本文主要是介绍k8s提交spark应用消费kafka数据写入elasticsearch7,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
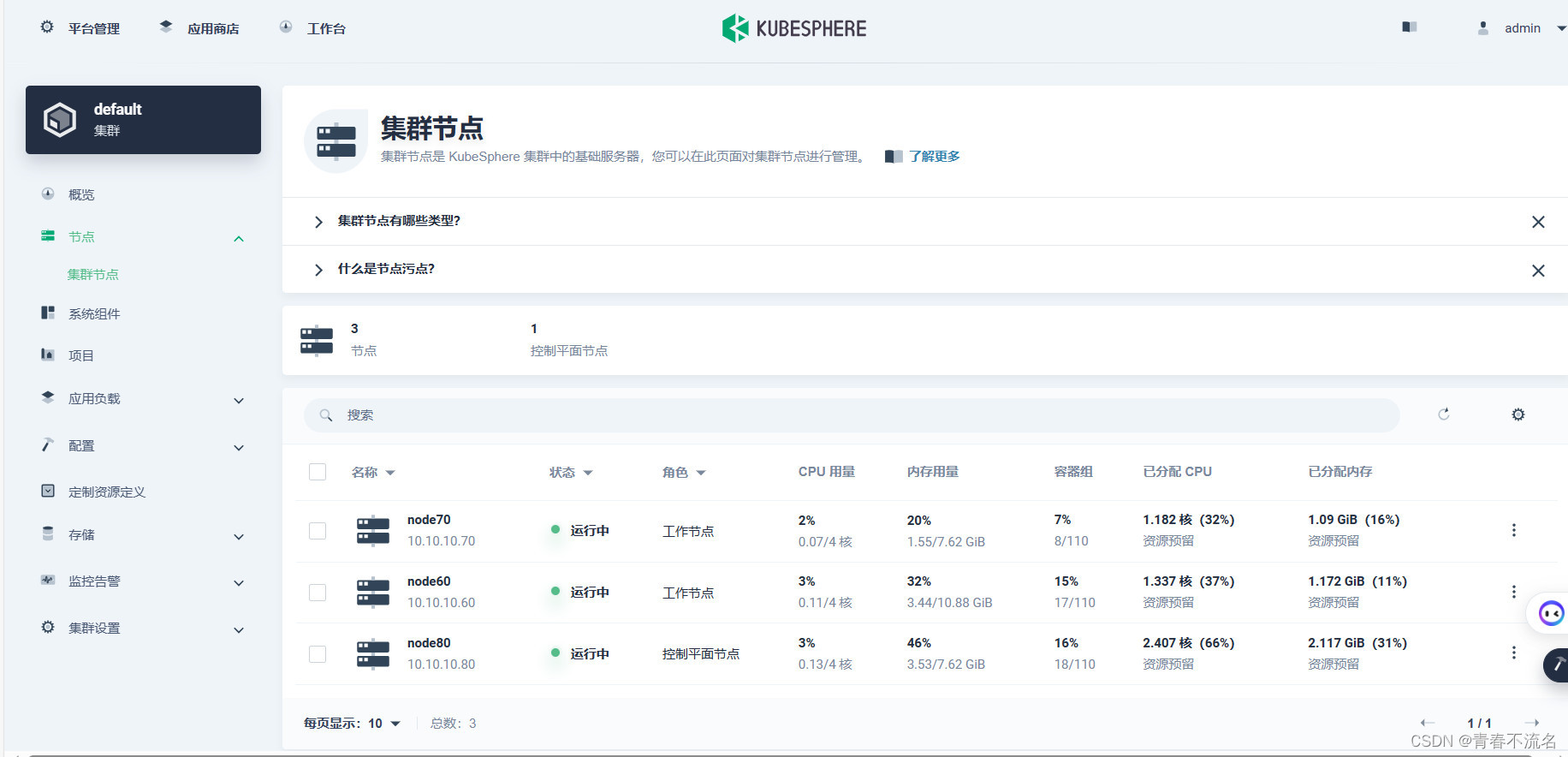
一、k8s集群环境
k8s 1.23版本,三个节点,容器运行时使用docker。
spark版本时3.3.3
k8s部署单节点的zookeeper、kafka、elasticsearch7

二、spark源码
https://download.csdn.net/download/TT1024167802/88509398
命令行提交方式
/opt/module/spark-3.3.3/bin/spark-submit --name KafkaSparkElasticsearch7 --verbose --master k8s://https://10.10.10.80:6443 --deploy-mode cluster --conf spark.network.timeout=300 --conf spark.executor.instances=3 --conf spark.driver.cores=1 --conf spark.executor.cores=1 --conf spark.driver.memory=1024m --conf spark.executor.memory=1024m --conf spark.kubernetes.namespace=apache-spark --conf spark.kubernetes.container.image.pullPolicy=IfNotPresent --conf spark.kubernetes.container.image=zhxl1989/spark-demo:3.3.3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-service-account --conf spark.kubernetes.authenticate.executor.serviceAccountName=spark-service-account --conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" --conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" --class com.example.cloud.KafkaSparkElasticsearch7 local:///opt/spark/examples/jars/KafkaSparkElasticsearch7-jar-with-dependencies.jar 3000
基于apache/spark:3.3.3镜像构建,将KafkaSparkElasticsearch7-jar-with-dependencies.jar添加到镜像容器的/opt/spark/examples/jars/目录下。
main类名
com.example.cloud.KafkaSparkElasticsearch7
k8s主节点入口
k8s://https://10.10.10.80:6443
设置响应的名称空间及account 、rule权限。
三、运行效果

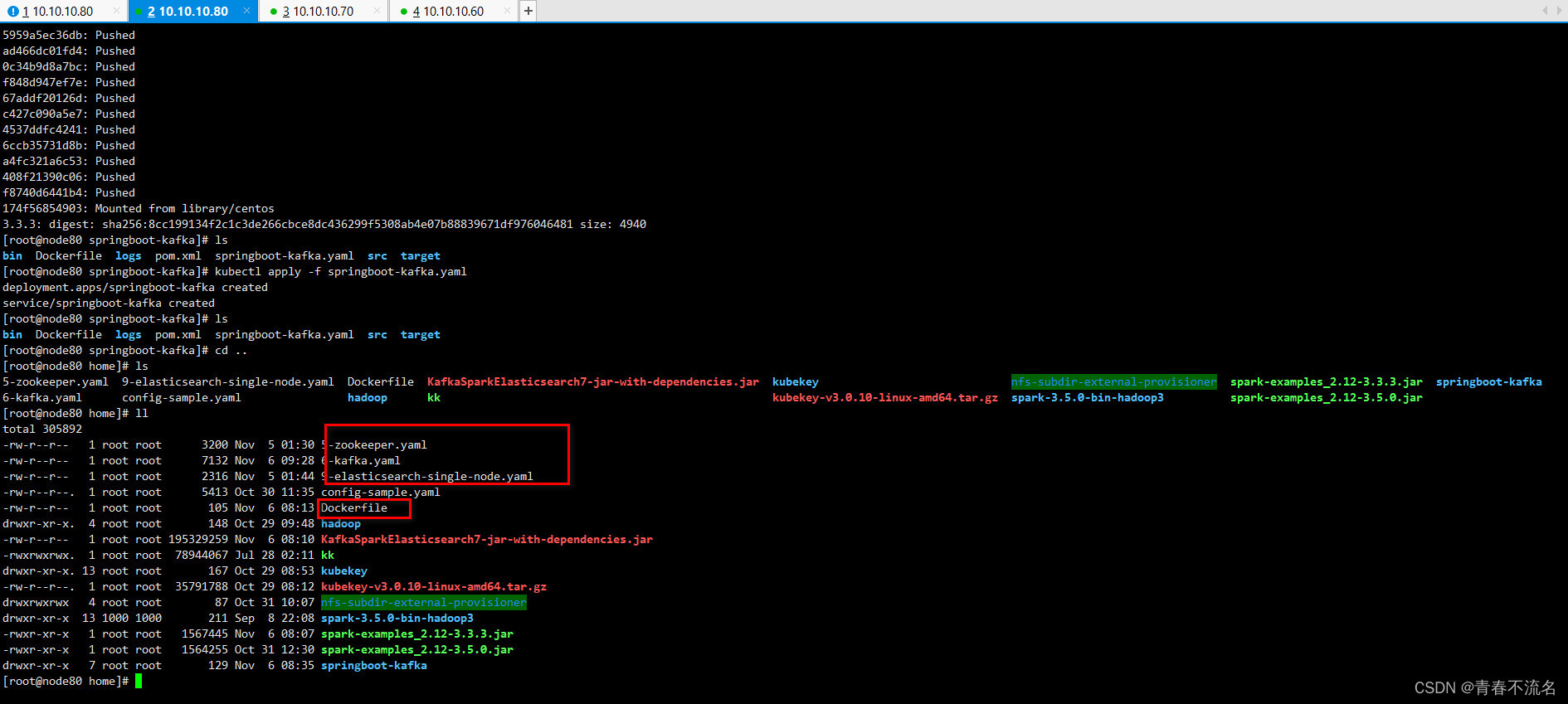
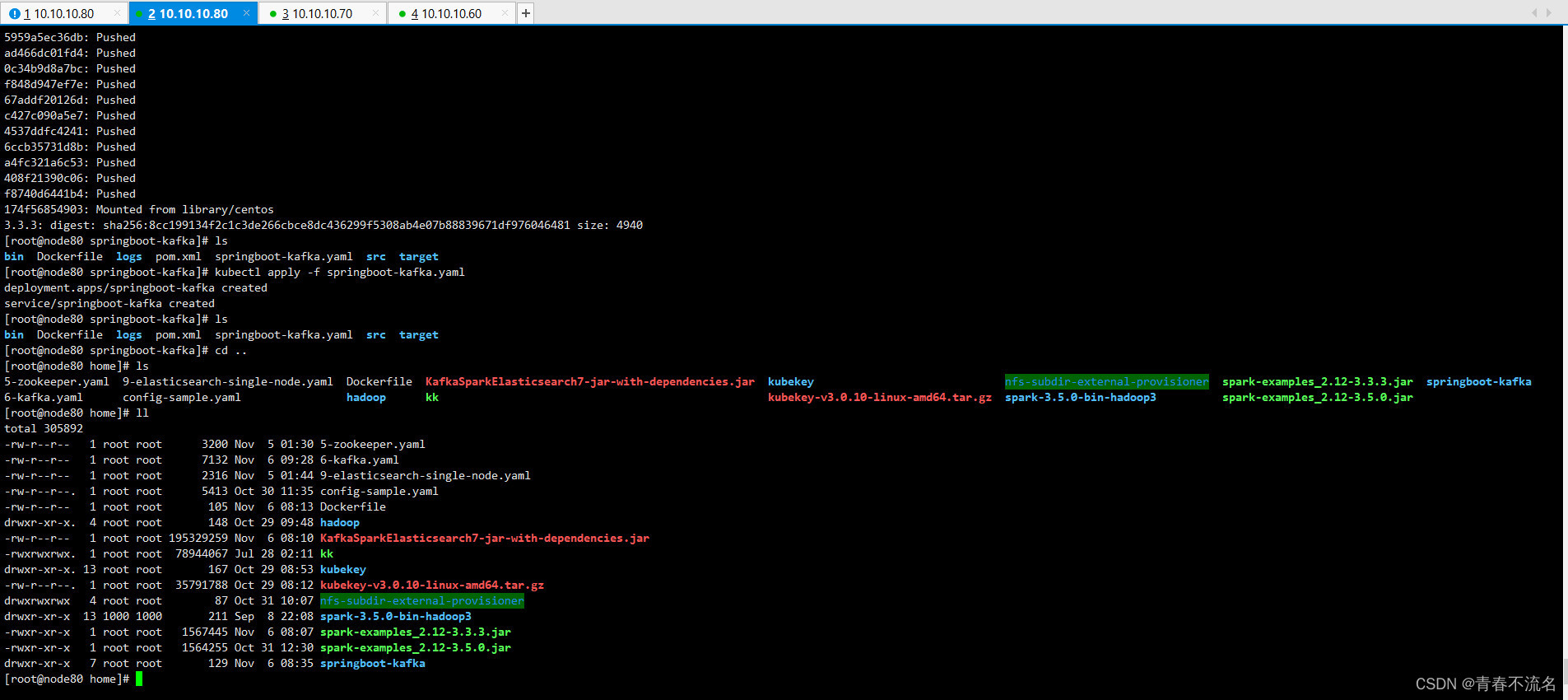
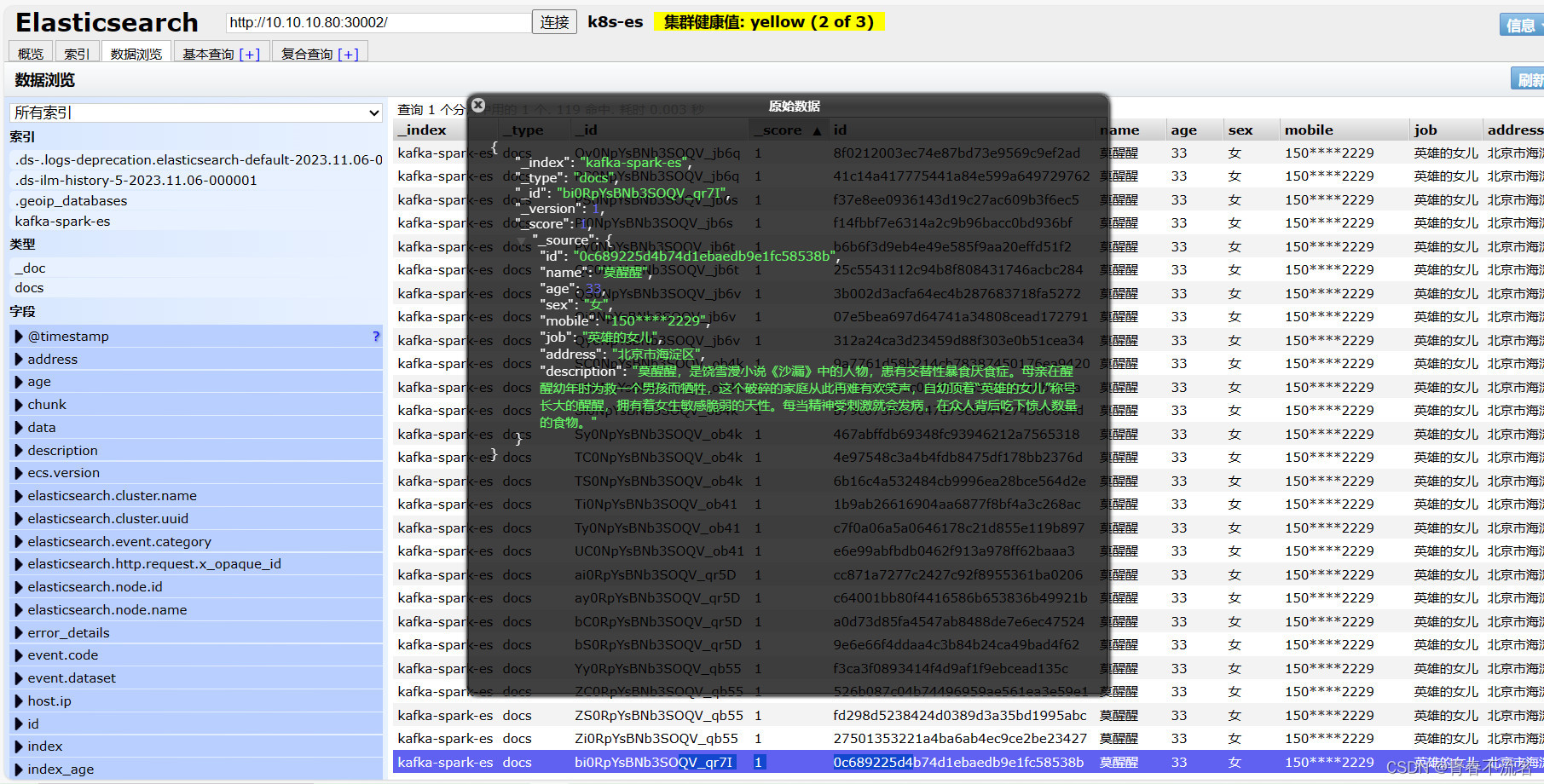
这篇关于k8s提交spark应用消费kafka数据写入elasticsearch7的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






