本文主要是介绍Streamsets Postgresql 实时同步到Kudu,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Streamsets提供两种方式同步Postgresql,一种是JDBC、query,另一种是CDC方式,实时同步需要两者结合来首次同步。
首先需要全表同步,采用JDBC方式比较好:

这个比同步Mysql方便,可以写多个模式多个表同时同步。
![]()
这个是完成一次同步就触发,不至于没有数据进来报错。下一次事务继续同步。
![]()

这个一定要配置,不然_int json 格式就会报错。
勾选一下,然后Type转换主要是把时间格式转String。 kudu里面记录时间的字段全部是string格式。直接开始就行。
JDBC Multitable Consumer 里面有性能配置,可以参考官网。
等待全量同步的时候,可以配置PostgreSQL CDC Client pipeline流:
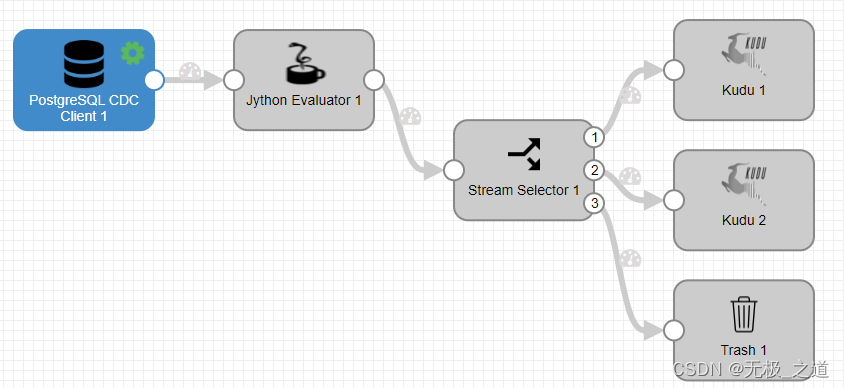

![]()

不认识的格式直接当成string 传入流中。
Jython Evaluator 配置(ETL重点):
import time
import datetimefor record in records:try:for change in record.value['change']:newRecord = sdcFunctions.createRecord(record.sourceId + str(time.time()))newRecord.value = {}newRecord.attributes['xid'] = str(record.value['xid'])newRecord.attributes['nextlsn'] = record.value['nextlsn']newRecord.attributes['timestamp'] = record.value['timestamp']newRecord.attributes['kind'] = change['kind']newRecord.attributes['schema'] = change['schema'] newRecord.attributes['jdbc.tables'] = change['table']if change['kind'] == 'insert':newRecord.attributes['sdc.operation.type'] = '1'if change['kind'] == 'delete':newRecord.attributes['sdc.operation.type'] = '2'if change['kind'] == 'update':newRecord.attributes['sdc.operation.type'] = '3'if 'columnnames' in change:columns = change['columnnames']types = change['columntypes']values = change['columnvalues']else:columns = change['oldkeys']['keynames']types = change['oldkeys']['keytypes']values = change['oldkeys']['keyvalues']for j in range(len(columns)):name = columns[j]type = types[j]value = values[j]newRecord.value[name] = valueoutput.write(newRecord)## optional, if we want to keep the original record,## otherwise we just put the new record in the batch.#output.write(record)except Exception as e:# Send record to errorerror.write(record, str(e))Stream Selector 配置:分流

kudu端配置比较简单。
当看到JDBC同步的数据很缓慢的时候,就可以直接开启CDC,然后关闭JDBC。有条件的可以先停止原始库写入数据的事务,等JDBC 同步完,开启CDC 再开启原始表的写入数据。
这篇关于Streamsets Postgresql 实时同步到Kudu的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






