本文主要是介绍Datawhale集成学习学习笔记——Task03偏差和方差理论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
偏差和方差理论
- 偏差和方法理论
- 作业
- 参考
偏差和方法理论
-
训练均方误差与测试均方误差: 一个模型的训练均方误差最小时, 不能保证测试均方误差同时很小
-
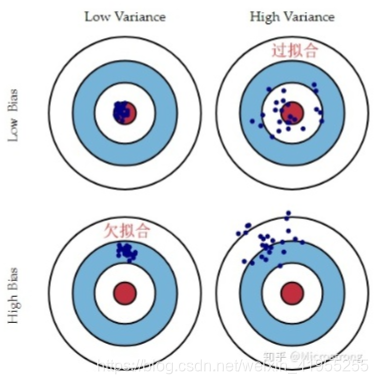
偏差-方差的权衡
E ( y 0 − f ^ ( x 0 ) ) 2 = Var ( f ^ ( x 0 ) ) + [ Bias ( f ^ ( x 0 ) ) ] 2 + Var ( ε ) E\left(y_{0}-\hat{f}\left(x_{0}\right)\right)^{2}=\operatorname{Var}\left(\hat{f}\left(x_{0}\right)\right)+\left[\operatorname{Bias}\left(\hat{f}\left(x_{0}\right)\right)\right]^{2}+\operatorname{Var}(\varepsilon) E(y0−f^(x0))2=Var(f^(x0))+[Bias(f^(x0))]2+Var(ε)
- 测试均方误差的期望值可以分解为 f ^ ( x 0 ) \hat{f}(x_0) f^(x0)的方差、 f ^ ( x 0 ) \hat{f}(x_0) f^(x0)的偏差平方和误差项 ϵ \epsilon ϵ的方差
- 建模任务的难度(不可约误差): Var ( ε ) \operatorname{Var}(\varepsilon) Var(ε), 任务确定后无法改变的,
- 偏差度量的是单个模型的学习能力,而方差度量的是同一个模型在不同数据集上的稳定性。
- “偏差-方差分解”说明:泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
- 一般来说, 模型的复杂度越高, 会增加模型的方差,但是会减少模型的偏差

-
特征提取
- 要选择一个测试误差达到最小的模型。但是实际上我们很难对实际的测试误差做精确的计算,因此要对测试误差进行估计,估计的方式有两种:训练误差修正与交叉验证。
- 训练误差修正: 对测试误差的间接估计
- 模型越复杂,训练误差越小,测试误差先减后增
- 先构造一个特征较多的模型使其过拟合,此时训练误差很小而测试误差很大,那这时加入关于特征个数的惩罚。因此,当我们的训练误差随着特征个数的增加而减少时,惩罚项因为特征数量的增加而增大,抑制了训练误差随着特征个数的增加而无休止地减小。具体的数学量如下 C p = 1 N ( R S S + 2 d σ ^ 2 ) C_p = \frac{1}{N}(RSS + 2d\hat{\sigma}^2) Cp=N1(RSS+2dσ^2),其中d为模型特征个数, R S S = ∑ i = 1 N ( y i − f ^ ( x i ) ) 2 RSS = \sum\limits_{i=1}^{N}(y_i-\hat{f}(x_i))^2 RSS=i=1∑N(yi−f^(xi))2, σ ^ 2 \hat{\sigma}^2 σ^2为模型预测误差的方差的估计值,即残差的方差。
- AIC赤池信息量准则: A I C = 1 d σ ^ 2 ( R S S + 2 d σ ^ 2 ) AIC = \frac{1}{d\hat{\sigma}^2}(RSS + 2d\hat{\sigma}^2) AIC=dσ^21(RSS+2dσ^2)
- BIC贝叶斯信息量准则: B I C = 1 n ( R S S + l o g ( n ) d σ ^ 2 ) BIC = \frac{1}{n}(RSS + log(n)d\hat{\sigma}^2) BIC=n1(RSS+log(n)dσ^2)
- 这种方法的桥梁是训练误差
- BIC惩罚最重, 选取的是特征个数最少的
- 交叉验证: 对测试误差的直接估计
- 交叉验证比训练误差修正的优势在于:能够给出测试误差的一个直接估计
- K折交叉验证得到的测试误差估计: C V ( K ) = 1 K ∑ i = 1 K M S E i C V_{(K)}=\frac{1}{K} \sum_{i=1}^{K} M S E_{i} CV(K)=K1∑i=1KMSEi
- 训练误差修正: 对测试误差的间接估计
- 在测试误差能够被合理的估计出来以后,我们做特征选择的目标就是:从p个特征中选择m个特征,使得对应的模型的测试误差的估计最小
-
最优子集选择
- 记不含任何特征的模型为 M 0 M_0 M0,计算这个 M 0 M_0 M0的测试误差。
- 在 M 0 M_0 M0基础上增加一个变量,计算p个模型的RSS,选择RSS最小的模型记作 M 1 M_1 M1,并计算该模型 M 1 M_1 M1的测试误差。
- 再增加变量,计算p*p-1个模型的RSS,并选择RSS最小的模型记作 M 2 M_2 M2,并计算该模型 M 2 M_2 M2的测试误差。
- 重复以上过程知道拟合的模型有p个特征为止,并选择p+1个模型 { M 0 , M 1 , . . . , M p } \{M_0,M_1,...,M_p \} {M0,M1,...,Mp}中测试误差最小的模型作为最优模型。
-
向前逐步选择
- 最优子集选择虽然在原理上很直观,但是随着数据特征维度p的增加,子集的数量为 2 p 2^p 2p,计算效率非常低下且需要的计算内存也很高,在大数据的背景下显然不适用。因此,我们需要把最优子集选择的运算效率提高,因此向前逐步选择算法的过程如下:
- 记不含任何特征的模型为 M 0 M_0 M0,计算这个 M 0 M_0 M0的测试误差。
- 在 M 0 M_0 M0基础上增加一个变量,计算p个模型的RSS,选择RSS最小的模型记作 M 1 M_1 M1,并计算该模型 M 1 M_1 M1的测试误差。
- 在最小的RSS模型下继续增加一个变量,选择RSS最小的模型记作 M 2 M_2 M2,并计算该模型 M 2 M_2 M2的测试误差。
- 以此类推,重复以上过程知道拟合的模型有p个特征为止,并选择p+1个模型 { M 0 , M 1 , . . . , M p } \{M_0,M_1,...,M_p \} {M0,M1,...,Mp}中测试误差最小的模型作为最优模型。
#定义向前逐步回归函数 def forward_select(data,target):variate=set(data.columns) #将字段名转换成字典类型variate.remove(target) #去掉因变量的字段名selected=[]current_score,best_new_score=float('inf'),float('inf') #目前的分数和最好分数初始值都为无穷大(因为AIC越小越好)#循环筛选变量while variate:aic_with_variate=[]for candidate in variate: #逐个遍历自变量formula="{}~{}".format(target,"+".join(selected+[candidate])) #将自变量名连接起来aic=ols(formula=formula,data=data).fit().aic #利用ols训练模型得出aic值aic_with_variate.append((aic,candidate)) #将第每一次的aic值放进空列表aic_with_variate.sort(reverse=True) #降序排序aic值best_new_score,best_candidate=aic_with_variate.pop() #最好的aic值等于删除列表的最后一个值,以及最好的自变量等于列表最后一个自变量if current_score>best_new_score: #如果目前的aic值大于最好的aic值variate.remove(best_candidate) #移除加进来的变量名,即第二次循环时,不考虑此自变量了selected.append(best_candidate) #将此自变量作为加进模型中的自变量current_score=best_new_score #最新的分数等于最好的分数print("aic is {},continuing!".format(current_score)) #输出最小的aic值else:print("for selection over!")breakformula="{}~{}".format(target,"+".join(selected)) #最终的模型式子print("final formula is {}".format(formula))model=ols(formula=formula,data=data).fit()return(model)
-
- 要选择一个测试误差达到最小的模型。但是实际上我们很难对实际的测试误差做精确的计算,因此要对测试误差进行估计,估计的方式有两种:训练误差修正与交叉验证。
-
压缩估计(正则化)
除了直接对特征自身进行选择以外,还可以对回归的系数进行约束或者加罚的技巧对p个特征的模型进行拟合,显著降低模型方差,这样也会提高模型的拟合效果。具体来说,就是将回归系数往零的方向压缩.
-
岭回归(L2正则化的例子)
J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 + λ ∑ j = 1 p w j 2 , 其 中 , λ ≥ 0 w ^ = ( X T X + λ I ) − 1 X T Y J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}w_j^2,\;\;其中,\lambda \ge 0\\ \hat{w} = (X^TX + \lambda I)^{-1}X^TY J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑pwj2,其中,λ≥0w^=(XTX+λI)−1XTY
调节参数 λ \lambda λ的大小是影响压缩估计的关键, λ \lambda λ越大,惩罚的力度越大,系数则越趋近于0,反之,选择合适的 λ \lambda λ对模型精度来说十分重要。岭回归通过牺牲线性回归的无偏性降低方差,有可能使得模型整体的测试误差较小,提高模型的泛化能力。
将模型的系数往零的方向压缩,但是岭回归的系数只能呢个趋于0但无法等于0,换句话说,就是无法做特征选择
-
Lasso回归(L1正则化的例子)
J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 + λ ∑ j = 1 p ∣ w j ∣ , 其 中 , λ ≥ 0 J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}|w_j|,\;\;其中,\lambda \ge 0 J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑p∣wj∣,其中,λ≥0
- 特征选择
- 不能使用梯度下降法求最小值, LARS模型算w
-
区别:

- 椭圆形曲线为RSS等高线,菱形和圆形区域分别代表了L1和L2约束,Lsaao回归和岭回归都是在约束下的回归,因此最优的参数为椭圆形曲线与菱形和圆形区域相切的点。但是Lasso回归的约束在每个坐标轴上都有拐角,因此当RSS曲线与坐标轴相交时恰好回归系数中的某一个为0,这样就实现了特征提取。反观岭回归的约束是一个圆域,没有尖点,因此与RSS曲线相交的地方一般不会出现在坐标轴上,因此无法让某个特征的系数为0,因此无法做到特征提取。
-
-
降维
- 降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度
- f可能是显式的或隐式的、线性的或非线性的。
- 在原始的高维空间中,包含有冗余信息以及噪音信息
- 希望减少冗余信息所造成的误差,提高精度。或者希望通过降维算法来寻找数据内部的本质结构特征
- 在很多算法中,降维算法成为了数据预处理的一部分,如PCA。事实上,有一些算法如果没有降维预处理,其实是很难得到很好的效果的。
- 主成分分析(PCA): 通过最大投影方差 将原始空间进行重构,即由特征相关重构为无关,即落在某个方向上的点(投影)的方差最大。
作业

-
请用一个具体的案例解释什么是偏差和方差
- 偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据.
- 方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散.
-
偏差与方差和误差之间的关系
泛化误差可分解为偏差、方差和噪声之和。
偏差度量了学习算法的期望预测与真实效果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
-
训练误差与测试误差之间的联系和区别,如何估计测试误差
- 训练误差与测试误差都是模型对数据拟合能力的刻画, 但是训练误差刻画的是模型对于训练数据的拟合能力, 测试误差刻画的是模型对测试数据的拟合能力
- 训练误差修正(间接估计)与交叉验证(直接估计)
-
岭回归和lasso回归的异同点
- 相同: 都可以用来解决标准线性回归的过拟合问题。
- 不同: lasso 可以用来做 feature selection,而 ridge 不行。或者说,lasso 更容易使得权重变为 0,而 ridge 更容易使得权重接近 0。 从贝叶斯角度看,lasso(L1 正则)等价于参数 w 的先验概率分布满足拉普拉斯分布,而 ridge(L2 正则)等价于参数 w 的先验概率分布满足高斯分布
-
如果使用pca降维前是一个三维的椭球,那么把该图形降维到二维是一个什么样的图形
- a=b>c时为圆形
- 其他情况时为椭圆形
-
尝试使用对偶理论和核函数对pca进行非线性拓展,使得pca变成非线性降维
-
本教程讲述的三种模型简化的方法之间有什么异同点
- 最优子集
- 压缩估计
- 降维
- 模型的复杂来源于特征数的多少, 而最优子集和降维都是降低特征数来达到简化模型, 但是降维是创建新的特征,最优子集是选择部分特征. 压缩估计是不改变输入特征数量的情况下, 使用惩罚项约束参数, 使得参数不关注或降低对某些特征的关注
-
尝试使用sklearn,对一组数据先进行特征的简化,在使用回归模型,最后使用网格搜索调参,观察三种方法的优劣
参考
- B站-机器学习数学基础(基于python)
- DataWhale集成学习教程
这篇关于Datawhale集成学习学习笔记——Task03偏差和方差理论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








