本文主要是介绍tolua中table.remove怎么删除表中符合条件的数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
tolua中table.remove怎么删除表中符合条件的数据
- 介绍
- 问题(错误方式删除数据)
- 正确删除方案
- 从后向前删除
- 递归方式删除
- 插入新表方式
- 拓展一下
- 总结
介绍
在lua中删除表中符合条件的数据其实很简单,但是有一个顺序问题,因为lua的表中的数据删除需要通过table.remove来删除,当你删除前一个后,索引值发生了变化。
问题(错误方式删除数据)
--测试lua表
local tab1 = {[1] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[2] = {Id = 105,value1 = 1,value2 = 2,value3 = 3,},[3] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[4] = {Id = 108,value1 = 1,value2 = 2,value3 = 3,},[5] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},}--错误方式一for k, v in pairs(tab1) doif(v.Id == 101) thentable.remove(table,k)endend--与上面删除方式相同(换了个写法)for i = 1, #tab1 doif(tab1[i].Id == 101) thentable.remove(table,i)endend--错误方式二local index = 1for i = 1, #tab1 doif(tab1[i].Id == 101) thentable.remove(table,index)index = index - 1endindex = index + 1end
上面这两种方式都是错误的,最终打印并不是实际想象中的打印
正确删除方案
从后向前删除
--测试数据的lua表local tab1 = {[1] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[2] = {Id = 105,value1 = 1,value2 = 2,value3 = 3,},[3] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[4] = {Id = 108,value1 = 1,value2 = 2,value3 = 3,},[5] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},}this.RemoveTabValue(tab1,101)for k, v in pairs(tab1) dologError("k ========>"..tostring(k))logError("v.Id ========>"..v.Id)endfunction this.RemoveTabValue(tab,Id)for i = #tab, 1 ,-1 doif tab[i].Id == Id thentable.remove(tab,i)endend
end打印如下
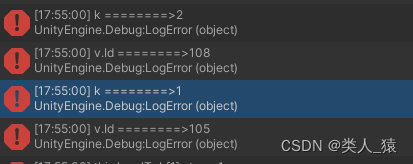
递归方式删除
--测试数据的lua表local tab1 = {[1] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[2] = {Id = 105,value1 = 1,value2 = 2,value3 = 3,},[3] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[4] = {Id = 108,value1 = 1,value2 = 2,value3 = 3,},[5] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},}this.RemoveTabValue(tab1,101)for k, v in pairs(tab1) dologError("k ========>"..tostring(k))logError("v.Id ========>"..v.Id)end --递归方法
function this.RemoveTabValue(tab,Id)for k, v in pairs(tab) doif v.Id == Id thentable.remove(tab,k)this.RemoveTabValue(tab,Id)breakendend
end打印如下
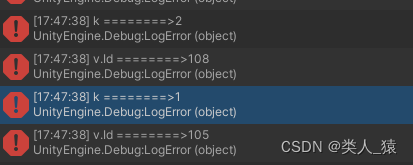
插入新表方式
--测试数据的lua表local tab1 = {[1] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[2] = {Id = 105,value1 = 1,value2 = 2,value3 = 3,},[3] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[4] = {Id = 108,value1 = 1,value2 = 2,value3 = 3,},[5] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},}local newtab = {}for k, v in pairs(tab1) doif v.Id == 101 thentable.insert(newtab, v)endend--这里我没有写将tab1表删除的方法,等于还占有内存,所以相当于开辟了新内存空间--可以自己删除原tab1表的数据,或者使用上面两种方式--此方法占用额外内存空间for k, v in pairs(newtab) dologError("k ========>"..tostring(k))logError("v.Id ========>"..v.Id)end 打印如下
拓展一下
这里知识简单说一下,如果是遇见下面这种字典类型的lua表
- #tab1长度结果是3不是5,剔除了[true]和[“a”]不算(不识别非数字为k的键值对)
- 只能用pairs的方式才能读取出所有键值对,如果用ipairs只能读取出[1][2][3]数字为k的键值对
local tab1 = {[1] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[2] = {Id = 105,value1 = 1,value2 = 2,value3 = 3,},[3] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},[true] = {Id = 108,value1 = 1,value2 = 2,value3 = 3,},["a"] = {Id = 101,value1 = 1,value2 = 2,value3 = 3,},}总结
如果文章对你有帮助可以留下免费的爱心和关注,感谢
这篇关于tolua中table.remove怎么删除表中符合条件的数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




