本文主要是介绍第T7周:咖啡豆识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第7周:咖啡豆识别(训练营内部成员可读)
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
Z. 心得感受+知识点补充
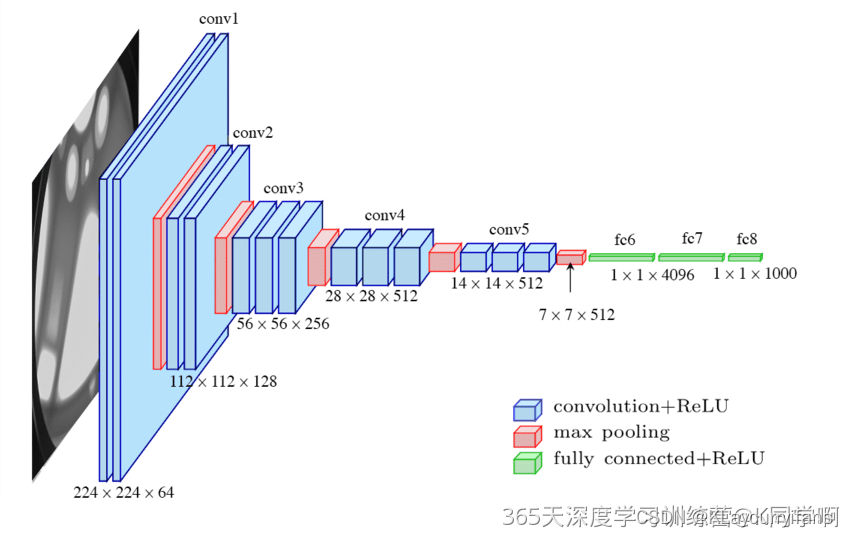
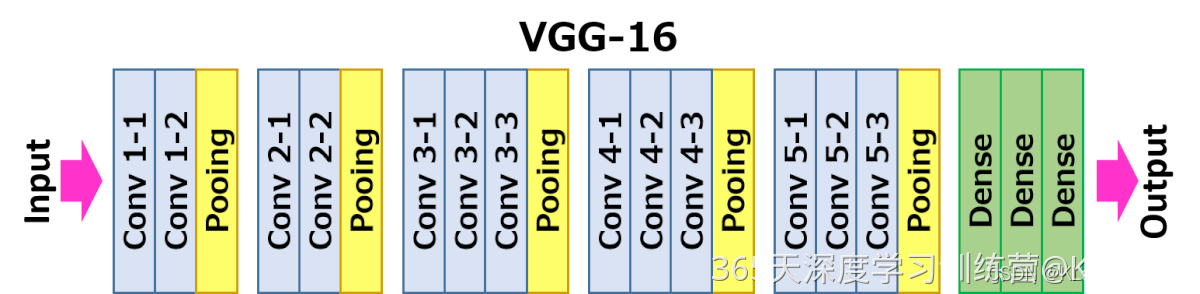
- VGG-16 结构说明:
- 13个卷积层(Convolutional Layer),分别用blockX_convX表示
- 3个全连接层(Fully connected Layer),分别用fcX与predictions表示
- 5个池化层(Pool layer),分别用blockX_pool表示
- 因为包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
一、前期工作
1. 导入数据
from tensorflow import keras
from tensorflow.keras import layers, models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import tensorflow as tfdata_dir = './data/'
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.png')))print("图片总数为:", image_count)
图片总数为: 1200
二、数据预处理
1. 加载数据
batch_size = 32
img_height = 224
img_width = 224
#使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed = 123,image_size=(img_height, img_width),batch_size=batch_size
)
Found 1200 files belonging to 4 classes.
Using 960 files for training.
#使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed = 123,image_size=(img_height, img_width),batch_size=batch_size
)
Found 1200 files belonging to 4 classes.
Using 240 files for validation.
#可以通过class_names输出数据集的标签,标签将按字母顺序对应于目录名称
class_names = train_ds.class_names
print(class_names)
[‘Dark’, ‘Green’, ‘Light’, ‘Medium’]
2. 可视化数据
plt.figure(figsize=(10,4))
for images, labels in train_ds.take(1):for i in range(10):# 将整个figure分成5行10列,绘制第i+1个子图ax = plt.subplot(2, 5, i+1)#图像展示,cmap为颜色图谱,"plt.cm.binary为matplotlib.cm中的色表"plt.imshow(images[i].numpy().astype('uint8'))#设置x轴标签显示为图片对应的数字plt.title(class_names[np.argmax(labels[i])])plt.axis('off')

for image_batch, labels_batch in train_ds:print(image_batch.shape) #Image_batch是形状的张量(32, 180, 180, 3)这是一批形状180*180*3的32张图片(最后一维指的是彩色通道RGB)print(labels_batch.shape) #Label_batch是形状(32, )的张量,这些标签对应32张图片break
(32, 224, 224, 3)
(32,)
3. 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size = AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]# 查看归一化后的数据
print(np.min(first_image), np.max(first_image))
0.0 1.0
三、构建VGG-16网络
1. 自建模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropoutdef VGG16(nb_classes, input_shape):input_tensor = Input(shape=input_shape)# 1st blockx = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)# 2nd blockx = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)# 3rd blockx = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)# 4th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)# 5th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)# full connectionx = Flatten()(x)x = Dense(4096, activation='relu', name='fc1')(x)x = Dense(4096, activation='relu', name='fc2')(x)output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)model = Model(input_tensor, output_tensor)return modelmodel=VGG16(len(class_names), (img_width, img_height, 3))
model.summary()
Model: “model”
Layer (type) Output Shape Param #
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 4) 16388
=================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
四、编译模型
# 设置初始学习率
initial_learning_rate = 1e-4lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate, decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)model.compile(optimizer=opt,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
五、训练模型
epochs = 20history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
30/30 [] - 316s 10s/step - loss: 1.3462 - accuracy: 0.2552 - val_loss: 1.1567 - val_accuracy: 0.3917
Epoch 2/20
30/30 [] - 313s 10s/step - loss: 0.9952 - accuracy: 0.5052 - val_loss: 1.1405 - val_accuracy: 0.3833
Epoch 3/20
30/30 [] - 317s 11s/step - loss: 0.7793 - accuracy: 0.5896 - val_loss: 0.6080 - val_accuracy: 0.5958
Epoch 4/20
30/30 [] - 319s 11s/step - loss: 0.5809 - accuracy: 0.6833 - val_loss: 0.5526 - val_accuracy: 0.7208
Epoch 5/20
30/30 [] - 315s 11s/step - loss: 0.5841 - accuracy: 0.6969 - val_loss: 0.4863 - val_accuracy: 0.8208
Epoch 6/20
30/30 [] - 316s 11s/step - loss: 0.4374 - accuracy: 0.8240 - val_loss: 0.5163 - val_accuracy: 0.8250
Epoch 7/20
30/30 [] - 313s 10s/step - loss: 0.3980 - accuracy: 0.8323 - val_loss: 0.2010 - val_accuracy: 0.9125
Epoch 8/20
30/30 [] - 314s 10s/step - loss: 0.2124 - accuracy: 0.9240 - val_loss: 0.0909 - val_accuracy: 0.9625
Epoch 9/20
30/30 [] - 312s 10s/step - loss: 0.1137 - accuracy: 0.9615 - val_loss: 0.0844 - val_accuracy: 0.9625
Epoch 10/20
30/30 [] - 315s 11s/step - loss: 0.0885 - accuracy: 0.9719 - val_loss: 0.1337 - val_accuracy: 0.9417
Epoch 11/20
30/30 [] - 314s 10s/step - loss: 0.0608 - accuracy: 0.9771 - val_loss: 0.0465 - val_accuracy: 0.9833
Epoch 12/20
30/30 [] - 313s 10s/step - loss: 0.0657 - accuracy: 0.9812 - val_loss: 0.0789 - val_accuracy: 0.9750
Epoch 13/20
30/30 [] - 313s 10s/step - loss: 0.0774 - accuracy: 0.9677 - val_loss: 0.0640 - val_accuracy: 0.9750
Epoch 14/20
30/30 [] - 315s 11s/step - loss: 0.0936 - accuracy: 0.9667 - val_loss: 0.0376 - val_accuracy: 0.9875
Epoch 15/20
30/30 [] - 314s 10s/step - loss: 0.0624 - accuracy: 0.9781 - val_loss: 0.1391 - val_accuracy: 0.9500
Epoch 16/20
30/30 [] - 315s 11s/step - loss: 0.0681 - accuracy: 0.9802 - val_loss: 0.0554 - val_accuracy: 0.9875
Epoch 17/20
30/30 [] - 315s 11s/step - loss: 0.0521 - accuracy: 0.9792 - val_loss: 0.0656 - val_accuracy: 0.9750
Epoch 18/20
30/30 [] - 313s 10s/step - loss: 0.0868 - accuracy: 0.9708 - val_loss: 0.0633 - val_accuracy: 0.9708
Epoch 19/20
30/30 [] - 313s 10s/step - loss: 0.0294 - accuracy: 0.9917 - val_loss: 0.0304 - val_accuracy: 0.9875
Epoch 20/20
30/30 [] - 316s 11s/step - loss: 0.0117 - accuracy: 0.9969 - val_loss: 0.0477 - val_accuracy: 0.9917
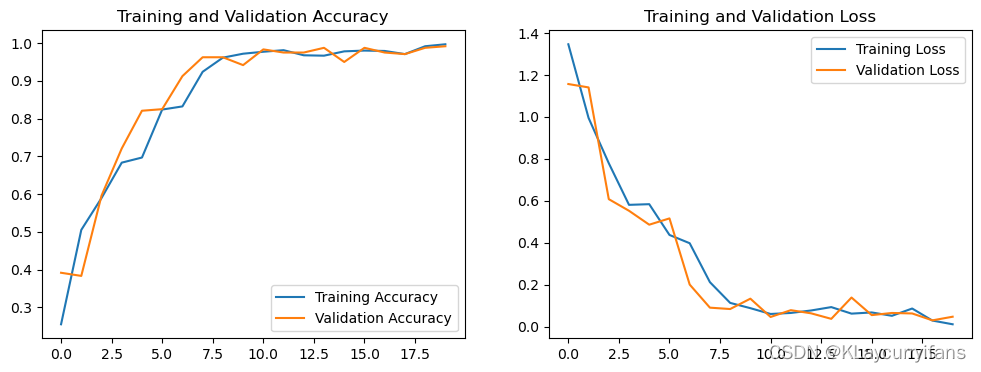
六、可视化结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
这篇关于第T7周:咖啡豆识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







