(x_{0}\right)\right)+\left[\operatorname{Bias}\left(\hat{f}\left(x_{0}\right)\right)\right]^{2}+\operatorname{Var}(\varepsilon) E(y0−f^(x0))2=Var(f^(x0))+[Bias(f^(x0))]2+Var(ε)
也就是说,我们的测试均方误差的期望值可以分解为 f ^ ( x 0 ) \hat{f}(x_0) f^(x0)的方差、 f ^ ( x 0 ) \hat{f}(x_0) f^(x0)的偏差平方和误差项 ϵ \epsilon ϵ的方差。 Var ( ε ) \operatorname{Var}(\varepsilon) Var(ε)为建模任务的难度,这个量在我们的任务确定后是无法改变的,也叫做不可约误差。
偏差与方差的关系:
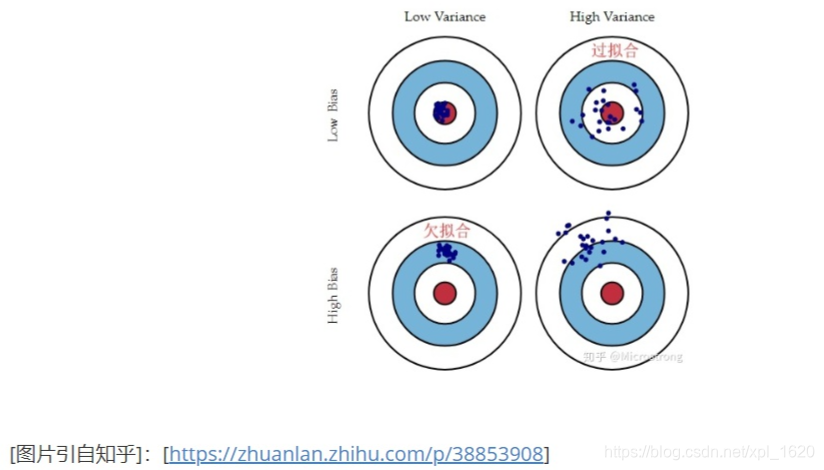
一般而言,增加模型的复杂度,会减少模型的偏差,但是会增加模型的方差,我们要找到一个方差–偏差的权衡,使得测试均方误差最小,因此需要对测试均方误差进行估计。
三、测试误差估计
为什么要进行测试均方误差估计?
由上所知,我们要选择的是测试误差最小的模型。因为训练误差最小时,测试均方误差结果往往更大,且很难很难对实际的测试误差进行精确的计算,故需要对测试均方误差进行估计。测试均方误差估计的两种方法:直接估计、间接估计。
3.1间接估计-训练误差修正:
由上所知,模型越复杂,训练误差越小,测试误差先减后增。因此,我们先构造一个特征较多的模型使其过拟合,此时训练误差很小而测试误差很大,那这时我们加入关于特征个数的惩罚。因此,当我们的训练误差随着特征个数的增加而减少时,惩罚项因为特征数量的增加而增大,抑制了训练误差随着特征个数的增加而无休止地减小(通过牺牲偏差,来降低方差)。具体的数学量如下:
C p = 1 N ( R S S + 2 d σ ^ 2 ) C_p = \frac{1}{N}(RSS + 2d\hat{\sigma}^2) Cp=N1(RSS+2dσ^2),
其中d为模型特征个数, R S S = ∑ i = 1 N ( y i − f ^ ( x i ) ) 2 RSS = \sum\limits_{i=1}^{N}(y_i-\hat{f}(x_i))^2 RSS=i=1∑N(yi−f^(xi))2, R S S RSS RSS为残差平方和。 σ ^ 2 \hat{\sigma}^2 σ^2为模型预测误差的方差的估计值,即残差的方差。
AIC赤池信息量准则: A I C = 1 d σ ^ 2 ( R S S + 2 d σ ^ 2 ) AIC = \frac{1}{d\hat{\sigma}^2}(RSS + 2d\hat{\sigma}^2) AIC=dσ^21(RSS+2dσ^2)
BIC贝叶斯信息量准则: B I C = 1 n ( R S S + l o g ( n ) d σ ^ 2 ) BIC = \frac{1}{n}(RSS + log(n)d\hat{\sigma}^2) BIC=n1(RSS+log(n)dσ^2)
如何通过训练误差估计测试误差?
特征个数增加会使得训练误差降低,通过对特征个数进行惩罚,抑制训练误差随着特征个数的增加而无休止地减小 ,从而确保测试误差处于相对较低的位置。
3.2直接估计-交叉验证
K折交叉验证:
交叉验证是对测试误差的直接估计。交叉验证比训练误差修正的优势在于:能够给出测试误差的一个直接估计。在这里只介绍K折交叉验证:我们把训练样本分成K等分,然后用K-1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精度,这个过程重复K次取平均值得到测试误差的一个估计 C V ( K ) = 1 K ∑ i = 1 K M S E i CV_{(K)} = \frac{1}{K}\sum\limits_{i=1}^{K}MSE_i CV(K)=K1i=1∑KMSEi。
KFord函数原理的官网介绍图如下: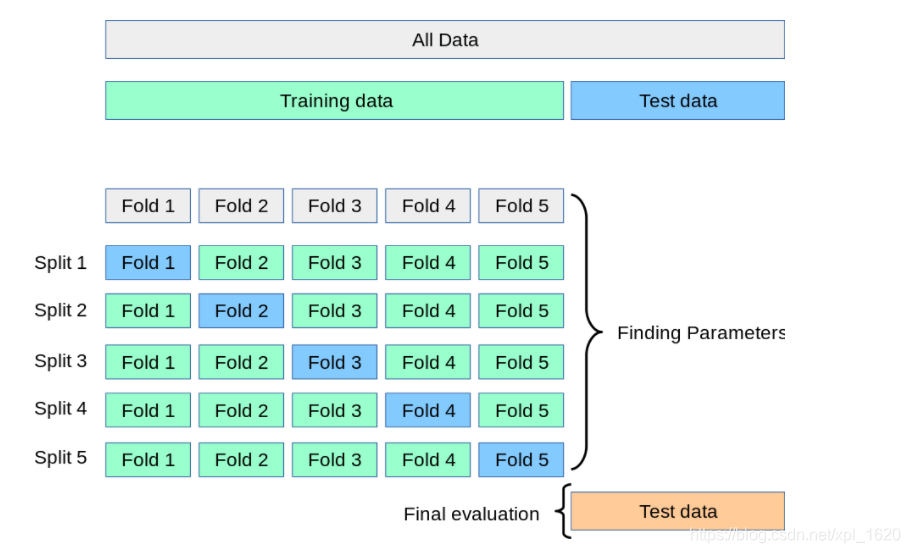
KFord函数示例如下:
import numpy as np
from sklearn.model_selection import KFoldX = np.random.randint(1,100,20).reshape((10,2)) #准备数据#K折交叉验证
'''
函数使用:
classsklearn.model_selection.KFold(n_splits=5,*,shuffle=False,random_state=None)
n_splits:表示要分割K个子集,默认为5
shuffle:是否要打乱数据,默认false
random_state:随机状态,需要和shuffle结合使用
'''
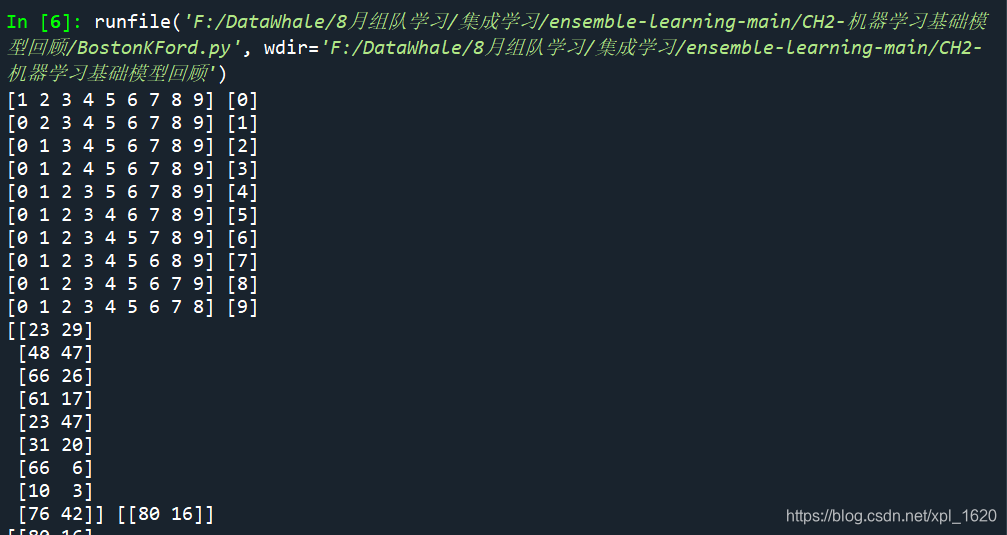
kf = KFold(n_splits=10) #将训练集分成10份for train_index,valid_index in kf.split(X): print(train_index,valid_index) #输出10折划分数据集和训练集的索引for train_index,valid_index in kf.split(X): print(X[train_index],X[valid_index]) #输出10折划分数据值
四、特征提取
在测试误差能够被合理的估计出来以后,我们做特征选择的目标就是:从p个特征中选择m个特征,使得对应的模型的测试误差的估计最小。对应的方法有:
4.1 最优子集选择:
(i) 记不含任何特征的模型为 M 0 M_0 M0,计算这个 M 0 M_0 M0的测试误差。
(ii) 在 M 0 M_0 M0基础上增加一个变量,计算p个模型的RSS,选择RSS最小的模型记作 M 1 M_1 M1,并计算该模型 M 1 M_1 M1的测试误差。
(iii) 再增加变量,计算p*p-1个模型的RSS,并选择RSS最小的模型记作 M 2 M_2 M2,并计算该模型 M 2 M_2 M2的测试误差。
(iv) 重复以上过程知道拟合的模型有p个特征为止,并选择p+1个模型 { M 0 , M 1 , . . . , M p } \{M_0,M_1,...,M_p \} {M0,M1,...,Mp}中测试误差最小的模型作为最优模型。
4.2 向前逐步选择:
最优子集选择虽然在原理上很直观,但是随着数据特征维度p的增加,子集的数量为 2 p 2^p 2p,计算效率非常低下且需要的计算内存也很高,在大数据的背景下显然不适用。因此,我们需要把最优子集选择的运算效率提高,因此使用向前逐步选择算法的过程如下:
(i) 记不含任何特征的模型为 M 0 M_0 M0,计算这个 M 0 M_0 M0的测试误差。
(ii) 在 M 0 M_0 M0基础上增加一个变量,计算p个模型的RSS,选择RSS最小的模型记作 M 1 M_1 M1,并计算该模型 M 1 M_1 M1的测试误差。(iii) 在最小的RSS模型下继续增加一个变量,选择RSS最小的模型记作 M 2 M_2 M2,并计算该模型 M 2 M_2 M2的测试误差。
(iv) 以此类推,重复以上过程知道拟合的模型有p个特征为止,并选择p+1个模型 { M 0 , M 1 , . . . , M p } \{M_0,M_1,...,M_p \} {M0,M1,...,Mp}中测试误差最小的模型作为最优模型。
代码:
import pandas as pd
from sklearn import datasets #加载线性回归需要的模块和库
from statsmodels.formula.api import ols #加载ols(最小二乘法)模型,主要用于线性回归的参数估计boston = datasets.load_boston() #导入boston数据集
X = boston.data
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y#定义向前逐步回归函数
def forward_select(data,target):variate=set(data.columns) #将字段名转换成字典类型variate.remove(target) #去掉因变量的字段名selected=[]current_score,best_new_score=float('inf'),float('inf') #目前的分数和最好分数初始值都为无穷大(因为AIC越小越好)#循环筛选变量while variate:aic_with_variate=[]for candidate in variate: #逐个遍历自变量formula="{}~{}".format(target,"+".join(selected+[candidate])) #将自变量名连接起来aic=ols(formula=formula,data=data).fit().aic #利用ols训练模型得出aic值aic_with_variate.append((aic,candidate)) #将第每一次的aic值放进空列表aic_with_variate.sort(reverse=True) #降序排序aic值best_new_score,best_candidate=aic_with_variate.pop() #最好的aic值等于删除列表的最后一个值,以及最好的自变量等于列表最后一个自变量if current_score>best_new_score: #如果目前的aic值大于最好的aic值variate.remove(best_candidate) #移除加进来的变量名,即第二次循环时,不考虑此自变量了selected.append(best_candidate) #将此自变量作为加进模型中的自变量current_score=best_new_score #最新的分数等于最好的分数print("aic is {},continuing!".format(current_score)) #输出最小的aic值else:print("for selection over!")breakformula="{}~{}".format(target,"+".join(selected)) #最终的模型式子print("final formula is {}".format(formula))model=ols(formula=formula,data=data).fit()return(model)forward_select(data=boston_data,target="Price")

lm=ols("Price~LSTAT+RM+PTRATIO+DIS+NOX+CHAS+B+ZN+CRIM+RAD+TAX",data=boston_data).fit()
lm.summary()

OLS线性回归结果各参数含义:
Dep.Variable : 使用的因变量值
Model:使用的模型
method: 使用的方法
Date:时间
No.Observations:样本数据个数
Df Residuals:残差的自由度
DF Model:模型的自由度
R-squared:R方值
Adj.R-squared:调整后的R方
F-statistic :F统计量
Prob(F-statistic):F统计量的p值
Log-Likelihood:似然度
AIC BIC:衡量模型优良度的指标,越小越好
const:截距项 P>|t| :t检验的p值,如果p值小于0.05 那么我们就认为变量是显著的
参考:Python 根据AIC准则定义向前逐步回归进行变量筛选(二)
4.3压缩估计(正则化)
除了刚刚讨论的直接对特征自身进行选择以外,我们还可以对回归的系数进行约束或者加罚的技巧对p个特征的模型进行拟合,显著降低模型方差,这样也会提高模型的拟合效果。具体来说,就是将回归系数往零的方向压缩,这也就是为什么叫压缩估计的原因了。
- 岭回归(L2正则化的例子):
在线性回归中,我们的损失函数为 J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2,我们在线性回归的损失函数的基础上添加对系数的约束或者惩罚,即:
J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 + λ ∑ j = 1 p w j 2 , 其 中 , λ ≥ 0 w ^ = ( X T X + λ I ) − 1 X T Y J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}w_j^2,\;\;其中,\lambda \ge 0\\ \hat{w} = (X^TX + \lambda I)^{-1}X^TY J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑pwj2,其中,λ≥0w^=(XTX+λI)−1XTY
调节参数 λ \lambda λ的大小是影响压缩估计的关键, λ \lambda λ越大,惩罚的力度越大,系数则越趋近于0,反之,选择合适的 λ \lambda λ对模型精度来说十分重要。岭回归通过牺牲线性回归的无偏性降低方差,有可能使得模型整体的测试误差较小,提高模型的泛化能力。
import pandas as pd
from sklearn import datasets #加载线性回归需要的模块和库
from sklearn import linear_modelboston = datasets.load_boston() #导入boston数据集
X = boston.data
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y'''
sklearn.linear_model.ridge_regression(X, y, alpha, *, sample_weight=None,solver='auto', max_iter=None, tol=0.001,verbose=0, random_state=None, return_n_iter=False, return_intercept=False, check_input=True)
- 参数: alpha:较大的值表示更强的正则化。浮点数 sample_weight:样本权重,默认无。 solver:求解方法,{‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’}, 默认=’auto’。“ svd”使用X的奇异值分解来计算Ridge系数。'cholesky'使用标准的scipy.linalg.solve函数通过dot(XT,X)的Cholesky分解获得封闭形式的解。'sparse_cg'使用scipy.sparse.linalg.cg中的共轭梯度求解器。作为一种迭代算法,对于大规模数据(可能设置tol和max_iter),此求解器比“ Cholesky”更合适。 lsqr”使用专用的正则化最小二乘例程scipy.sparse.linalg.lsqr。它是最快的,并且使用迭代过程。“ sag”使用随机平均梯度下降,“ saga”使用其改进的无偏版本SAGA。两种方法都使用迭代过程,并且当n_samples和n_features都很大时,通常比其他求解器更快。请注意,只有在比例大致相同的要素上才能确保“ sag”和“ saga”快速收敛。您可以使用sklearn.preprocessing中的缩放器对数据进行预处理。最后五个求解器均支持密集和稀疏数据。但是,当fit_intercept为True时,仅'sag'和'sparse_cg'支持稀疏输入。
'''
reg_rid = linear_model.Ridge(alpha=.5)
reg_rid.fit(X,y)
print(reg_rid.score(X,y)) #0.739957023371629
- Lasso回归(L1正则化的例子):
岭回归的一个很显著的特点是:将模型的系数往零的方向压缩,但是岭回归的系数只能呢个趋于0但无法等于0,换句话说,就是无法做特征选择。能否使用压缩估计的思想做到像特征最优子集选择那样提取出重要的特征呢?答案是肯定的!我们只需要对岭回归的优化函数做小小的调整就行了,我们使用系数向量的L1范数替换岭回归中的L2范数:
J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 + λ ∑ j = 1 p ∣ w j ∣ , 其 中 , λ ≥ 0 J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}|w_j|,\;\;其中,\lambda \ge 0 J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑p∣wj∣,其中,λ≥0
'''
class sklearn.linear_model.Lasso(alpha=1.0, *, fit_intercept=True, normalize=False, precompute=False, copy_X=True, max_iter=1000, tol=0.0001, warm_start=False, positive=False, random_state=None, selection='cyclic')- 参数: alpha:正则化强度,1.0代表标准最小二乘。 fit_intercept:是否计算模型截距。默认true。 normalize:是否标准化,默认false。 positive:是否强制系数为正,默认false。
'''
reg_lasso = linear_model.Lasso(alpha = 0.5) #lasso回归(L1正则化)
reg_lasso.fit(X,y)
print(reg_lasso.score(X,y)) #0.7140164719858566
五、降维
到目前为止,我们所讨论的方法对方差的控制有两种方式:一种是使用原始变量的子集,另一种是将变量系数压缩至零。但是这些方法都是基于原始特征 x 1 , . . . , x p x_1,...,x_p x1,...,xp得到的,现在我们探讨一类新的方法:将原始的特征空间投影到一个低维的空间实现变量的数量变少,如:将二维的平面投影至一维空间。
主成分分析(PCA):
主成分分析的思想:通过最大投影方差 将原始空间进行重构,即由特征相关重构为无关,即落在某个方向上的点(投影)的方差最大。在进行下一步推导之前,我们先把样本均值和样本协方差矩阵推广至矩阵形式:
PCA计算流程详解与实现
- [ 注]:后续自己换数据集重新实现一遍
六、模型超参数调优
- [注]:网格搜索算法,时间有限,后续单独整理
这篇关于集成学习task03-偏差、方差理论、特征提取和模型超参数调优的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








