本文主要是介绍Spark项目实战-卡口流量统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、卡口介绍

卡口摄像头正对车道安装,拍摄正面照片。
功能:抓拍正面特征
这种摄像头多安装在国道、省道、高速公路的路段上、或者城区和郊区交接的主要路口,用来抓拍超速、进出城区车辆等行为。它进行的是车辆正面抓拍,可以清晰地看到驾驶员及前台乘客的面容及行为。有一些则是专门摄像车的尾部,所以当车开过此类测速摄像头后不要马上提速,建议至少要跑出500米后再提速。这就是有人认为的没有超速为什么也照样被拍的原因。此类摄像头应该是集成照明设备。

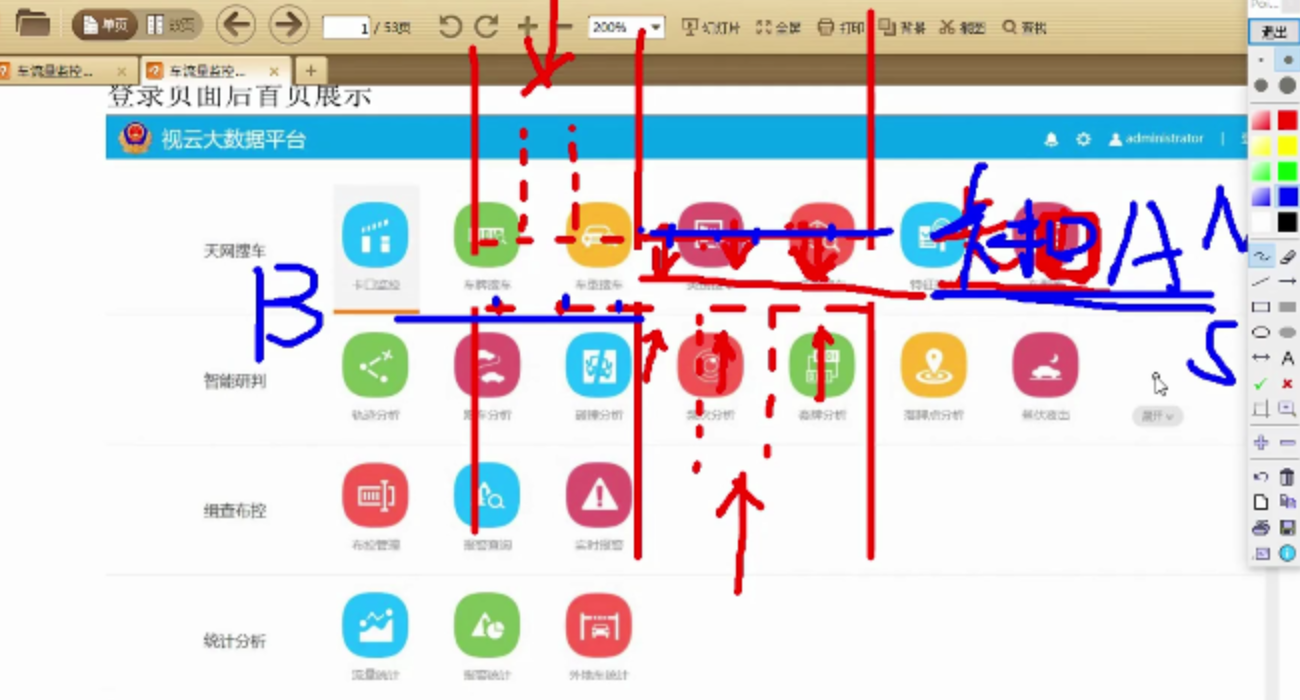
卡口:三车道、三个摄像头共同组成卡口A
二、表介绍
monitor_flow_action
| 日期 | 卡口ID | 摄像头编号 | 车牌号 | 拍摄时间 | 车速 | 道路ID | 区域ID |
|---|---|---|---|---|---|---|---|
| date | monitor_id | camera_id | car | action_time | speed | road_id | area_id |
| 2018-11-05 | 0005 | 33745 | 京C60159 | 2018-11-05 20:43:47 | 198 | 36 | 04 |
monitor_camera_info
| 卡扣号 | 摄像头编号 |
|---|---|
| monitor_id | camera_id |
| 0006 | 80522 |
| 0006 | 29268 |
areaId2AreaInfoRDD
| area_id | area_name |
|---|---|
| 区域ID | 区域Name |
tmp_car_flow_basic
= areaId2AreaInfoRDD + monitor_flow_action
| 卡口ID | 车牌号 | 道路ID | 区域ID | 区域Name |
|---|---|---|---|---|
| monitor_id | car | road_id | area_id | area_name |
| 0005 | 京C60159 | 36 | 04 |
tmp_area_road_flow_count
| area_name | road_id | car_count | monitor_infos | |
|---|---|---|---|---|
| 区域ID | 道路ID | 车count | 详情 | |
| 04 | 36 | 50 | 0006=20|0002=30 |
areaTop3Road
| area_name | road_id | car_count | monitor_infos | flow_level |
|---|---|---|---|---|
| 区域ID | 道路ID | 车count | 详情 | 流量等级 |
| 04 | 36 | 50 | 0006=20|0002=30 | D |
三、分析需求
3.1 卡口正常数、异常数
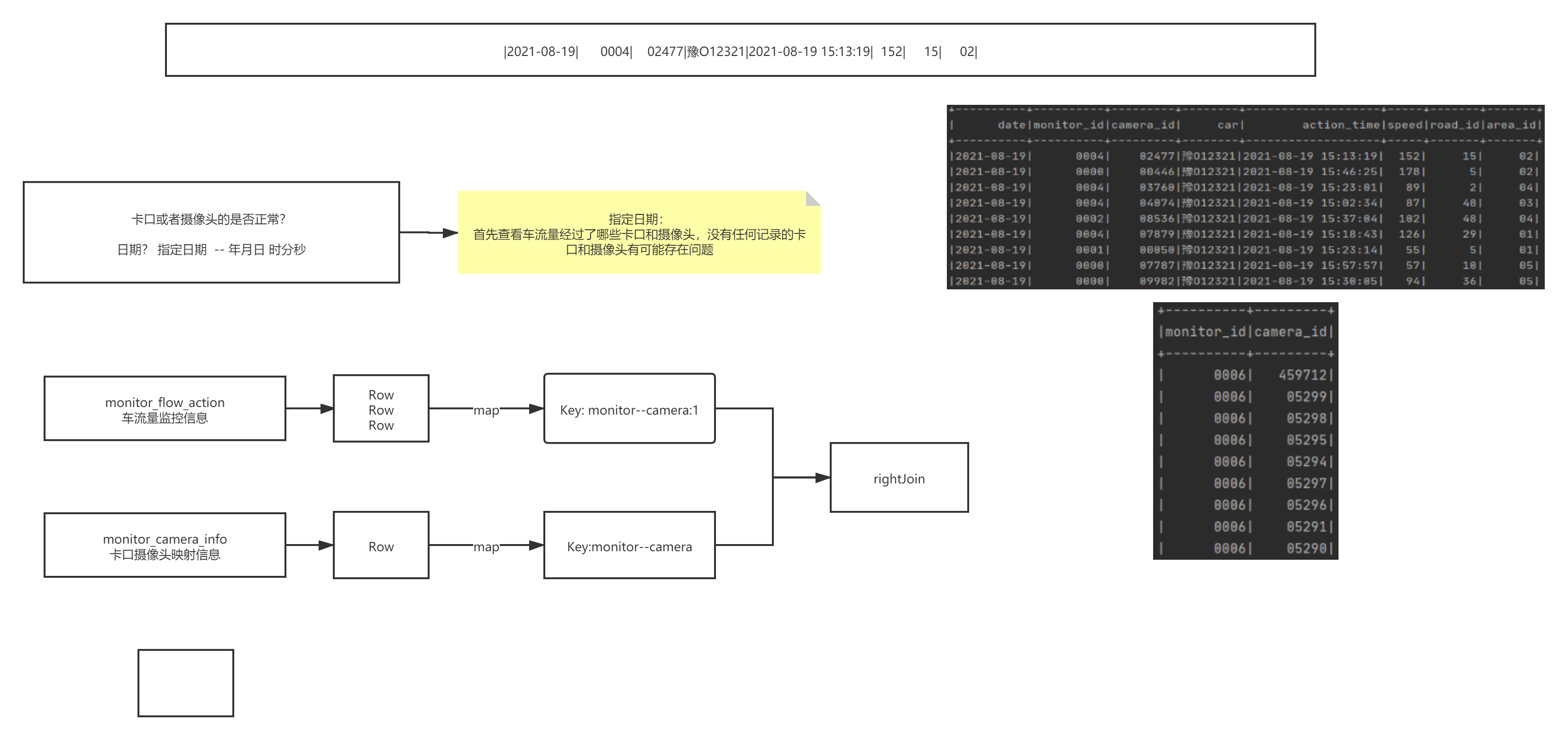
统计异常摄像头的思路:流量表 rightJoin 摄像头表,过滤流量表为空的
//------------------------------统计卡口摄像头通过的车辆的合计----------------------------
//| 2023-10-24 | 0005 | 33745 | 京C60159 | 2018-11-05 20:43:47 | 198 | 36 | 04 |
val flowDF:DataFrame = sparkSession.sql("select * from monitor_flow_action where data = '2023-10-24' ")//((0005:33745),1)
val mcRdd: RDD[(String, Int)] = flowDF.map(e => Tuple2((e.getString(1) + ":" + e.getString(2)),1)).rdd//((0005:33745),99)
val flowRdd: RDD[(String, Int)] = mcRdd.reduceByKey(_+_)//------------------------------统计卡口所有的摄像头----------------------------
//| 0006 | 29268 |
val cameraDF:DataFrame = sparkSession.sql("select * from monitor_camera_info")//((0006,29268),1)
val cameraRdd: RDD[(String, Int)] = cameraDF.map(e => ((e.getString(0) + ":" + e.getString(1)),1)).rdd//------------------------------合并车流量和摄像头RDD----------------------------
val allRDD: RDD[(String, (Option[Int], Int))] = flowRdd.rightOuterJoin(cameraRdd).filter(e => e._2._1.isEmpty)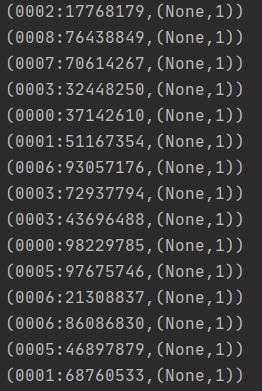
3.2 camera 正常数、异常数、详情
//---------------------开始操作车流量信息,假设任务编号为1 日期参数为今天val flowInfo: RDD[(String, String)] = sparkSession.sql("select * from monitor_flow_action where date = '2021-08-23' ").rdd.map(row => (row.getString(1), row)).groupByKey().map(ele => {val monitorId: String = ele._1val cameraIdSet = new mutable.HashSet[String]()ele._2.foreach(row => cameraIdSet.add(row.getString(2)))//拼接字符串val info: String = Constants.FIELD_MONITOR_ID + "=" + monitorId + "|" + Constants.FIELD_AREA_ID + "=浦东新区|" + Constants.FIELD_CAMERA_IDS + "=" + cameraIdSet.mkString("-") + "|" + Constants.FIELD_CAMERA_COUNT + "=" + cameraIdSet.size + "|" + Constants.FIELD_CAR_COUNT + "=" + ele._2.size//返回结果(monitorId, info)})//-----------------------开始操作摄像头数据val monitorInfo: RDD[(String, String)] = sparkSession.sql("select * from monitor_camera_info").rdd.map(row => (row.getString(0), row.getString(1))).groupByKey().map(ele => {val monitorId: String = ele._1//拼接字符串val info: String = Constants.FIELD_CAMERA_IDS + "=" + ele._2.toList.mkString("-") + "|" + Constants.FIELD_CAMERA_COUNT + "=" + ele._2.size//返回结果(monitorId, info)//-----------------------将数据Join到一起monitorInfo.leftOuterJoin(flowInfo).foreach(println)})
3.3 车流量最多的TopN卡口
//开始计算val fRdd: RDD[Row] = sparkSession.sql("select * from monitor_flow_action where date = '2021-08-23' ").rddfRdd.map(row => (row.getString(7) + "_" + row.getString(6) + "&" + (Math.random() * 30 + 10).toInt, 1)).reduceByKey(_ + _).map(ele => {val area_road_random = ele._1val count = ele._2(area_road_random.split("_")(0), area_road_random.split("_")(1).split("&")(0) + "_" + count)}).groupByKey().map(ele => {val map = new mutable.HashMap[String, Int]()ele._2.foreach(e => {val key = e.split("_")(0)val value = e.split("_")(1).toIntmap.put(key, map.get(key).getOrElse(0) + value)})"区划【" + ele._1 + "】车辆最多的三条道路分别为:" + map.toList.sortBy(_._2).takeRight(3).reverse.mkString("-")}).foreach(println)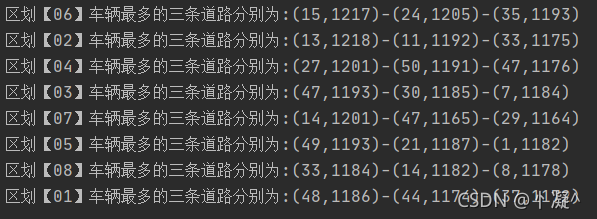
3.4 区域各路速度
随机抽取N个车辆信息,对这些数据可以进行多维度分析(因为随机抽取出来的N个车辆信息可以很权威的代表整个区域的车辆)
val sRdd: RDD[Row] = sparkSession.sql("select * from monitor_flow_action where date = '2021-08-23' ").rddsRdd.map(e=>{((e.getString(7),e.getString(6)),e.getString(5).toInt)}).groupByKey().map(e=>{val list: List[Int] = e._2.toListval i: Int = list.sum/list.size(e._1._1,(e._1._2,i))}).groupByKey().map(e=>{val tuples = e._2.toList.sortBy(_._2).reverse.take(3)var strBui: StringBuilder = new StringBuilderfor (i <- tuples ){val str: String = i._1 + "-均速度为:" + i._2strBui.append(">>>"+str)}(e._1,strBui)}).foreach(println)
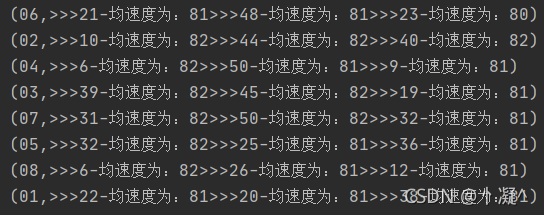
3.5 区域中高速数量
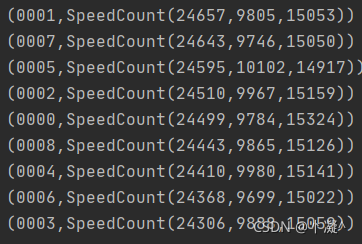
object Hello04MonitorTopNSpeed {def main(args: Array[String]): Unit = {val sparkSession = ContextUtils.getSparkSession("Hello04MonitorTopNSpeed")MockDataUtil.mock2view(sparkSession)//---------------------开始操作车流量信息,假设任务编号为1 日期参数为今天val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-20' ").rddval monitor2speedRDD: RDD[(String, Iterable[String])] = flowRdd.map(row => (row.getString(1), row.getString(5))).groupByKey()val speedCount2monitorRDD: RDD[(SpeedCount, String)] = monitor2speedRDD.map(ele => {//获取卡口号val monitorId: String = ele._1//声明一个Map[0,60,100,120]var high = 0;var normal = 0;var low = 0;//获取所有的速度的车辆技术ele._2.foreach(speed => {//判断速度if (speed.toInt > 100) {high += 1} else if (speed.toInt > 60) {normal += 1} else {low += 1}})//创建速度对象(SpeedCount(high, normal, low), monitorId)})speedCount2monitorRDD.sortByKey(false).map(x => (x._2, x._1)).foreach(println)}
}case class SpeedCount(high: Int, normal: Int, low: Int) extends Ordered[SpeedCount] with KryoRegistrator {override def compare(that: SpeedCount): Int = {var result = this.high - that.highif (result == 0) {result = this.normal - that.normalif (result == 0) {result = this.low - that.low}}return result}override def registerClasses(kryo: Kryo): Unit = {kryo.register(SpeedCount.getClass)}
}
3.6 指定卡口对应卡口车辆轨迹
def main(args: Array[String]): Unit = {val sparkSession = ContextUtils.getSparkSession("Hello04MonitorTopNSpeed")MockDataUtil.mock2view(sparkSession)//获取数据val area01Rdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' and area_id = '01' ").rddval area02Rdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' and area_id = '02' ").rddval area01CarRdd = area01Rdd.map(row => (row.getString(3), row.getString(7))).groupByKey()val area02CarRdd = area02Rdd.map(row => (row.getString(3), row.getString(7))).groupByKey()area01CarRdd.join(area02CarRdd).foreach(println)}

3.7 行车轨迹
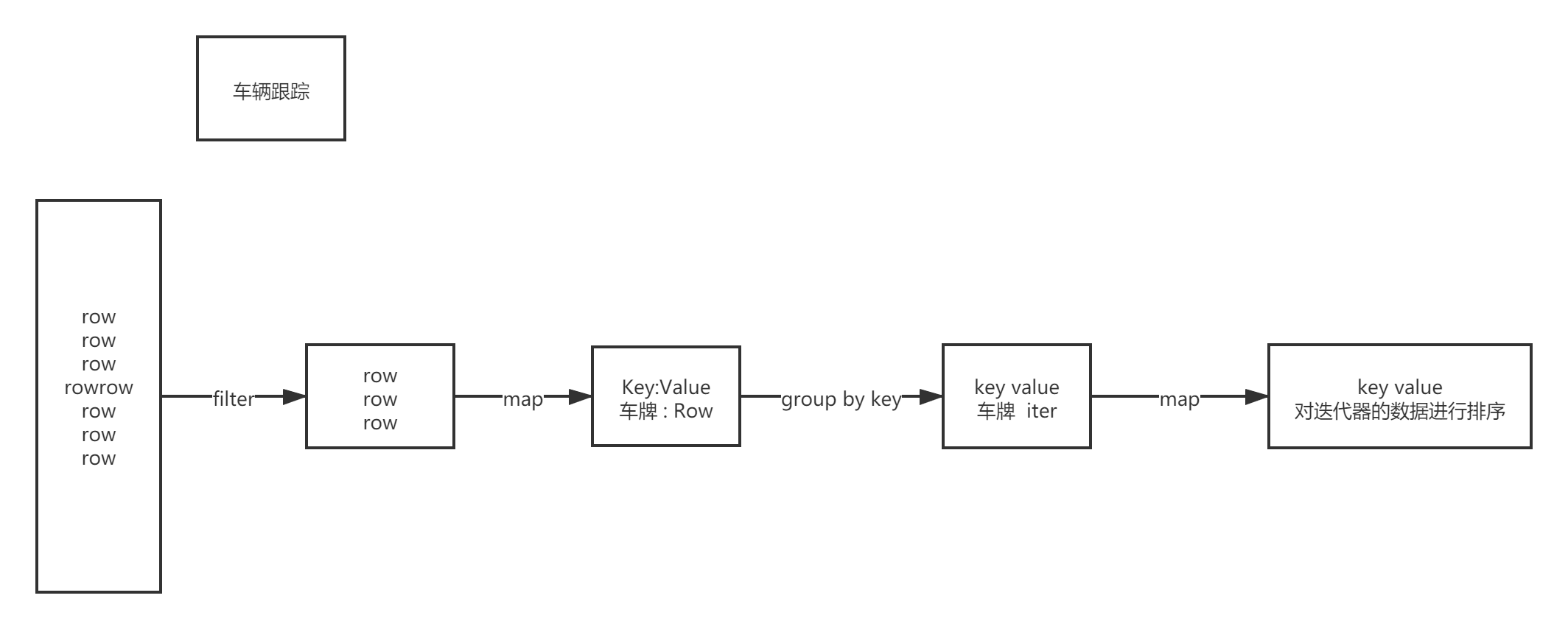
def main(args: Array[String]): Unit = { val sparkSession = ContextUtils.getSparkSession("AreaCar") MockDataUtil.mock2view(sparkSession)//查询 车子行驶轨迹 跟车分析 val c1Rdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd val carRdd: RDD[(String, StringBuilder)] = c1Rdd.map(e => { (e.getString(3), (e.getString(4), e.getString(6), e.getString(2))) }).groupByKey() .map(e => { val tuples: List[(String, String, String)] = e._2.toList.sortBy(_._1) val list = new StringBuilder for (i <- tuples) { //println(i) val str: String = i._2 + ":" + i._3 list.append(str + "-") } (e._1, list) }) //carRdd.foreach(println)
}
3.9 车辆套牌
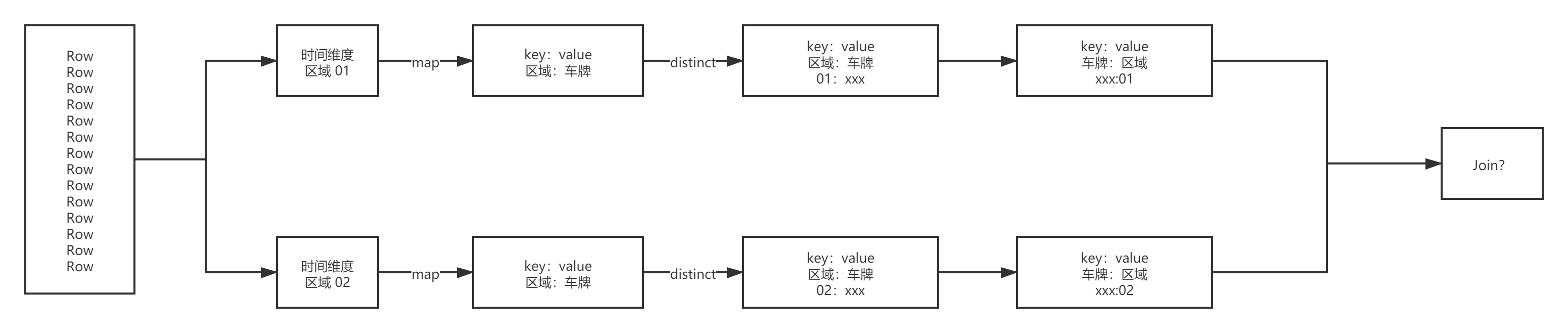
def main(args: Array[String]): Unit = {val sparkSession = ContextUtils.getSparkSession("AreaCar")MockDataUtil.mock2view(sparkSession)
//假设任何的卡口距离都是 10分钟车程 ,如果同一分钟出现在不同的卡口就怀疑是套牌val deckRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdddeckRdd.map(e => {val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")(e.getString(3), (dateFormat.parse(e.getString(4)),e.getString(1)))}).groupByKey(1).map(e => {val list: List[(util.Date, String)] = e._2.toList.sortBy(x=>x._1)var bool = falsevar d: util.Date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2021-08-23 00:00:00")var mid="?"for (i <- list) {if (d.getTime - i._1.getTime < 600000 && i._2!=mid )bool = trued = i._1mid=i._2}(e._1, bool)}).filter(f => f._2).foreach(println)}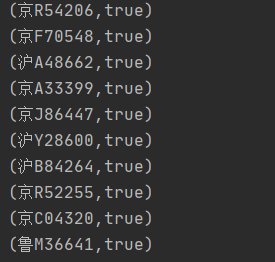
3.10 车辆抽样-蓄水池抽样法
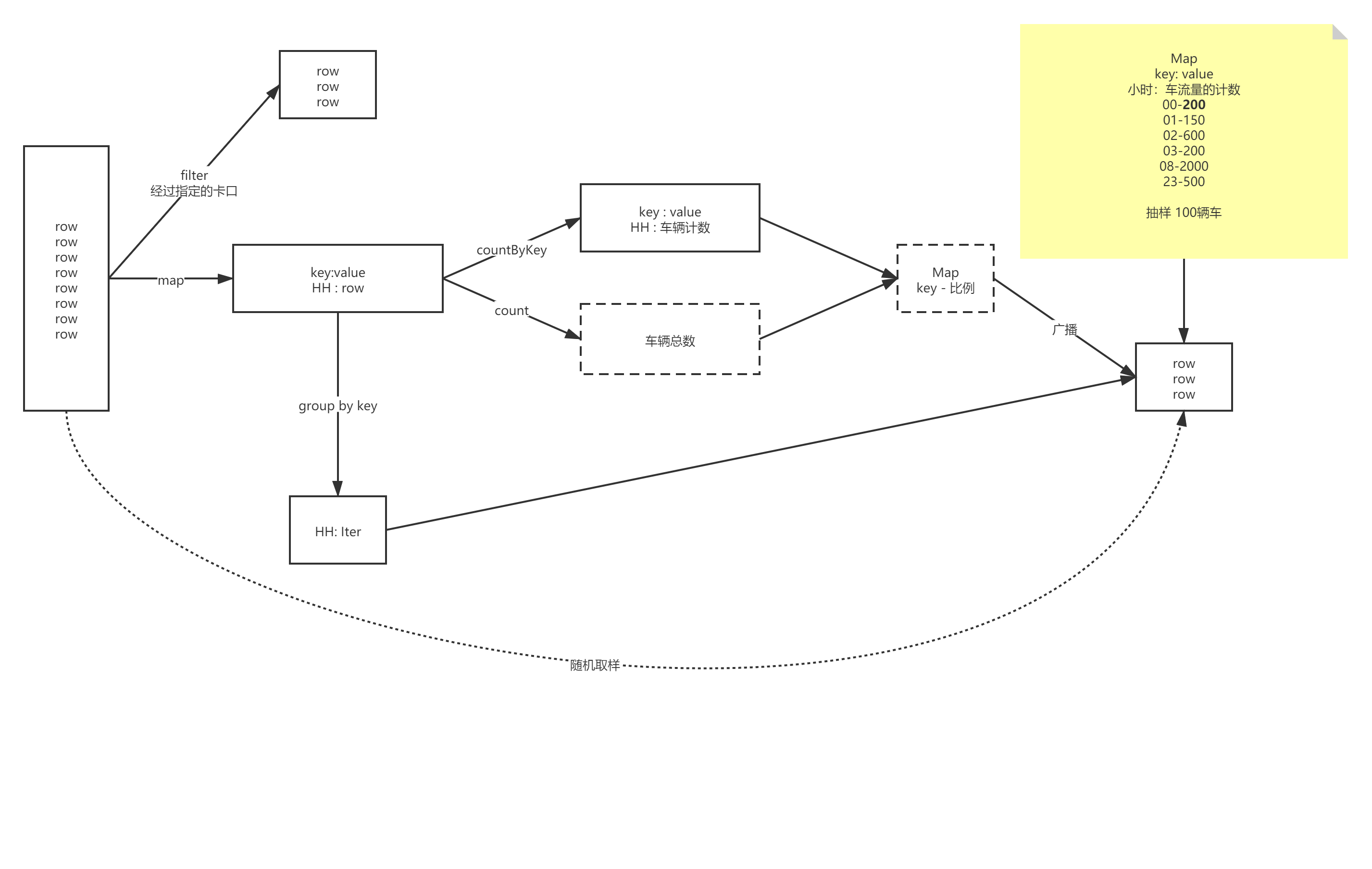
def main(args: Array[String]): Unit = {val sparkSession = ContextUtils.getSparkSession("Hello04MonitorTopNSpeed")MockDataUtil.mock2view(sparkSession)//获取数据val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-21' ").rdd//yyyy-MM-dd_HH , rowval hourRDD: RDD[(String, Row)] = flowRdd.map(row => (DateUtils.getDateHour(row.getString(4)), row))//车流量的总数,并进行广播val flowAllCount: Long = hourRDD.count()val broadcastFlowAllCount: Broadcast[Long] = sparkSession.sparkContext.broadcast(flowAllCount)//计算每个小时的比例 并进行广播val hourRatio: collection.Map[String, Double] = hourRDD.countByKey().map(e => {(e._1, e._2 * 1.0 / broadcastFlowAllCount.value)})val broadcastHourRatio: Broadcast[collection.Map[String, Double]] = sparkSession.sparkContext.broadcast(hourRatio)//开始进行抽样val sampleRDD: RDD[Row] = hourRDD.groupByKey().flatMap(ele => {val hour: String = ele._1val list: List[Row] = ele._2.iterator.toList//计算本时段要抽样的数据量val sampleRatio: Double = broadcastHourRatio.value.get(hour).getOrElse(0)val sampleNum: Long = Math.round(sampleRatio * 100)//开始进行取样(蓄水池抽样)val sampleList: ListBuffer[Row] = new ListBuffer[Row]()sampleList.appendAll(list.take(sampleNum.toInt))for (i <- sampleNum until list.size) {//随机生成一个数字val num = (Math.random() * list.size).toIntif (num < sampleNum) {sampleList.update(num, list(i.toInt))}}sampleList})sampleRDD.foreach(println)}
3.11 道路转换率
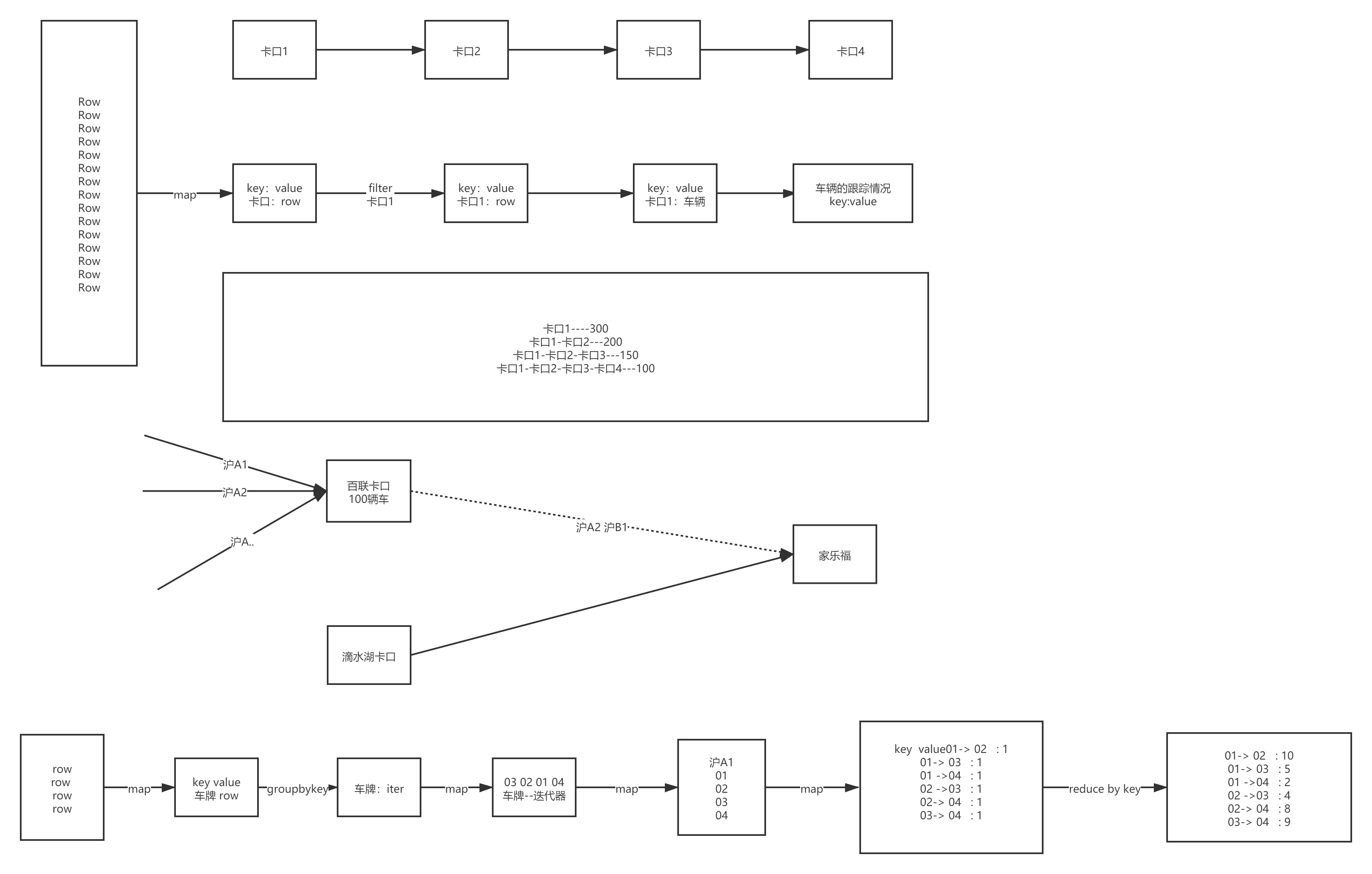
def main(args: Array[String]): Unit = {//创建会话val sparkSession = ContextUtils.getSparkSession("Hello07MonitorConvertRatio")MockDataUtil.mock2view(sparkSession)//开始计算val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd//计算每个卡口的总通车量val monitorCountMap: collection.Map[String, Long] = flowRdd.map(row => (row.getString(1), row)).countByKey()//计算卡口到卡口的通行率val sortRDD: RDD[(String, List[Row])] = flowRdd.map(row => (row.getString(3), row)).groupByKey().map(ele => (ele._1, ele._2.iterator.toList.sortBy(_.getString(4))))val m2mMap: collection.Map[String, Long] = sortRDD.flatMap(ele => {//存放映射关系val map: mutable.HashMap[String, Int] = mutable.HashMap[String, Int]()val list: List[Row] = ele._2.toListfor (i <- 0 until list.size; j <- i + 1 until list.size) {//拼接Keyval key = list(i).getString(1) + "->" + list(j).getString(1)map.put(key, map.get(key).getOrElse(0) + 1);}//返回结果map.toList}).countByKey()//开始进行计算m2mMap.foreach(ele => {println("卡口[" + ele._1 + "]的转换率为:" + ele._2.toDouble / monitorCountMap.get(ele._1.split("->")(0)).get)})
}
3.12 区域通过的TopN卡口
def main(args: Array[String]): Unit = {//创建会话val sparkSession = ContextUtils.getSparkSession("Hello07MonitorConvertRatio")MockDataUtil.mock2view(sparkSession)//开始计算val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd//开始计算flowRdd.map(row => (row.getString(7) + "_" + row.getString(6) + "&" + (Math.random() * 30 + 10).toInt, 1)).reduceByKey(_ + _).map(ele => {val area_road_random = ele._1val count = ele._2(area_road_random.split("_")(0), area_road_random.split("_")(1).split("&")(0) + "_" + count)}).groupByKey().map(ele => {val map = new mutable.HashMap[String, Int]()ele._2.foreach(e => {val key = e.split("_")(0)val value = e.split("_")(1).toIntmap.put(key, map.get(key).getOrElse(0) + value)})"区划【" + ele._1 + "】车辆最多的三条道路分别为:" + map.toList.sortBy(_._2).takeRight(3).reverse.mkString("-")}).foreach(println)
}areaId2DetailInfos"SELECT ""monitor_id,""car,""road_id,""area_id ""FROM traffic.monitor_flow_action ""WHERE date >= '"startDate"'""AND date <= '"endDate"'"areaId2AreaInfoRDDareaid areanametmp_car_flow_basic = monitor_flow_action areaId2AreaInfoRDDmonitor_id car road_id area_id area_name 统计各个区域各个路段车流量的临时表area_name road_id car_count monitor_infos海淀区 01 100 0001=20|0002=30|0003=50注册成临时表tmp_area_road_flow_count"SELECT ""area_name,""road_id,""count(*) car_count,"//group_concat_distinct 统计每一条道路中每一个卡扣下的车流量"group_concat_distinct(monitor_id) monitor_infos "//0001=20|0002=30"FROM tmp_car_flow_basic ""GROUP BY area_name,road_id"0001=20|0002=30insert into areaTop3Road"SELECT ""area_name,""road_id,""car_count,""monitor_infos, ""CASE ""WHEN car_count > 170 THEN 'A LEVEL' ""WHEN car_count > 160 AND car_count <= 170 THEN 'B LEVEL' ""WHEN car_count > 150 AND car_count <= 160 THEN 'C LEVEL' ""ELSE 'D LEVEL' ""END flow_level "
"FROM (""SELECT ""area_name,""road_id,""car_count,""monitor_infos,""row_number() OVER (PARTITION BY area_name ORDER BY car_count DESC) rn ""FROM tmp_area_road_flow_count "") tmp "
"WHERE rn <=3"这篇关于Spark项目实战-卡口流量统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








