本文主要是介绍Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类2.0版本ing
- 数据集处理
- 网络模型部分
- 训练函数部分
- k折交叉验证部分
- 最终结果部分
- 完整代码

Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类2.0版本ing
首先感谢大家的批评指正与支持,先对上一版本中代码存在的问题统一更新,现发布2.0 version
你好! 本篇博客主要是针对基于Pytorch深度学习刚入门的同学,本文基于六种鸟类的分类问题,以小数据集为例,带领读者从总体上了解一个从零开始的图像分类问题,陆续会写一些具体的问题,如本人在跑这个小项目中遇到的所有问题以及解决方法,重点在于掌握图像分类这一基本问题中数据集的分割、读取、封装的基本思想,接着会详细的介绍构建的模型,以及针对小数据集而使用的k折交叉验证的方法,还有使用到的网络,损失函数,优化器,等涉及到图像分类问题的所有的基本内容。
数据集处理
我们的小数据集共有654张照片,共六类鸟,每一类放在了一个文件夹下。不使用K折交叉验证的话,是不需要分割训练集和数据集的,因此只需要把所有的数据写入一份文件里,然后再打乱顺序),分为K折,依次取每一折作为测试集、剩下的作为训练集。接着就可以把txt文本送入Pytorch的torch.utils.data.Dataset类中,因为笔者想把内部的原理搞的透一点,故自己定义了一个torch.utils.data.Dataset的一个子类,来深入理解此类的内部对数据集读取的原理,到这数据集封装完成,最后就可以直接使用torch.utils.data.DataLoader类生成可迭代的数据集了!
- 将所有的数据集读入txt文本;
#本段代码为“k折交叉验证”提供了数据集中每张图片的的路径与标签信息
import glob
import os
import numpy as np
base_path = "/data2/houb/K_fold/data/"
image_path=[]
for i in os.listdir(base_path):image_path.append(os.path.join(base_path,i))
sum=0
img_path=[]
#遍历上面的路径,依次把信息追加到img_path列表中
for label,p in enumerate(image_path):image_dir=glob.glob(p+"/"+"*.JPG")#返回路径下的所有图片详细的路径sum+=len(image_dir)print(len(image_dir))for image in image_dir:img_path.append((image,str(label)))
#print(img_path[0])
print("%d 个图像信息已经加载到txt文本!!!"%(sum))
np.random.shuffle(img_path)
print(img_path[0])
file=open("shuffle_data.txt","w",encoding="utf-8")
for img in img_path:file.write(img[0]+','+img[1]+'\n')
file.close()写入后的文件内容:图片路径+对应label

- 为k折交叉验证做分割数据集的准备,把数据集分成K份,每一份都要作为一次测试集,剩下的作为训练集。代码如下(该函数将会被调用k次);
def get_k_fold_data(k, k1, image_dir):# 返回第i折交叉验证时所需要的训练和验证数据assert k > 1##K折交叉验证K大于1file = open(image_dir, 'r', encoding='utf-8',newline="")reader = csv.reader(file)imgs_ls = []for line in reader:imgs_ls.append(line)#print(len(imgs_ls))file.close()avg = len(imgs_ls) // kf1 = open('./train_k.txt', 'w',newline='')f2 = open('./test_k.txt', 'w',newline='')writer1 = csv.writer(f1)writer2 = csv.writer(f2)for i, row in enumerate(imgs_ls):#print(row)if (i // avg) == k1:writer2.writerow(row)else:writer1.writerow(row)f1.close()f2.close()- 数据集的读取
class MyDataset(torch.utils.data.Dataset): # 创建自己的类:MyDataset,这个类是继承的torch.utils.data.Datasetdef __init__(self, is_train,root): # 初始化一些需要传入的参数super(MyDataset, self).__init__()fh = open(root, 'r',newline='') # 按照传入的路径和txt文本参数,打开这个文本,并读取内容fh_reader = csv.reader(fh)imgs = [] # 创建一个名为img的空列表,一会儿用来装东西for line in fh_reader: # 按行循环txt文本中的内容#print(line)imgs.append((line[0], int(line[1]))) # 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定self.imgs = imgsself.is_train = is_trainif self.is_train:self.train_tsf = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(524, scale=(0.1, 1), ratio=(0.5, 2)),torchvision.transforms.ToTensor()])else:self.test_tsf = torchvision.transforms.Compose([torchvision.transforms.Resize(size=524),torchvision.transforms.CenterCrop(size=500),torchvision.transforms.ToTensor()])def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容feature, label = self.imgs[index] # fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息feature = Image.open(feature).convert('RGB') # 按照path读入图片from PIL import Image # 按照路径读取图片if self.is_train:feature = self.train_tsf(feature)else:feature = self.test_tsf(feature)return feature, labeldef __len__(self): # 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分return len(self.imgs)
3.封装:
train_data = MyDataset(is_train=True, root=train_k)
test_data = MyDataset(is_train=False, root=test_k)
4.使用torch.utils.data.DataLoader类对数据集进行可迭代化处理;
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=10, shuffle=True, num_workers=5)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=10, shuffle=True, num_workers=5)
至此,数据集处理工作到此完成!
网络模型部分
因为Efficient-Net网络的预训练模型下载不方便,不易于学习、故网络替换为了比较深的网络densenet161网络,使用非常简单,仅需要掌握对网络层的理解,以及微调的基本知识,就可以轻松上手。
1.首先要安装torchvision(pip install torchvision)
2.导入已经训练过的网络
from torchvision.models import densenet161
net = densenet161(pretrained=True, progress=True)
3.对下载后的网络模型进行调整,并加载优化器
net.classifier = nn.Linear(2208, 6)
output_params = list(map(id, net.classifier.parameters()))
feature_params = filter(lambda p: id(p) not in output_params, net.parameters())
lr = 0.01
optimizer = optim.SGD([{'params': feature_params},{'params': net.classifier.parameters(), 'lr': lr * 10}], lr=lr, weight_decay=0.001)
由于该网络是在很大的ImageNet数据集上预训练的,所以参数已经足够好,因此一般只需使用较小的学习率来微调这些参数,而fc中的随机初始化参数一般需要更大的学习率从头训练。
4.因为我是在Linux服务器上的跑的程序,用到了多块GPU,所以代码如下:
net=net.cuda()
net = torch.nn.DataParallel(net)
至此,网络层部分到此结束。
训练函数部分
def train(i,train_iter, test_iter, net, loss, optimizer, device, num_epochs):net = net.to(device)print("training on ", device)start = time.time()test_acc_max_l = []train_acc_max_l = []train_l_min_l=[]test_acc_max = 0for epoch in range(num_epochs): #迭代100次batch_count = 0train_l_sum, train_acc_sum, test_acc_sum, n = 0.0, 0.0, 0.0, 0for X, y in train_iter:X = X.to(device)y = y.to(device)y_hat = net(X)l = loss(y_hat, y)optimizer.zero_grad()l.backward()optimizer.step()train_l_sum += l.cpu().item()train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()n += y.shape[0]batch_count += 1#至此,每个epoches完成test_acc_sum= evaluate_accuracy(test_iter, net)train_l_min_l.append(train_l_sum/batch_count)train_acc_max_l.append(train_acc_sum/n)test_acc_max_l.append(test_acc_sum)print('fold %d epoch %d, loss %.4f, train acc %.3f, test acc %.3f'% (i+1,epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc_sum))###保存if test_acc_max_l[-1] > test_acc_max:test_acc_max = test_acc_max_l[-1]torch.save(net.module.state_dict(), "./K{:}_bird_model_best.pt".format(i+1))print("saving K{:}_bird_model_best.pt ".format(i))####选择测试准确率最高的那一个epoch对应的数据,打印并写入文件index_max=test_acc_max_l.index(max(test_acc_max_l))f = open("./results.txt", "a")if i==0:f.write("fold"+" "+"train_loss"+" "+"train_acc"+" "+"test_acc")f.write('\n' +"fold"+str(i+1)+":"+str(train_l_min_l[index_max]) + " ;" + str(train_acc_max_l[index_max]) + " ;" + str(test_acc_max_l[index_max]))f.close()print('fold %d, train_loss_min %.4f, train acc max%.4f, test acc max %.4f, time %.1f sec'% (i + 1, train_l_min_l[index_max], train_acc_max_l[index_max], test_acc_max_l[index_max], time.time() - start))return train_l_min_l[index_max],train_acc_max_l[index_max],test_acc_max_l[index_max]
k折交叉验证部分
def k_fold(k,image_dir,num_epochs,device,batch_size):train_k = './train_k.txt'test_k = './test_k.txt'#loss_acc_sum,train_acc_sum, test_acc_sum = 0,0,0Ktrain_min_l = []Ktrain_acc_max_l = []Ktest_acc_max_l = []for i in range(k):net, optimizer = get_net_optimizer()loss = get_loss()get_k_fold_data(k, i, image_dir)train_data = MyDataset(is_train=True, root=train_k)test_data = MyDataset(is_train=False, root=test_k)train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, num_workers=5)test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True, num_workers=5)# 修改train函数,使其返回每一批次的准确率,tarin_ls用列表表示loss_min,train_acc_max,test_acc_max=train(i,train_loader,test_loader, net, loss, optimizer, device, num_epochs)Ktrain_min_l.append(loss_min)Ktrain_acc_max_l.append(train_acc_max)Ktest_acc_max_l.append(test_acc_max)return sum(Ktrain_min_l)/len(Ktrain_min_l),sum(Ktrain_acc_max_l)/len(Ktrain_acc_max_l),sum(Ktest_acc_max_l)/len(Ktest_acc_max_l)
我对k折交叉验证的理解,只不过是再train训练函数外又套了k层循环,使训练次数由原来的一次变为k次!且每一次仍会对不同的训练集、测试集训练、测试num_epoches次!即相当于原来的train函数由只执行一次变为执行了k次,极为重要的是每一折都是独立的。
最终结果部分
第五折里的最后一部分

每一折里选取的标准是测试准确率最高的那一个epoch的相关信息
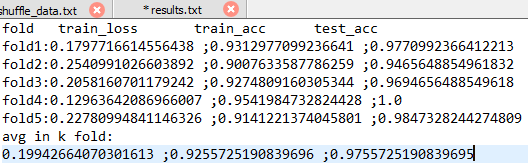
由于我们的数据集比较小而且相机的分辨率很高,再加上网络很深,可看到每一折的训练效果还可以。
解决问题的方法有很多,如果读者有任何问题以及不同的见解,欢迎留言评论,一起交流,一起进步!
最后感谢指导老师沈龙风老师,为我们小组提供细致的指导,以及提供的鸟类数据集,在深度学习成长的路上能得到良师的指导,感到很幸运!自己也会坚持下去的!希望21年在所研究的细粒度图像识别领域发表一篇论文。
本篇博客为作者原创,转载请注明出处,谢谢!
完整代码
附:完整代码
import os
from PIL import Image
import torch
import torchvision
import sys
from torchvision.models import densenet161, resnet50, resnet101,resnet18
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
from PIL import Image
from torch import optim
from torch import nn
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
from time import time
import time
import csvclass MyDataset(torch.utils.data.Dataset): # 创建自己的类:MyDataset,这个类是继承的torch.utils.data.Datasetdef __init__(self, is_train,root): # 初始化一些需要传入的参数super(MyDataset, self).__init__()fh = open(root, 'r',newline='') # 按照传入的路径和txt文本参数,打开这个文本,并读取内容fh_reader = csv.reader(fh)imgs = [] # 创建一个名为img的空列表,一会儿用来装东西for line in fh_reader: # 按行循环txt文本中的内容#print(line)imgs.append((line[0], int(line[1]))) # 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定self.imgs = imgsself.is_train = is_trainif self.is_train:self.train_tsf = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(524, scale=(0.1, 1), ratio=(0.5, 2)),torchvision.transforms.ToTensor()])else:self.test_tsf = torchvision.transforms.Compose([torchvision.transforms.Resize(size=524),torchvision.transforms.CenterCrop(size=500),torchvision.transforms.ToTensor()])def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容feature, label = self.imgs[index] # fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息feature = Image.open(feature).convert('RGB') # 按照path读入图片from PIL import Image # 按照路径读取图片if self.is_train:feature = self.train_tsf(feature)else:feature = self.test_tsf(feature)return feature, labeldef __len__(self): # 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分return len(self.imgs)def get_k_fold_data(k, k1, image_dir):# 返回第i折交叉验证时所需要的训练和验证数据assert k > 1##K折交叉验证K大于1file = open(image_dir, 'r', encoding='utf-8',newline="")reader = csv.reader(file)imgs_ls = []for line in reader:imgs_ls.append(line)#print(len(imgs_ls))file.close()avg = len(imgs_ls) // kf1 = open('./train_k.txt', 'w',newline='')f2 = open('./test_k.txt', 'w',newline='')writer1 = csv.writer(f1)writer2 = csv.writer(f2)for i, row in enumerate(imgs_ls):#print(row)if (i // avg) == k1:writer2.writerow(row)else:writer1.writerow(row)f1.close()f2.close()def k_fold(k,image_dir,num_epochs,device,batch_size):train_k = './train_k.txt'test_k = './test_k.txt'#loss_acc_sum,train_acc_sum, test_acc_sum = 0,0,0Ktrain_min_l = []Ktrain_acc_max_l = []Ktest_acc_max_l = []for i in range(k):net, optimizer = get_net_optimizer()loss = get_loss()get_k_fold_data(k, i, image_dir)train_data = MyDataset(is_train=True, root=train_k)test_data = MyDataset(is_train=False, root=test_k)train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, num_workers=5)test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True, num_workers=5)# 修改train函数,使其返回每一批次的准确率,tarin_ls用列表表示loss_min,train_acc_max,test_acc_max=train(i,train_loader,test_loader, net, loss, optimizer, device, num_epochs)Ktrain_min_l.append(loss_min)Ktrain_acc_max_l.append(train_acc_max)Ktest_acc_max_l.append(test_acc_max)return sum(Ktrain_min_l)/len(Ktrain_min_l),sum(Ktrain_acc_max_l)/len(Ktrain_acc_max_l),sum(Ktest_acc_max_l)/len(Ktest_acc_max_l)def evaluate_accuracy(data_iter, net, device=None):if device is None and isinstance(net, torch.nn.Module):# 如果没指定device就使用net的devicedevice = list(net.parameters())[0].deviceacc_sum, n = 0.0, 0with torch.no_grad():for X, y in data_iter:if isinstance(net, torch.nn.Module):net.eval() # 评估模式, 这会关闭dropoutacc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()net.train() # 改回训练模式else:if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数# 将is_training设置成Falseacc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()else:acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()n += y.shape[0]return acc_sum / ndef train(i,train_iter, test_iter, net, loss, optimizer, device, num_epochs):net = net.to(device)print("training on ", device)start = time.time()test_acc_max_l = []train_acc_max_l = []train_l_min_l=[]test_acc_max = 0for epoch in range(num_epochs): #迭代100次batch_count = 0train_l_sum, train_acc_sum, test_acc_sum, n = 0.0, 0.0, 0.0, 0for X, y in train_iter:X = X.to(device)y = y.to(device)y_hat = net(X)l = loss(y_hat, y)optimizer.zero_grad()l.backward()optimizer.step()train_l_sum += l.cpu().item()train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()n += y.shape[0]batch_count += 1#至此,每个epoches完成test_acc_sum= evaluate_accuracy(test_iter, net)train_l_min_l.append(train_l_sum/batch_count)train_acc_max_l.append(train_acc_sum/n)test_acc_max_l.append(test_acc_sum)print('fold %d epoch %d, loss %.4f, train acc %.3f, test acc %.3f'% (i+1,epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc_sum))###保存if test_acc_max_l[-1] > test_acc_max:test_acc_max = test_acc_max_l[-1]torch.save(net.module.state_dict(), "./K{:}_bird_model_best.pt".format(i+1))print("saving K{:}_bird_model_best.pt ".format(i))####选择测试准确率最高的那一个epoch对应的数据,打印并写入文件index_max=test_acc_max_l.index(max(test_acc_max_l))f = open("./results.txt", "a")if i==0:f.write("fold"+" "+"train_loss"+" "+"train_acc"+" "+"test_acc")f.write('\n' +"fold"+str(i+1)+":"+str(train_l_min_l[index_max]) + " ;" + str(train_acc_max_l[index_max]) + " ;" + str(test_acc_max_l[index_max]))f.close()print('fold %d, train_loss_min %.4f, train acc max%.4f, test acc max %.4f, time %.1f sec'% (i + 1, train_l_min_l[index_max], train_acc_max_l[index_max], test_acc_max_l[index_max], time.time() - start))return train_l_min_l[index_max],train_acc_max_l[index_max],test_acc_max_l[index_max]def get_net_optimizer():net = densenet161(pretrained=True, progress=True)net.classifier = nn.Linear(2208, 6)output_params = list(map(id, net.classifier.parameters()))feature_params = filter(lambda p: id(p) not in output_params, net.parameters())lr = 0.01optimizer = optim.SGD([{'params': feature_params},{'params': net.classifier.parameters(), 'lr': lr * 10}], lr=lr, weight_decay=0.001)net = net.cuda()net = torch.nn.DataParallel(net)print(net)return net,optimizerdef get_loss():loss = torch.nn.CrossEntropyLoss()return lossif __name__ == '__main__':batch_size=6k=5image_dir='./shuffle_data.txt'num_epochs=100loss_k,train_k, valid_k=k_fold(k,image_dir,num_epochs,device,batch_size)f=open("./results.txt","a")f.write('\n'+"avg in k fold:"+"\n"+str(loss_k)+" ;"+str(train_k)+" ;"+str(valid_k))f.close()print('%d-fold validation: min loss rmse %.5f, max train rmse %.5f,max test rmse %.5f' % (k,loss_k,train_k, valid_k))这篇关于Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





