本文主要是介绍熟悉mmdetection3d数据在模型中的处理流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1、搭建模型
- 2、读取数据
- 3、运行流程
- 3.1 图像特征获取
- 3.2 点云特征获取
- 3.3 head
- 3.4 编码bbox
- 4、可视化
- 5、总结
- 本图文数据集采取KITTI数据集
- 配置文件的介绍可以参考博主上一篇图文
- 本图文旨在利用一条数据,走完整个多模态数据处理分支,获得bbox,并可视化在图像上
1、搭建模型
-
本次教程选用的模型为MVXNet,是一个多模态融合的3D目标检测模型
-
配置文件: mmdetection3d/configs/mvxnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class.py
-
本次使用预训练模型,可以在mmdetection3d的mozel zoo中下载 MVXNet模型
from mmdet3d.apis import init_model
config_file = '/home/wistful/work/mmdetection3d/configs/mvxnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class.py'
checkpoint_file = '/home/wistful/ResultDir/my_pth/mxvnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class_20210831_060805-83442923.pth'model = init_model(config_file, checkpoint_file, 'cuda:1')
2、读取数据
from mmdet3d.datasets import build_dataset
from mmcv import Configcfg = Config.fromfile(config_file)
# 读取数据集
datasets = [build_dataset(cfg.data.train)]
# 我们取其中的一条数据,作为演示用例
one_data = datasets[0][0]
-
根据我们的配置文件,我们得到的datasets为一个长度为7424(KITTI训练集长度)的列表,每一项包括4个字段:[‘img_metas’, ‘points’, ‘img’, ‘gt_bboxes_3d’, ‘gt_labels_3d’]
-
接下来所有数据均使用这一个one_data
3、运行流程
MVXNet结构图如下:
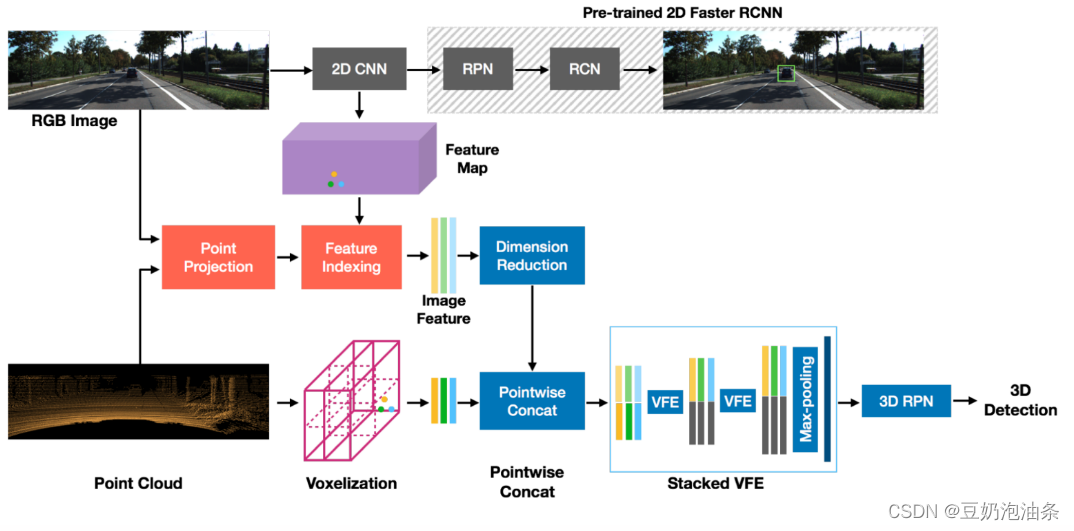
MVXNet简化版模型结构:
model = dict(type='DynamicMVXFasterRCNN',img_backbone=dict(), # 图像骨干img_neck=dict(), # 图像neckpts_voxel_layer=dict(), # 体素层pts_voxel_encoder=dict(), # 体素编码层pts_middle_encoder=dict(), # 中间编码层pts_backbone=dict(), # 点云骨干pts_neck=dict(), # 点云neckpts_bbox_head=dict() # bbox head)
结合结构图,以上配置文件的最简理解是,图像经过骨干、neck得到图像特征;点云经过体素、编码得到点云特征;查看原版配置文件就可以看到,会在一个层融合图像和点云特征;随后经过head,产出bbox。接下来,我们先来获取图像特征:
3.1 图像特征获取
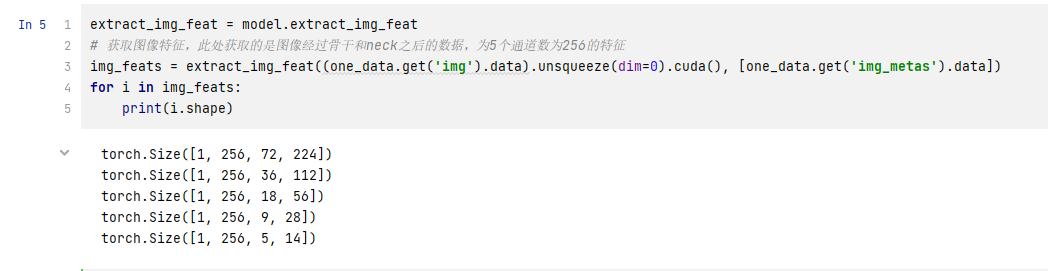
extract_img_feat = model.extract_img_feat
# 获取图像特征,此处获取的是图像经过骨干和neck之后的数据,为5个通道数为256的特征
img_feats = extract_img_feat((one_data.get('img').data).unsqueeze(dim=0).cuda(), [one_data.get('img_metas').data])
for i in img_feats:print(i.shape)# extrac_img_feat代码:
def extract_img_feat(self, img, img_metas):"""Extract features of images."""if self.with_img_backbone and img is not None:input_shape = img.shape[-2:] # 获取图片的尺寸# update real input shape of each single imgfor img_meta in img_metas:img_meta.update(input_shape=input_shape) # 更新一下img_metasif img.dim() == 5 and img.size(0) == 1: # 维度等于5的话去除一个维度(只取一个图片)img.squeeze_()elif img.dim() == 5 and img.size(0) > 1: # 取出批量、图片个数、通道、高、宽B, N, C, H, W = img.size()img = img.view(B * N, C, H, W) # 重构为 [批量*数量, 通道, 高, 宽]img_feats = self.img_backbone(img) # 送入骨干else:return Noneif self.with_img_neck:img_feats = self.img_neck(img_feats) # 将骨干再送入neckreturn img_feats
输出如下:
3.2 点云特征获取
extract_pts_feat = model.extract_pts_feat
# 获取点云特征,此处同上面各个字段的类型需要去代码里看定义
img_feat_list = list(img_feats)
pts_feats = extract_pts_feat([one_data.get('points').data.cuda()], img_feat_list, [one_data.get('img_metas').data])# extract_pts_feat代码:
def extract_pts_feat(self, pts, img_feats, img_metas):"""Extract features of points."""if not self.with_pts_bbox:return Nonevoxels, num_points, coors = self.voxelize(pts) # 体素化# 体素编码器voxel_features = self.pts_voxel_encoder(voxels, num_points, coors,img_feats, img_metas)batch_size = coors[-1, 0] + 1x = self.pts_middle_encoder(voxel_features, coors, batch_size)x = self.pts_backbone(x)if self.with_pts_neck:x = self.pts_neck(x)return x
此时,我们已经得到图像特征和点云特征了,下面将特征送入head
3.3 head
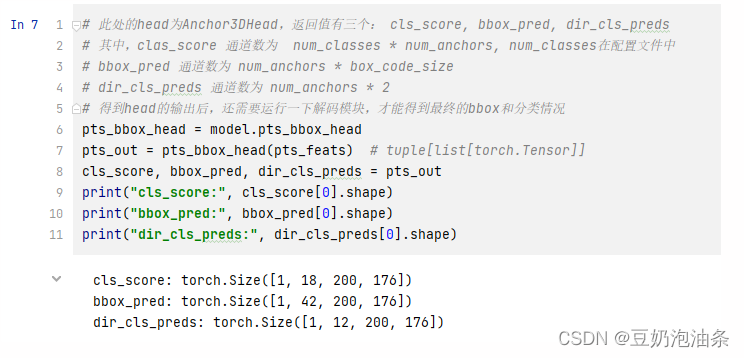
# 此处的head为Anchor3DHead,返回值有三个: cls_score, bbox_pred, dir_cls_preds
# 其中,clas_score 通道数为 num_classes * num_anchors, num_classes在配置文件中
# bbox_pred 通道数为 num_anchors * box_code_size
# dir_cls_preds 通道数为 num_anchors * 2
# 得到head的输出后,还需要运行一下解码模块,才能得到最终的bbox和分类情况
pts_bbox_head = model.pts_bbox_head
pts_out = pts_bbox_head(pts_feats) # tuple[list[torch.Tensor]]
cls_score, bbox_pred, dir_cls_preds = pts_out
print("cls_score:", cls_score[0].shape)
print("bbox_pred:", bbox_pred[0].shape)
print("dir_cls_preds:", dir_cls_preds[0].shape)
3.4 编码bbox
# 将head得到的输出编码为bboxer
bboxes = model.pts_bbox_head.get_bboxes(cls_score, bbox_pred, dir_cls_preds, [one_data.get('img_metas').data])
print(type(bboxes[0][0])) # 是在LiDAR坐标系下
bboxes_data = bboxes[0][0] # 得到了n个预测框
bboxes_data

以上是最简版的一条数据在模型里的流动过程,还有n多实现细节,需要去深扒代码
4、可视化
这一部分,我们可视化我们在3.4中得到的bbox,程序自己看吧
import cv2
from mmdet3d.core import show_multi_modality_resultimg_metas = one_data.get('img_metas').data
img_file_path = img_metas['filename'] # 获取one_data对应的图像文件名img = cv2.imread(img_file_path) # 读取图像
front_mat = one_data.get('img_metas').data.get('lidar2img') # 获取投影矩阵gt_boxes = one_data.get('gt_bboxes_3d').data # 从one_data中获取gt_bboxes
print(gt_boxes)
print(bboxes_data)
# gt_bboxes_cam
bboxes_data = bboxes_data.to('cpu')
# 保存可视化图像到out_dir
show_multi_modality_result(img=img,box_mode='lidar',gt_bboxes=gt_boxes,img_metas=img_metas,pred_bboxes=bboxes_data,proj_mat=front_mat,out_dir="/home/wistful/work/mmdetection3d/visual_img/",filename="test",show=False)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GcltvkGl-1678449986037)(null)]](https://img-blog.csdnimg.cn/db147b622afc49119c7f365a3299e685.png)
这里我得到了四个输出,是因为我改动了一下show_multi_modality_result方法,加了一个将地面真相bbox和预测bbox绘制到一张图像上的方法。如下图所示,橙色为地面真相bbox,蓝色为预测框

5、总结
简单画了一个流程图,橙色代表我们获取的数据内容,蓝色代表网络,绿色代表我们得到的东西

这篇关于熟悉mmdetection3d数据在模型中的处理流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






