本文主要是介绍MySQL(InnoDB剖析):41---事务之(事务的实现:purge、group commit),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、purge
- delete和update操作可能并不直接删除原有的数据
例如
- 前一篇文章演示案例中:https://blog.csdn.net/qq_41453285/article/details/104346372
- 对表t执行下面的SQL语句。其中a字段为聚集索引,b字段为辅助索引
delete from t where a=1;
- 对于上述的delete操作,通过前面关于undo log的介绍已经知道仅是将主键列等于1的记录的delete flag设置为1,记录并没有删除,即记录还是存在于B+树中
- 其次,对于辅助索引上a=1,b=1的记录同样没有做任何处理,甚至没有产生undo log
- 而真正删除这样记录的操作其实被“延时”了,最终在purge操作中完成
- purge用于最终完成delete和update操作。这样设计是因为InnoDB存储引擎支持MVCC,所以记录不能在事务提交时立即进行处理。这时其他事务可能正在引用这行,故InnoDB需要保存记录之前的版本。而是放可以删除该条记录通过purge来进行判断。若该行记录已不被任何其他事务引用,那么就可以进行真正的delete操作。可见,purge操作时清理之前的delete和update操作,将上述操作“最终”完成。而实际执行的操作为delete操作,清理之前行记录的版本
History list
- 在前面介绍了,为了节省空间,InnoDB的undo log设计是这样的:一个页上允许多个事务的undo log存在。虽然这不代表事务在全局过程中的提交顺序,但是后面的事务产生的undo log总在最后
- 此外,InnoDB还有一个history列表,它根据事务提交的顺序,将undo log进行链接。如下面一种情况:
- 在图中:
- history list表示按照事务提交的顺序将undo log进行组织
- 在InnoDB的设计中,先提交的事务总在后端
- undo page存放了undo log,由于可以重用,因此一个undo page中可能存放了多个不同事务的undo log
- trx5的灰色阴影表示该undo log还被其他事务引用

purge的过程
- 以上图为例
- 在执行purge的过程中:
- InnoDB存储引擎首先将history list中找到第一个需要被清理的记录,这里为trx1
- 清理之后InnoDB会在trx1的undo log所在的页(undo page1)中继续寻找是否存在可以被清理的记录,这里会找到事务trx3
- 接着找到trx5,但是发现trx5被其他事务所引用而不能清理,故去再次去history list中查找
- 发现这时最尾端的记录为trx2,接着找到trx2所在的页,然后依次再把事务trx6、trx4的记录进行清理
- 由于undo page2中所有的页都被清理了,因此该undo page2可以被重用
- InnoDB这种先从history list中找undo log,然后再从undo page中找undo log的设计模式是为了避免大量的随机读取操作,从而提高purge的效率
innodb_purge_batch_size参数
- 该全局动态参数用来设置每次purge操作需要清理的undo page数量
- 默认值:
- 在InnoDB1.2之前,该参数的默认值为20
- 从InnoDB1.2版本开始,该参数的默认值为30
- 通常来说,该参数设置的越大,每次回收的undo page就越多,这样可供重用的undo page就越多,减少了磁盘存储空间与分配的开销
- 不过,若该参数设置的太大,则每次需要purge处理更多的undo page,从而导致CPU和磁盘IO过于集中于对undo log的处理,使性能下降
- 因此对该参数的调整需要有经验的DBA来操作,并且需要长期观察数据库的运行状态
- MySQL数据库手册说:普通用户不需要调整该参数
innodb_max_purge_lag参数
- 当InnoDB的压力非常大时,并不能高效地进行purge操作,那么history list的长度会变得越来越长
- 该全局动态参数用来控制history list的长度
- 参数的设置:
- 若长度大于该参数,其会“缓慢”DML的操作
- 该参数默认值为0:表示不对history list做任何限制
- 当history list长度大于该参数时,就会延缓DML的操作,其延缓的算法为:
- delay的单位是毫秒
- 此外,需要注意,delay的对象是行,而不是一个DML操作。例如当一个update操作需要更新5行数据时,每次数据的操作都会被delay,故总的延时时间为5*delay
- 而delay的统计会在每一次purge操作完成后,重新进行计算
innodb_max_purge_lag_delay参数
- InnoDB 1.2版本引入了该全局动态参数,用来控制delay的最大毫秒数
- 就是当上述计算得到的delay值大于该参数时,将delay设置为innodb_max_purge_lag_delay,避免由于purge操作缓慢导致其他SQL线程出现无限制的等待
二、group commit
为什么设计group commit?
- 若事务为非只读事务,则每次事务提交时需要进行一次fsync操作,以此保证重做日志都已经写入磁盘。当数据库发生宕机时,可以通过重做日志进行恢复。虽然固态硬盘的出现提高了磁盘的性能,然而磁盘的fsync性能是有限的
- 为了提高磁盘fsync的效率,当前数据库都提供了group commit的功能,即一次fsync可以刷新确保多个事务日志被写入文件
group commit的原理
- 对于InnoDB来说,事务提交时会进行两个节点的操作:
- ①修改内存中事务对应的信息,并且将日志写入重做日志缓冲
- ②调用fsync将确保日志都从重做日志缓冲写入磁盘
- 原理:
- 步骤②相对步骤①是一个较慢的过程,这是因为存储引擎需要与磁盘打交道
- 但当有事务执行步骤②时,其他事务可以进行步骤①的操作,正在提交的事务完成提交操作后,再次进行步骤②时,可以将多个事务的重做日志通过一次fsync刷新到磁盘,这样就大大地减少了磁盘的压力,从而提高了数据库的整体性能
- 对于写入或更新较为频繁的操作,group commit的效果尤为明显
group commit的功能会失效(prepare_commit_mutex锁)
- 然而在InnoDB 1.2版本之前,在开启二进制日志后,InnoDB存储引擎的group commit功能会失效,从而导致性能的下降。并且在线环境多实用replication环境,因此二进制日志的选项基本都为开启状态,因此这个问题尤为显著
- 导致这个问题的原因是在开启二进制日志后,为了保证存储引擎层的事务和二进制日志的一致性,两者之间使用了两阶段事务,其步骤如下:
- ①当事务提交时InnoDB存储引擎进行prepare(准备)操作
- ②MySQL数据库上层写入二进制日志
- ③InnoDB存储引擎层将日志写入重做日志文件
- a修改内存中事务对应的信息,并且将日志写入重做日志缓冲
- b调用fsync将确保日志都从重做日志缓冲写入磁盘
- 一旦步骤②中的操作完成,就确保了事务的完成,即使在执行步骤③时数据库发生了宕机。
- 此外需要注意的是:
- 每个步骤都需要进行一次fsync操作才能保证上下两层数据的一致性
- 步骤②的fsync由参数sync_binlog控制,步骤③的fsync由参数innodb_flush_log_at_trx_commit控制
- 因此,上述整个过程如下图所示:
- group commit为什么失效:
- 为了保证MySQL数据库上层二进制日志的写入顺序和InnoDB层的事务提交顺序一致,MySQL数据库内部使用了prepare_commit_mutex这个锁
- 但是在启用这个锁之后,步骤③的步骤a不可以在其他事务执行步骤b时进行,从而导致了group commit实现
- 然而,为什么需要保证MySQL数据库上层二进制日志的写入顺序和InnoDB层的事务提交顺序一致呢?
- 这是因为备份及恢复的需要,例如通过工具xtrabackup或者ibbackup进行备份,并用来建立replication,如下图所示:
- 可以看到若通过在线备份进行数据库恢复来重新建立replication,事务T1的数据会产生丢失。因为在InnoDB存储引擎层会检测事务T3在上下两层都完成了提交,不需要再进行恢复。因此通过锁prepare_commit_mutex以串行的方式保证顺序性,然而这会使group commit无法生效,如下图所示:



解决group commit的失效办法(BLGC)
- 这个问题最早在2010年的MySQL数据库大会中提出,Facebook MySQL技术组,Percona公司都提出解决办法。最后由MariaDB数据库的开发人员Kristian Nirlsen完成了最红的“完美”解决方案。在这种情况下,不但MySQL数据库上层的二进制日志写入是group commit的,InnoDB存储引擎层也是group commit的。此外还移除了原先的锁prepare_commit_mutex,从而大大提高了数据库的整体性。MySQL 5.6采用了类似的实现方式,并将其称为Binary Log Group Commit(BLGC)
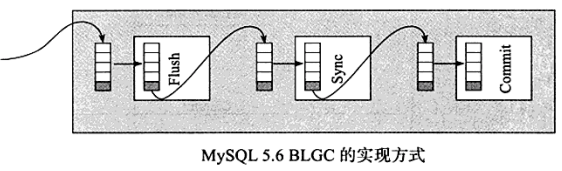
- BLGC的实现方式是将事务提交的过程分为几个步骤来完成,如下图所示:
- Flush阶段:将每个事务的二进制日志写入内存中
- Sync阶段:将内存中的二进制日志刷新到磁盘。若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的写入,这就是BLGC
- Commit阶段:leader根据顺序调用存储引擎层事务的提交,InnoDB存储引擎本就支持group commit,因此修复了原先由于锁prepare_commit_mutex导致group commit失效的问题
- 当一组事务在进行Commit阶段时,其他新事物可以进行Flush阶段,从而使group commit不断生效。当然group commit的效果由队列中事务的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多,甚至会更差。但当提交的事务越多时,group commit的效果就越明显,数据库性能提升也就越大
binlog_max_flush_queue_time参数
- 该参数控制Flush阶段中等待的时间,即使之前的一组事务完成提交,当前一组事务也不马上进入Sync阶段,而是至少需要等待一段时间
- 这样做的好处是group commit的事务数量越多,然而这也可能会导致事务的响应时间变慢
- 该参数的默认值为0,且推荐设置依然为0。除非用户的MySQL数据库系统中有着大量的连接(如100个连接),并且不断地进行事务的写入或更新操
这篇关于MySQL(InnoDB剖析):41---事务之(事务的实现:purge、group commit)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




