本文主要是介绍Spark - Resilient Distributed Datasets (RDDs)介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
RDD介绍
RDD构建
RDD分区数
RDD算子
Transformation算子
Action算子
RDD持久化
RDD缓存
检查点
RDD共享变量
广播变量
累加器Accumulator
RDD介绍
Resilient Distributed DataSets,弹性分布式数据集,可以把RDD看作一种分布式集合。其RDD本身不存储数据,数据实际存储在内存或磁盘上。同时RDD中的数据不可更改,只能通过算子生成一个新的RDD实现对数据的修改。一个父RDD可以被多个下游RDD依赖,为避免父RDD重复计算,可对父RDD的计算结果缓存。RDD可定义分区规则,实现多线程并发处理RDD中的数据
RDD构建
spark-shell启动spark客户端 sh spark-shell --master local

本地集合,通过sc.parallelize转变为RDD

本地集合,通过sc.makeRDD转变为RDD

本地文件,通过sc.textFile转变为RDD

外部文件,通过sc.textFile转变为RDD

RDD分区数
RDD的分区数建议与CPU核数保持一致,为充分利用CPU性能,可设置为CPU核数的2~3倍,启动时,通过CPU核数确定线程并行度参数
spark.default.parallelism = 指定的CPU核数(集群模式最小2)
等同于 --master local[指定的CPU核数]
- 对于本地集合方式构建RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 8)
若指定分区数,采用指定的分区数;若未指定,采用spark.default.parallelism参数值
- 对于本地/外部文件方式构建RDD
rdd = sc.textFile(name="file:///export/data/workspace/parent/spark_core/data/", minPartitions=3)若指定了分区数 minPartitions,就采用指定的分区数;若没有指定分区数,
defaultMinPartition = (spark.default.parallelism,2)
RDD分区数 = max(本地file的分片数,defaultMinPartition)
RDD分区数 = max(hdfs文件的block数量,defaultMinPartition)
- wholeTextFiles
默认,一个目录有多少文件,就对应多少分区,为避免分区数过多,增加线程和IO负 担,wholeTextFiles专门用于处理小文件,其尽可能减少分区数
rdd = sc.wholeTextFiles(path="file:///export/data/workspace/parent/spark_core/data")
-
调整分区数
repartition、coalesce、partitionBy 三个算子可以调整RDD分区数
# 增大分区
rdd = rdd.repartition(5).glom().collect()# 减小分区
rdd = rdd.repartition(5).glom().collect()
# repartition本质上是coalesce的一种当参数2为True的简写方案,# coalesce
# 参数1: 分区数
# 参数2:表示是否存在shuffle, 默认为false
# 参数2为False 只能减少分区,为True可以增大分区
rdd = rdd.coalesce(5).glom().collect()# partitionBy: 专门针对kv类型重分区的函数
# 默认: 根据key进行Hash取模划分操作 ,也可自定义分区规则rm = sc.parallelize([(1, 'c01'), (2, 'c02'), (3, 'c03'),(4, 'c04'), (5, 'c05'), (6, 'c06'),(7, 'c07'), (8, 'c08'), (9, 'c09'),(10, 'c10')], 3)rdd = rm.partitionBy(5).glom().collect()# 自定义分区规则rm1 = rm.partitionBy(2, lambda key: 0 if key <= 5 else 1).glom().collect()
RDD算子
RDD对象中提供的一系列具有特定动能的函数
Transformation算子
定义RDD的计算规则,不会触发JOB执行,须通过Action算子触发执行

Action算子
产生一个Job任务,触发执行,运行这个Action算子所依赖的所有Transformation算子

RDD持久化
为避免RDD重复计算或RDD数据损坏,其RDD计算结果可以持久化,即RDD数据可以保存到内存或磁盘
RDD缓存
即RDD计算结果的临时缓存, 缓存数据可以保存到内存(executor内存空间),也可以保存到磁盘, 甚至支持将缓存数据保存到堆外内存(executor以外的内存空间)
由于临时存储, 可能存在数据丢失, 当缓存失效后, 可以基于原有依赖关系重新计算。因为缓存操作, 并不会将RDD之间的依赖关系给截断
缓存的API都是LAZY的, 如果需要触发缓存操作, 必须后续跟上一个action算子, 一般建议使用count。 如果不添加action算子, 只有当后续遇到第一个action算子后, 才会触发缓存
- 设置缓存
rdd.cache(): 仅能将数据缓存到内存中
rdd.persist(缓存的级别(位置)): 默认将数据缓存到内存中, 也支持自定义缓存位置
例如:
rdd.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()

- 清理缓存:
rdd.unpersist()
默认情况下, Spark程序执行完成后, 缓存会自动失效, 自动删除
- 使用场景
当某个RDD被使用多次的时候,建议缓存此RDD数据
当某个RDD计算结果复杂,并且使用不止一次,建议缓存此RDD数据
检查点
checkpoint将数据保存到HDFS上,借助HDFS的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
构建checkpoint操作后, 会将RDD之间的依赖关系截断, 后续计算如果出现了问题, 直接从检查点的位置恢复数据
集群模式中, checkpoint的保存路径地址必须是HDFS, 如果是local模式, 可以支持本地路径, checkpoint数据不会自动删除, 必须通过手动方式将其删除掉
Checkpoint相关的API:
设置检查点的保存数据位置
sc.setCheckpointDir('路径地址') 默认路径为HDFS
对应RDD上开启检查点
rdd.checkpoint()
rdd.count()
Spark容错机制:首先会查看RDD是否被Cache,如果被Cache到内存或磁盘,直接获取,否则查看Checkpoint所指定的HDFS中是否缓存数据,如果都没有则直接从父RDD开始重新计算还原。
一般建议将两种持久化的方案一同作用于项目环境中, 先设置缓存, 然后在设置检查点, 最后统一触发执行(先将数据缓存到内存中, 然后将内存数据写入到磁盘结束, 在使用的时候, 程序会自动优先读取内存, 内存没有读取磁盘)
# 先设置缓存rdd4.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)# 接着设置checkpointrdd4.checkpoint()# 最后统一触发rdd4.count()RDD共享变量
默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task) 和 任务控制节点(Driver Program) 之间共享变量
广播变量
在Driver端定义一个共享的变量, 如果不使用广播变量。 各个线程在运行Task的时候, 都需要将这个变量拷贝到自己的线程中, 对网络传输, 内存的使用都是一种浪费, 而且影响效率
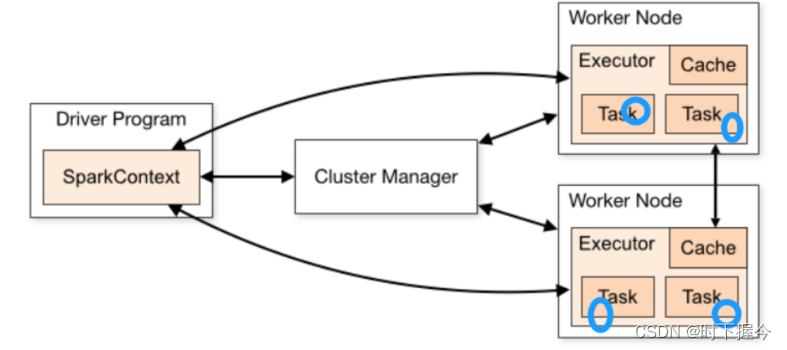
如果使用广播变量。 会将变量在每个executor上放置一份, 各个线程直接读取executor上的变量,不需要拉取到Task中。 减少副本的数量, 对内存和网络都降低了, 从而提升效率
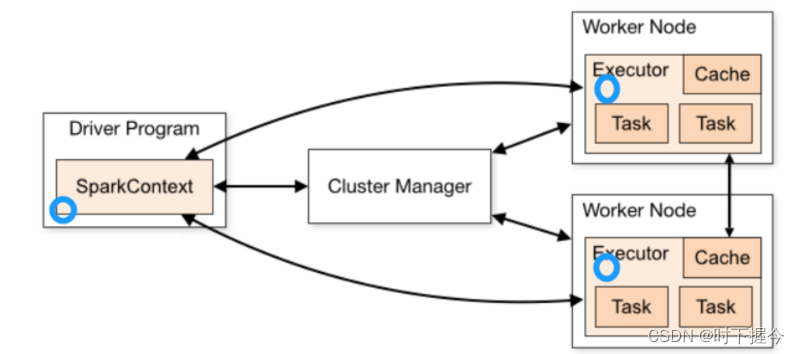
广播变量是只读的, 各个Task只能读取数据, 不能修改
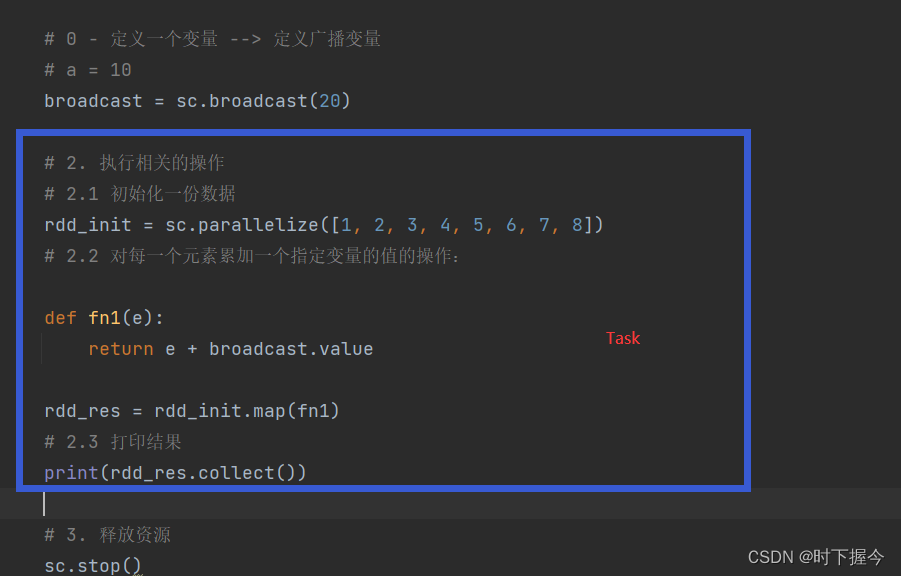
累加器Accumulator
一般,使用RDD的 map() 函数或者用 filter() 传条件时,可以使用驱动器driver程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。若保持driver程序中变量的原子性,可以使用Accumulator
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,即确提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取Accumulator的值,只有Driver程序可以读取Accumulator的值。创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名。
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
累加器只能在Driver端定义,在Executor端更新,不能在Executor端定义,不能在Executor端.value获取值。
累加器在遇到多次action操作的时候会出现重复累加求和的问题,解决办法是在调用累加器后的RDD上, 对其设置缓存操作
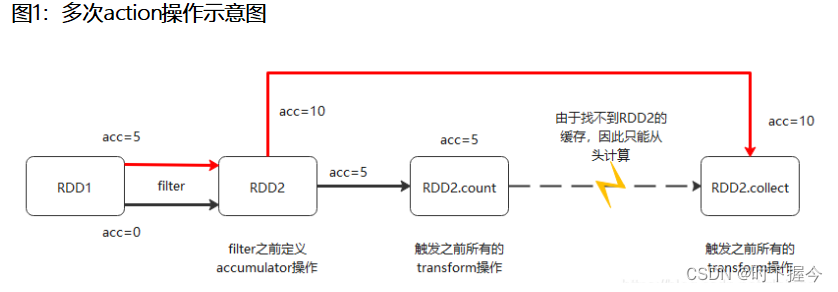
# 定义一个公共变量 --> spark的累加器实现acc = sc.accumulator(0)# 2. 执行相关的操作# 2.1 初始化一份数据rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8])# 2.2 对每一个元素累加一个指定变量的值的操作:# 需求: 对每一个元素进行 +10返回, 在执行过程中, 请统计共计对多少个数据进行了 +10 操作def fn1(e):acc.add(1)return e + 10rdd_map = rdd_init.map(fn1)# 设置缓存rdd_map.cache().count()# 触发一个Actionrdd_map.reduceByKey()# 触发另一个Actionrdd_filter = rdd_map.filter(lambda e : e > 5)# 2.3 打印结果print(rdd_filter.collect())
RDD依赖
窄依赖
父RDD与子RDD之间的分区一对一,即父RDD中,一个分区内的数据不能分割,只能由子RDD中的一个分区整个利用
宽依赖
父RDD中一个分区的数据被子RDD中的多个分区接收,中间必然存在Shuffle操作;
Shuffle是判断宽窄依赖的重要依据,同时也是划分stage的依据
这篇关于Spark - Resilient Distributed Datasets (RDDs)介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








