本文主要是介绍Java PDF工具类(二)| 使用 wkhtmltox 实现 HTML转PDF(文字/图片/页眉页脚),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Java PDF工具类(二)| 使用 wkhtmltox 实现 HTML转PDF(文字/图片/页眉页脚)
相关文章: Java PDF工具类(一)| 使用 itextpdf 根据设置好的PDF模板填充PDF(文字和图片).
这里使用的是
wkhtmltopdf工具,可用于THML转图片或PDF。
- wkhtmltopdf官方网站下载地址:https://wkhtmltopdf.org/downloads.html.
可根据需要下载对应系统下的文件:
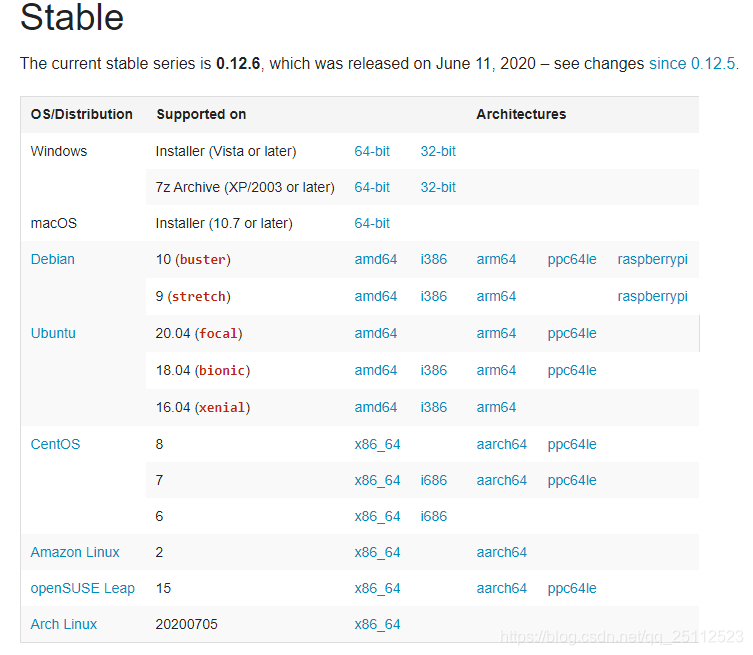
一、准备工作
(我这里只示范Windows版,Linux我这边是可以用的,至于安装过程大家自行百度)
1.下载Windows版本的 wkhtmltopdf 安装包,我这里安装在E盘

2.准备好test.html文件,我这里准备了页眉、页脚图片(注意:页眉页脚的引用要单独放在不同的html中)

将html中需要替换的地方替换成对应的变量名,用于程序替换成对应的值
foot.html:
<!DOCTYPE html>
<html>
<head><style>* {margin: 0;padding: 0;}img {max-width:100%;}</style>
</head>
<body><img src='yj.png'>
</body>
</html>
head.html:
<!DOCTYPE html>
<html>
<head><style>* {margin: 0;padding: 0;}img {max-width:100%;}</style>
</head>
<body><img src='ym.png'>
</body>
</html>
二、具体代码
1.将需要转 pdf 的 html 文件转成字符串
try {File f = new File("E:\\test.html");FileInputStream is = new FileInputStream(f);BufferedInputStream bis = new BufferedInputStream(is);ByteArrayOutputStream fos = new ByteArrayOutputStream();byte buffer[] = new byte[2048];int read;do {read = is.read(buffer, 0, buffer.length);if (read > 0) {fos.write(buffer, 0, read);}} while (read > -1);fos.close();bis.close();is.close();return fos.toString("UTF-8");
} catch (Exception e) {e.printStackTrace();
}
2.将html中的变量替换为具体的值,再将其传入工具类中进行转换
HtmlToPdfInterceptor:
import lombok.extern.slf4j.Slf4j;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;/*** html转pdf 输出日志*/
@Slf4j
public class HtmlToPdfInterceptor extends Thread{private InputStream is;public HtmlToPdfInterceptor(InputStream is){this.is = is;}/*** 输出wkhtmltopdf返回的内容*/public void run(){try{InputStreamReader isr = new InputStreamReader(is, "utf-8");BufferedReader br = new BufferedReader(isr);String line = null;while ((line = br.readLine()) != null) {log.info("html转pdf进度和信息:{}", line.toString());}}catch (IOException e){e.printStackTrace();}}
}
HtmlToPdfUtils:(如果是替换的字符串直接调用convertStringToHtml()方法即可,如果是html直接调用convert()方法即可)
import lombok.extern.slf4j.Slf4j;import java.io.*;
import java.nio.charset.StandardCharsets;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;/*** 生成PDF工具类*/
@Slf4j
public class HtmlToPdfUtils {/*** wkhtmltopdf在 Windows、Linux系统中的安装路径*/private static final String WINDOWS_HTML_TO_PDF_TOOL = "E:\\wkhtmltopdf\\bin\\wkhtmltopdf.exe";private static final String LINUX_HTML_TO_PDF_TOOL = "/opt/wkhtmltox/bin/wkhtmltopdf";/*** 页眉图片html:Windows、Linux系统中的路径*/private static final String WINDOWS_HEAD_HTML = "D:\\head.html";private static final String LINUX_HEAD_HTML = "/opt/head.html";/*** 页脚图片html:Windows、Linux系统中的路径*/private static final String WINDOWS_FOOT_HTML = "D:\\foot.html";private static final String LINUX_FOOT_HTML = "/opt/foot.html";/*** 临时文件存放目录:Windows、Linux系统中的路径*/public static final String WINDOWS_FILE_URL = "D:\\pdf\\temporary\\file";public static final String LINUX_FILE_URL = "/opt/temporary/file";static {String fileUrl = isWindowsSystem() ? WINDOWS_FILE_URL : LINUX_FILE_URL;File f = new File(fileUrl);if(!f.exists()){f.mkdirs();}}/*** html字符串转pdf,会生成垃圾文件,需要定时清理** @param data 替换好的html字符串* @param destFileName 保存pdf的名称* @return 返回pdf成功生成的路径*/public static String convertStringToHtml(String data, String destFileName) {return convert(stringToHtml(data), destFileName);}/*** 判断当前系统是否是Windows系统* @return true:Windows系统,false:Linux系统*/public static boolean isWindowsSystem(){String property = System.getProperty("os.name").toLowerCase();return property.contains("windows");}/*** html转pdf(加页眉页脚)** @param srcPath html路径,可以是硬盘上的路径,也可以是网络路径* @param destFileName 保存pdf的名称* @return 返回pdf成功生成的路径*/public static String convert(String srcPath, String destFileName) {destFileName = (isWindowsSystem() ? WINDOWS_FILE_URL + "\\" : LINUX_FILE_URL + "/") + destFileName;File file = new File(destFileName);
// File parent = file.getParentFile();//如果pdf保存路径不存在,则创建路径if (!file.exists()) {try {file.createNewFile();} catch (IOException e) {e.printStackTrace();log.error("html转pdf,创建文件失败:{}", destFileName);}}StringBuilder cmd = new StringBuilder();String toPdfTool = isWindowsSystem() ? WINDOWS_HTML_TO_PDF_TOOL : LINUX_HTML_TO_PDF_TOOL;// 这里可以拼接页眉页脚等参数cmd.append(toPdfTool);cmd.append(" ");// wkhtmltopdf默认不允许访问本地文件,需加入以下参数cmd.append(" --enable-local-file-access");
// cmd.append(" --page-size A4");cmd.append(" ");cmd.append(" --disable-smart-shrinking");// 页眉图片cmd.append(" --header-html " + (isWindowsSystem() ? WINDOWS_HEAD_HTML : LINUX_HEAD_HTML));cmd.append(" --header-spacing 5");// 页脚图片cmd.append(" --footer-html " + (isWindowsSystem() ? WINDOWS_FOOT_HTML : LINUX_FOOT_HTML));cmd.append(" " + srcPath);cmd.append(" ");cmd.append(destFileName);try {log.info("html转pdf命令:{}", cmd.toString());Process proc = Runtime.getRuntime().exec(cmd.toString());HtmlToPdfInterceptor error = new HtmlToPdfInterceptor(proc.getErrorStream());HtmlToPdfInterceptor output = new HtmlToPdfInterceptor(proc.getInputStream());error.start();output.start();proc.waitFor();log.info("html转pdf成功:html路径:{} pdf保存路径:{}", srcPath, destFileName);} catch (Exception e) {destFileName = "";e.printStackTrace();log.error("html转pdf失败:html路径:{} pdf保存路径:{}", srcPath, destFileName);}return destFileName;}/*** html字符串转pdf,会生成临时html文件,需要定时清理** @param data 替换好的html字符串* @return 返回生成的临时文件名称*/public static String stringToHtml(String data) {String srcPath = "";OutputStreamWriter osw = null;try {// 生成随机名字String code = String.format("%04d",(int) ((Math.random()*9+1) * 1000));String nowDate = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMddHHmmss"));// 根据系统,创建字符输出流对象,负责向文件内写入if (!isWindowsSystem()) {// 非Windows 系统srcPath = LINUX_FILE_URL + "/" +String.format("%s%s", code , nowDate) + ".html";} else {srcPath = WINDOWS_FILE_URL + "\\" + String.format("%s%s", code , nowDate) + ".html";}osw = new OutputStreamWriter(new FileOutputStream(srcPath), StandardCharsets.UTF_8);log.info("html转pdf,生成临时文件:{}", srcPath);// 将str里面的内容读取到fw所指定的文件中osw.write(data);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();log.error("html转pdf,生成临时文件失败:{}", e);}finally{if(osw!=null){try {osw.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();log.error("html转pdf,生成临时文件关流失败:{}", e);}}}return srcPath;}public static void main(String[] args) {HtmlToPdfUtils.convert("D:\\test.html", "D:\\wkhtmltopdf.pdf");}
}
PS: 根据以上两步,基本可正常生成PDF文件,需要使用到更高级的特性可自行参考官方文档
相关文章: Java PDF工具类(一)| 使用 itextpdf 根据设置好的PDF模板填充PDF(文字和图片).
参考文章:
- https://wkhtmltopdf.org/downloads.html.
- https://blog.csdn.net/zhangkezhi_471885889/article/details/52184700?locationNum=10&fps=1.
- https://www.cnblogs.com/1994jinnan/p/13369527.html.
- https://blog.csdn.net/weixin_43619912/article/details/101053134.
- https://blog.csdn.net/qq_34208844/article/details/100018352.
- https://blog.csdn.net/irabbit0708/article/details/106757571.
这篇关于Java PDF工具类(二)| 使用 wkhtmltox 实现 HTML转PDF(文字/图片/页眉页脚)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







