本文主要是介绍分组双轴图:揭示数据中的关联性和趋势变化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
分组双轴图是一种数据可视化图表,指有多个(≥2)Y轴的数据图表,多为分组柱状图+折线图的结合,图表显示更为直观,可以很好地展示不同指标之间的关系,帮助用户更好地理解数据,做出更准确的决策。除了适合分析两个相差较大的数据,分组双轴图也适用于显示大类别如何细分为较小的类别,以及每部分与总量之间的关系。

通过同时显示两个不同类型的指标(例如数量和百分比)来比较它们之间的关系。在分组双轴图中,数据被分成两个组,并分别在左右两个轴上显示。左侧轴通常用于表示数量或总数,右侧轴则通常用于表示百分比或比率。
适用场景
分组双轴图适用于需要比较不同类别或组别之间的趋势和变化情况的场景。通常用于比较两组或多组数据在同一时间或同一地点的变化情况,可以同时呈现不同的度量单位或指标,使得数据的比较更加直观和清晰。例如,可以用分组双轴图展示两个产品在同一时间段内的销售额和利润的变化情况,或者展示不同地区的人均收入和生活成本的趋势,适用于:
1.对比分析:分组双轴图适用于对比分析不同数据集之间的差异和相似之处。
2.趋势展示:分组双轴图可以展示数据的趋势变化,可以用于监测业务的发展和趋势。
3.多因素分析:分组双轴图可以同时展示两组或多组数据,可以方便地进行多因素分析。
优缺点
(1)分组双轴图的优点包括:
①可以同时展示多个数据系列,方便比较不同组别之间的数据差异。
②可以展示不同单位或量级的数据,避免数据之间的干扰。
③可以减少图表数量,节省空间,提高信息密度。
(2)分组双轴图的缺点包括:
①当数据分布差异较大时,容易造成一条轴线数据被另一条轴线的数据所掩盖,导致数据无法清晰呈现。
②当数据之间的差异不大时,分组双轴图的优势可能不如其他类型的图表明显。
③分组双轴图的绘制过程较为复杂,需要较高的技术门槛和时间成本。
如何绘制分组双轴图
目前市场上有许多绘制分组双轴图的软件工具,如Excel、Power BI等,可根据实际需要选择合适的工具进行绘制,这里我选用的山海鲸可视化进行绘制。要使用山海鲸可视化绘制分组双轴图,可以按照以下步骤进行操作:
①登录山海鲸可视化平台,创建一个新项目。
②在数据源页面导入需要绘制的数据,保证数据格式的正确性。

③在图表页面选择“分组双轴图”作为图表类型。
④根据数据源设置图表的数据、颜色、轴等属性,确保数据能够正确地呈现在图表中。
⑤根据需要对图表进行样式调整,包括字体大小、颜色、线条粗细等。

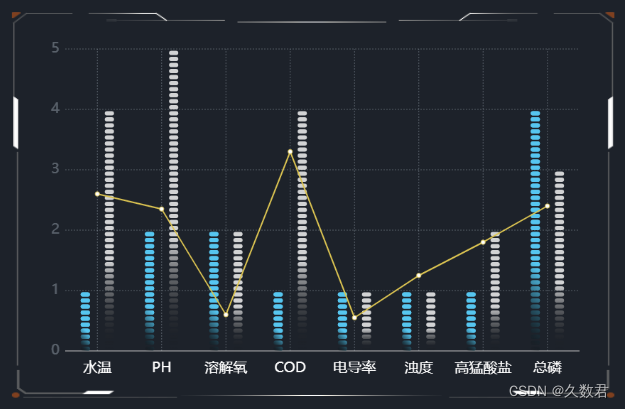
⑥确认图表设置无误后,点击“保存”即可。
需要注意的是,在设置分组双轴图时,要确保每个分组内的数据在横轴上都有对应的标签,这样才能正确地显示在图表中。此外,根据数据的特点,可以考虑使用不同的颜色、样式等来区分不同分组的数据,以便更好地传达信息。
使用山海鲸可视化绘制分组双轴图可以帮助用户更好地展现数据,从而更直观、清晰地表达数据的含义和趋势。
这篇关于分组双轴图:揭示数据中的关联性和趋势变化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





