本文主要是介绍mysql文档--innodb中的重头戏--事务隔离级别!!!!--举例学习--现象演示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阿丹:
先要说明一点就是在网上现在查找的mysql中的事务隔离级别其实都是在innodb中的事务隔离级别。因为在mysql的5.5.5版本后myisam被innodb打败,从此innodb成为了mysql中的默认存储引擎。所以在网上查找的事务隔离级别基本上都是innodb的。并且支持事务隔离级别也是innodb的主要特点。
本文章简介:
我会从概念->具体使用案例->事务业务场景来对这几种事务隔离级别进行分析。
事务隔离级别有那些?
MySQL中InnoDB存储引擎支持多个事务隔离级别来控制并发操作对数据的可见性和一致性。以下是MySQL InnoDB存储引擎支持的事务隔离级别:
-
读未提交(Read Uncommitted):
- 最低的隔离级别,允许一个事务读取另一个事务尚未提交的数据。这可能导致"脏读"(Dirty Read)问题,即读取到未经确认的临时数据。
-
读已提交(Read Committed):
- Oracle默认的隔离级别,每个查询都会在事务执行时获取当前可见的数据。这样可以避免脏读,但可能会导致"不可重复读"(Non-repeatable Read)问题,即同一个查询在多次执行时读取到不同的数据。
-
可重复读(Repeatable Read):
- mysql中的默认事务隔离级别,确保在事务执行期间读取到的数据始终保持一致。这可以通过在事务开始时锁定已读取的数据来实现,以防止其他并发事务对数据进行修改。这样可以避免脏读和不可重复读,但可能导致"幻读"(Phantom Read)问题,即在同一查询中读取到了不同的行。
-
串行化(Serializable):
- 最高的隔离级别,确保每个事务串行执行,避免了脏读、不可重复读和幻读问题。这是通过在事务执行期间对数据进行加锁来实现的,以防止其他事务对数据进行修改和插入。
可以使用SET TRANSACTION ISOLATION LEVEL语句来设置事务的隔离级别。每个隔离级别在处理并发操作和数据一致性之间存在权衡。更高的隔离级别通常会导致更多的锁竞争和性能开销,因此应根据具体业务需求选择适当的隔离级别。
在MySQL中,默认的事务隔离级别是可重复读(REPEATABLE READ)。这意味着在一个事务中,查询会看到事务开始时的一致数据状态,而不会受到其他并发事务的修改影响,除非使用了显式的锁机制。
而在Oracle中,默认的事务隔离级别是读已提交(READ COMMITTED)。这意味着查询会看到其他事务提交后的数据变化,而不会看到未提交的数据。Oracle还支持更高级别的隔离级别,如可重复读(REPEATABLE READ)和序列化(SERIALIZABLE),可以根据需要进行设置和调整。
事务隔离级别要解决的核心问题以及业务场景是什么?
需要解决的核心问题:
事务隔离级别是为了解决并发访问数据库时可能出现的数据一致性问题而引入的。在多个并发事务同时读写数据库时,如果没有正确的隔离机制,可能会导致以下问题:
-
脏读(Dirty Read):一个事务读取了另一个未提交的事务所做的修改,导致读取到不一致的数据。
-
不可重复读(Non-repeatable Read):一个事务在多次读取同一数据时,由于其他并发事务的更新操作,导致每次读取的数据不一致。
-
幻读(Phantom Read):一个事务在多次执行同一查询时,由于其他并发事务的插入或删除操作,导致每次执行返回的结果集不一致。
通过定义事务隔离级别,可以控制事务之间的相互影响,从而解决并发访问所带来的一致性问题。不同的隔离级别提供了不同的数据可见性和保护程度。
较低的隔离级别可以提高并发性能,但可能导致脏读、不可重复读和幻读等问题。而较高的隔离级别可以提供更高的数据一致性和隔离性,但可能导致更多的锁竞争和性能开销。
因此,事务隔离级别的选择应该根据具体业务需求和数据一致性的要求来确定。在高并发场景下,需要仔细评估隔离级别对性能和并发性的影响,以找到合适的平衡点。
业务场景:
举例说明这些事务隔离级别业务场景
银行转账:在银行系统中,多个用户同时发起转账操作,需要保证每笔转账过程的一致性。这涉及到脏读的问题,如果没有适当的隔离级别,可能会导致转账过程中读取不正确的账户余额或产生不一致的交易记录。
- 对应问题:脏读。如果隔离级别不合适,用户A和用户B同时读取用户C的账户余额,并进行转账操作,导致重复转账或转账超额的问题。
订单处理:在电商平台上,多个用户同时下单并支付可能导致数据的不一致性。通过合适的隔离级别,可以确保每个订单的处理是独立的,避免并发情况下出现订单信息的混乱。
- 对应问题:幻读。如果隔离级别不合适,两个用户同时下单购买同一商品,可能导致系统分配相同商品的库存给两个用户,最终导致库存量不正确或订单信息混乱。
数据分析:在进行数据分析时,需要保证读取到的数据的一致性,避免其他并发事务的修改对分析结果造成影响。
- 对应问题:不可重复读。如果隔离级别不合适,可能导致分析过程中读取到不一致的点击数据,最终影响广告活动的准确性和决策结果。
在这些示例中,脏读问题会影响数据的一致性,不可重复读问题会导致读取到的数据不一致,而幻读问题则涉及到并发事务的插入或删除操作导致结果集不一致。
事务隔离级别分别对应解决了那些问题?
innodb中的四种隔离级别分别解决了这些问题中的那些对应的问题?请对应说明
InnoDB是MySQL数据库中的一种存储引擎,它提供了四种不同的隔离级别,分别是读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。这些隔离级别旨在解决并发访问数据库时可能出现的一些问题。
-
读未提交(Read Uncommitted)隔离级别允许一个事务读取另一个事务尚未提交的未确认数据。这可能导致脏读(Dirty Read),即读取到了其他事务尚未提交的数据。这个隔离级别的目的不是为了解决任何问题,只是为了展示开发者在这种级别下可能面临的问题。
-
读已提交(Read Committed)隔离级别解决了脏读的问题。它确保一个事务只能读取到其他事务已经提交的数据。在这个级别下,事务只能查看到已经提交的数据,而不会看到其他事务尚未提交的数据。
-
可重复读(Repeatable Read)隔离级别解决了脏读和不可重复读(Non-Repeatable Read)的问题。在可重复读级别下,事务在整个事务期间看到的数据都保持一致,即使其他事务对数据进行了更改。其他事务对同一数据的修改只有在当前事务提交后才能被看到。
-
串行化(Serializable)隔离级别提供了最高级别的隔离。它通过对每个事务进行串行化执行来解决所有并发问题。这意味着每个事务都会完全独立地执行,没有任何并发冲突。这种级别确保了最高的数据完整性,但同时也对系统的性能有一定的影响,因为它会导致事务之间的相互等待。
使用代码案例来说明分析每个事物隔离级别的底层以及工作流程
为了方便我们研究我们现在去创建一个新的表并添加一些数据

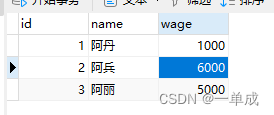
我将表的sql提供一下,如果需要的可以跟着步骤一起实践一下。
/*Navicat Premium Data TransferSource Server : 1Source Server Type : MySQLSource Server Version : 50730Source Host : localhost:3306Source Schema : demoTarget Server Type : MySQLTarget Server Version : 50730File Encoding : 65001Date: 08/09/2023 19:40:36
*/SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for t_demo
-- ----------------------------
DROP TABLE IF EXISTS `t_demo`;
CREATE TABLE `t_demo` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`wage` int(11) NULL DEFAULT NULL COMMENT '工资',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of t_demo
-- ----------------------------
INSERT INTO `t_demo` VALUES (1, '阿丹', 1000);
INSERT INTO `t_demo` VALUES (2, '阿兵', 6000);
INSERT INTO `t_demo` VALUES (3, '阿丽', 5000);SET FOREIGN_KEY_CHECKS = 1;
读取未提交
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;这个语句设置事务隔离级别为"读取未提交"。这意味着一个事务可以读取另一个未提交的事务所做的修改。
1、首先我们将事务隔离级别改为读取未提交,使用上面的代码,在本章节的演示下面所有的事务开始前都要执行上面的设置读取未提交。
2、我们开启一个事务阿丹的工资向上调整500

BEGIN;
update t_demo set wage = wage + 500 where id =1;3、新建一个事务,去查询t_demo表中的数据查看一下
因为我执行了两次工资上调500.这个时候查询demo表
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
BEGIN;
SELECT * FROM `t_demo`效果如下

这个时候查看表中的数据有没有改变

并没有,因为第一个事务(运行了两次上调工资的语句)还没有提交,所以并没有落库。
但是在读未提交的情况下,还是读到了没有被提交上去的数据。
这种事务的安全是比较可怕的,因为脏读到了其他事务没有提交上去的数据。那么那条没有提交的事务随时可能会被回滚掉。那么就会造成数据的混乱。就如上述条件当现在有程序读取到了没有被提交的2000并进行了计算但是给阿丹添加工资的事务却进行了回滚!哦吼!出事了。所以这样的事务隔离解决并不安全。
读已提交--Oracle的默认隔离级别
注意:
在每次进行实验的时候一定要记住给前面的事务进行提交
commit;#提交事务SET TRANSACTION ISOLATION LEVEL READ COMMITTED;这条语句设置事务隔离级别为"读取已提交"。这种级别下,事务只能读取已经提交的数据,不会读取未提交事务的数据。
先展示一下表中现在的数据:
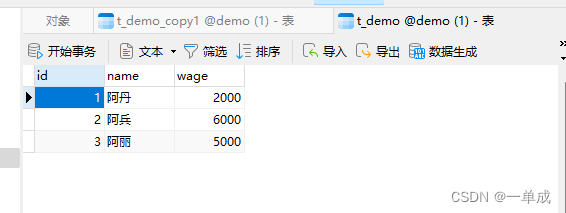
将每个要开启的事务。先设置成对应的隔离级别。
其实顾名思义就是在数据进行操作的时候只能去读取到已经被别的事务提交上去的数据。
那么我们现在开始开启一个事务A进行如下操作:
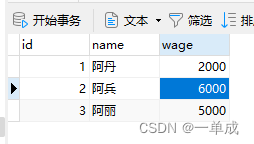
·1、开始一个事务并将阿兵的工资上调500,但是不提交
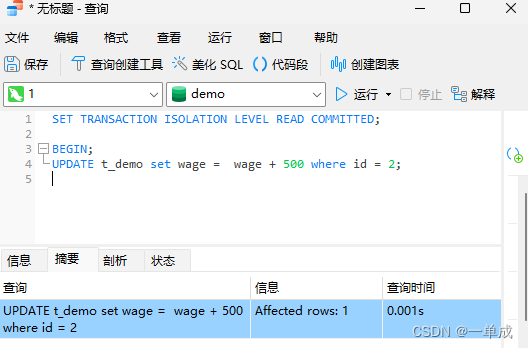
BEGIN;
UPDATE t_demo set wage = wage + 500 where id = 2;此时表中数据为:因为事务为提交所以数据并没有修改。
使用事务B进行如下操作:
1、 去查询阿兵的工资是多少
 可以看到阿兵这个时候的工资还是6000,因为事务A没有提交那么其他事务就读取不到。
可以看到阿兵这个时候的工资还是6000,因为事务A没有提交那么其他事务就读取不到。
但是当我们在事务A中将最后的结果进行提交。
commit;#提交事务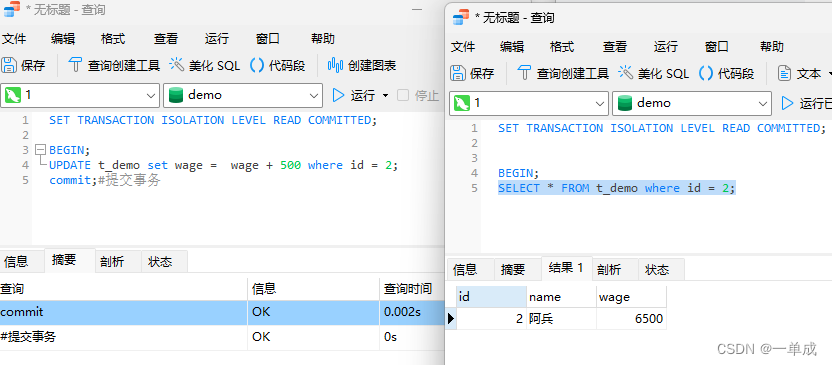 事务B中就可以读取到数据了。
事务B中就可以读取到数据了。
注意:
在这个事务隔离级别下面会出现什么问题呢?
不可重复读!!!
什么意思呢?我们可以看到只要是其他的事务对这条语句进行了修改,那么就会出现了读取该条id的数据变化。
那么在我对于一条数据在时间点A进行读取并使用这个数据进行了操作,在时间点A-B的过程中有其他的事务对于这条记录发生了改变并且提交。

那么我在时间点B的时候读取进行的操作就会出现问题。
示例业务场景:
-
假设你有一个银行账户表(
bank_accounts),包含账户ID(account_id)、账户所有者(owner)和账户余额(balance)字段。 -
在已提交事务隔离级别下,两个并发事务同时进行:
- 事务A从账户A的余额中扣除1000元。
- 事务B向账户A的余额增加1000元。
-
在事务A执行期间,事务B已经提交并完成了对数据库的更改。这意味着在事务A继续执行并尝试读取更新后的余额时,它将看到事务B所做的更改。
-
如果事务A在事务B提交之后、重新读取账户A的余额之前,将读取到的余额值存储到一个变量中(例如,
old_balance),然后在后续的操作中使用这个值,就会出现不可重复读的问题。因为在事务A两次读取余额之间,其他事务(如事务B)可能已经修改了该余额。因此,使用old_balance进行比较或计算时,可能会得到错误的结果。
可重复读--mysql的默认隔离级别(快照读)
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;这个语句设置事务隔离级别为"可重复读"。在该级别下,事务执行期间多次读取同一行数据的结果保持一致,即使其他事务更新了该行的值。
先展示一下表中目前的数据
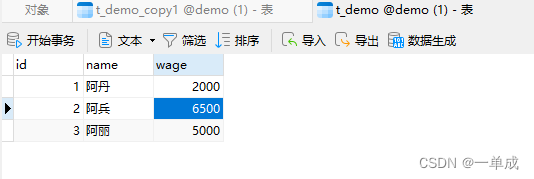
我们将三个事务的隔离级别进行修改

1、那么我们开启一个事务A将阿丽的工资上调1000但是不提交!
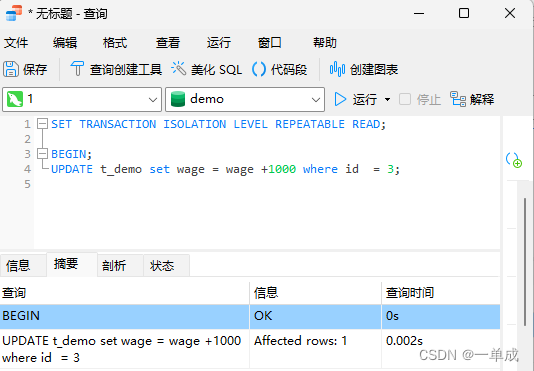
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;BEGIN;
UPDATE t_demo set wage = wage +1000 where id = 3;2、我们使用事务B去查询阿丽的工资
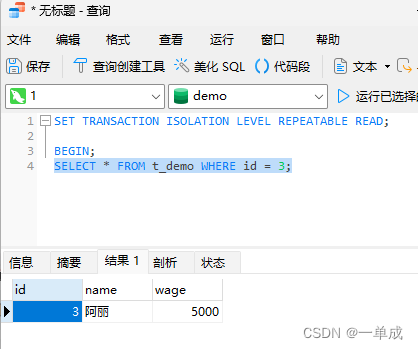
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;BEGIN;
SELECT * FROM t_demo WHERE id = 3;可以看到查到的数据还是5000.这是基于读已提交。
3、我们将事务A提交一下。然后我在事务B中再次查看

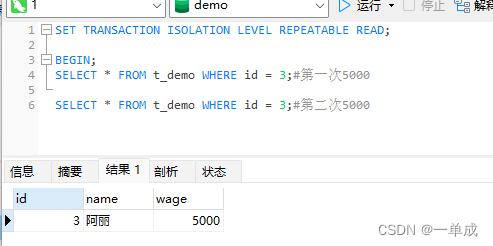
可以看到就算我们在事务A中进行了提交, 但是在事务B中读取到的数据还是第一次查询到的,这个就是可重复读!!
我们将事务B提交一下,然后再次查询


这个时候就可以查出来6000的数据了。
解释:
类似于快照的方式,在事务开始的时候整个表的数据都已经进行类似于快照保持下来了。
但是也出现了一个问题就是因为保持了一个类似于快照的方式所以在程序与数据库交互的时候出现了一个问题:
脏写问题:
阿丽的工资上调了1000管理人员将这个决定提交了,但是在另外的行政部门将阿丽工资因为工作事故下调了200。但是在下调的事务中读取到的是之前快照保存的5000,在经历程序的计算之后使用update语句将数据-200覆盖更新为了4800。于是阿丽少了整整1200块钱。

可串行化
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;这个语句设置事务隔离级别为"可串行化"。在该级别下,事务完全隔离,确保并发事务的执行顺序符合串行执行的效果。
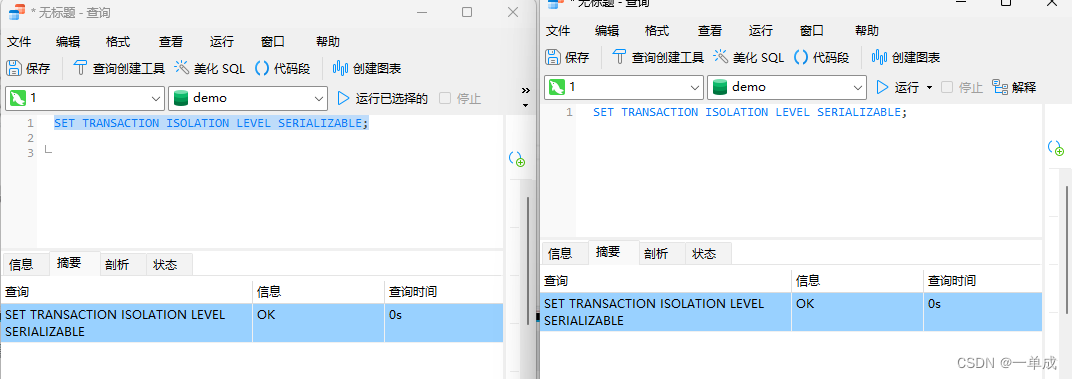
更改两个事务的隔离级别。
要进行的操作为:
1、我们开启事务A并将阿丹的工资上调100但是不提交
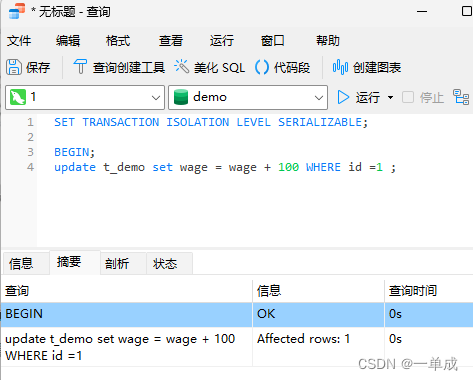
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;BEGIN;
update t_demo set wage = wage + 100 WHERE id =1 ;2、我们开启事务B查看阿丹的工资情况

SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN;
SELECT * FROM t_demo where id = 1;现象:
发现事务B一直无法运行,下面运行时间一直在上涨但是始终无法出现结果。事务B被事务A阻塞。
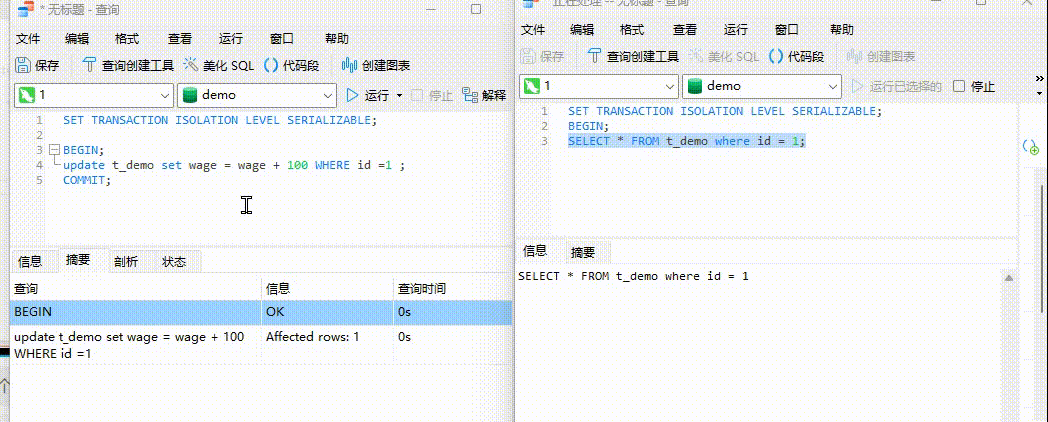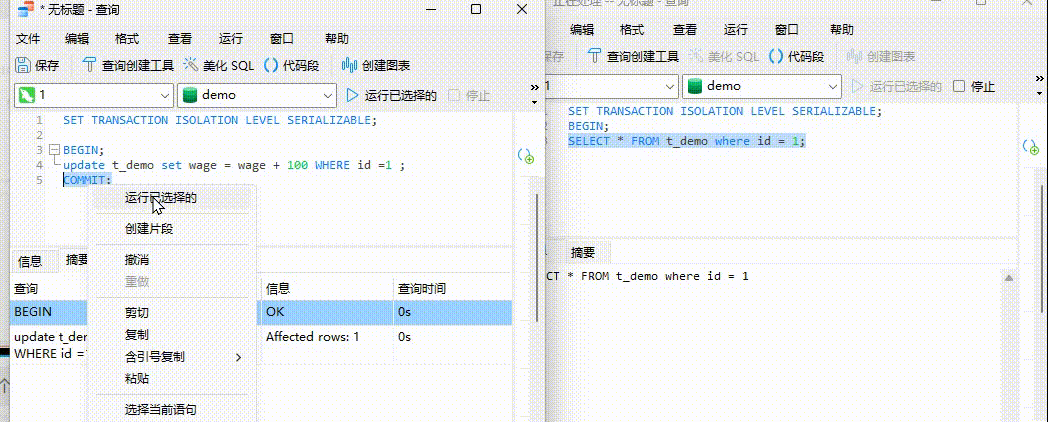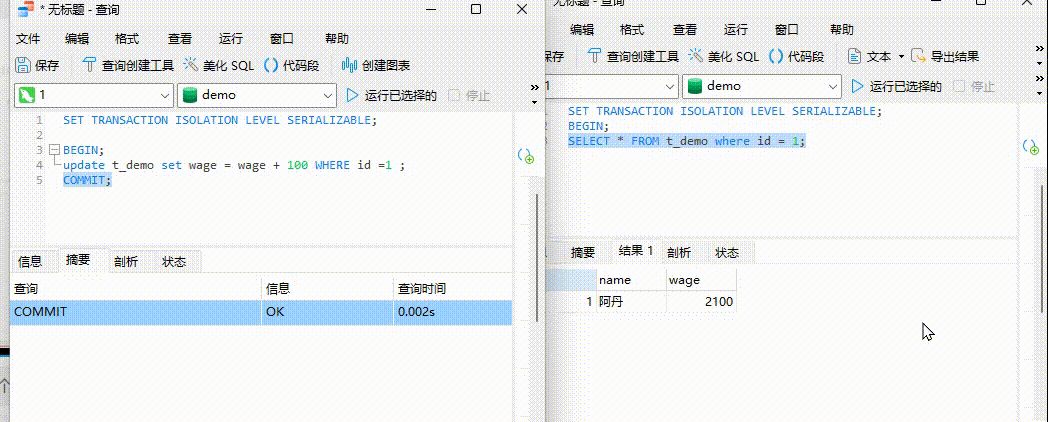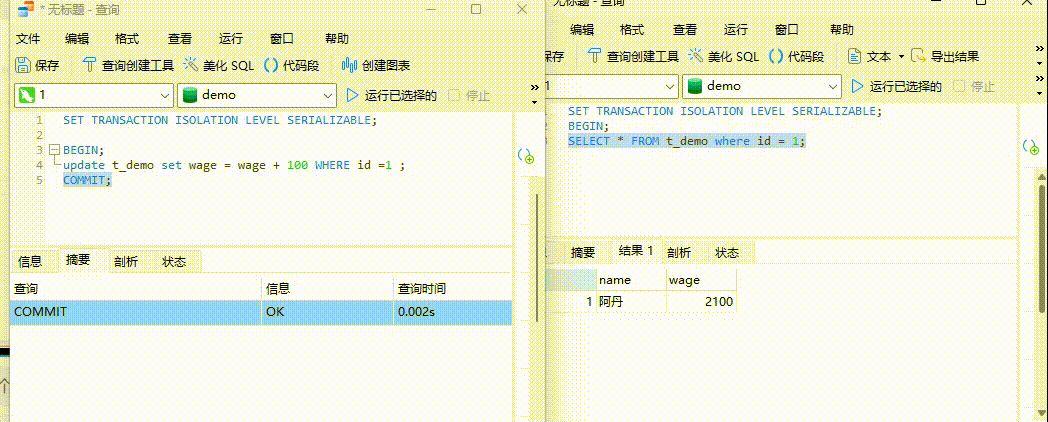
3、将事务A提交,发现事务B出现了结果
现象:
在事务A提交的之后事务B成功运行并出现结果!!!
解释:
在这个隔离级别下面,将所有的事务的读和写全部使用了穿行化来执行。排排队,当前面的事务没有执行完毕的时候,后面的事务就只能阻塞等着。这就是串行化。
在这个隔离级别下面解决了所有的问题,但是!因为串行化的原因在高并发的情况下效率是非常低的!!!
这篇关于mysql文档--innodb中的重头戏--事务隔离级别!!!!--举例学习--现象演示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





