本文主要是介绍暑期实训Python第十天,seaborn画图 --------<泰坦尼克号沉船>数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
网上的泰坦尼克号沉船数据可视化,写的全是代码,没点分析过程,干脆我自己来写
• PassengerId => 乘客ID
• Survived => 获救情况(1为获救,0为未获救)
• Pclass => 乘客等级(1/2/3等舱位)
• Name => 乘客姓名
• Sex => 性别
• Age => 年龄
• SibSp => 堂兄弟/妹个数
• Parch => 父母与小孩个数
• Ticket => 船票信息
• Fare => 票价
• Cabin => 客舱
• Embarked => 登船港口
先分析 不同等级的船舱 里的存活率(条形图)
Pclass 分成1,2,3个等级 Survived 分为 0 和 1
使用groupby 将数据 分成组, 比如groupby("Pclass"),可以将数据划分成三个部分。
groupby(["Pclass","Survived"])就将数据分成六个部分
estimator:可回调函数
作用:设置每个分类箱的统计函数
指定x分类变量进行分组,指定 y为数据分布,绘制垂直条形图
sns.barplot(x=df.Pclass, y=df.Survived, estimator=lambda x: np.sum(x) / len(x), data=df)
plt.show()

分析结果:
一等舱位 的乘客存活率最大,最容易存活,存活率为0.629
三等舱的 乘客存活几率最小,存活率为0.2423
分析年龄和存活率 的关系
df["Age"].describe()
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
总数据有891条,可是年龄只有714,说明年龄有很多为 空值,所以为了数据的可靠性,将空值转变成 平均值
df.fillna({"Age":df.Age.mean()},inplace=True)

#年龄的直方图
sns.distplot(df.Age,bins=20)
plt.show()

仿照上面生成船舱等级和存活率 第一个的做法:
sns.barplot(x=df.Age, y=df.Survived, estimator=lambda x: np.sum(x) / len(x), data=df)
结果: 是很多密密麻麻的矩形,非常难观察出规律
这里就提到了一个新的名词:连续数据离散化,通俗的将就是分段
这里又由于作者的知识 是白痴状态,这里就需要弄懂cut 方法里的bins属性
小tips:
pandas中pd.cut()的功能和作用,cut(a,bins) a指的是需要切分的对象,b指的是需要将对象切成什么样子的份,bins是一个列表bins = [0, 59, 70, 80, 100]。这里题目可以将年龄范围从0-80,以10岁为区间,生成8个矩形
df["Age_band"] = pd.cut(df.Age,bins=np.arange(0,90,10))
sns.barplot(x="Age_band", y=df.Survived, estimator=lambda x: np.sum(x) / len(x), data=df)
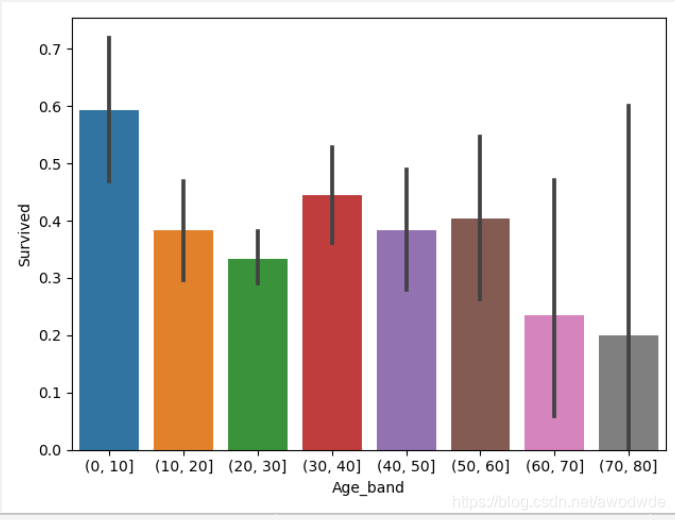
观察图形可以分析出:
10岁以下的孩子存活率最高,说明船上的人还是非常有人性的,而大于60岁的人,存活率偏低,说明老人行走不便,然后你懂的。普通人的存活率不超过0.5,说明基本上等于选择一个就等于放弃另外一个。
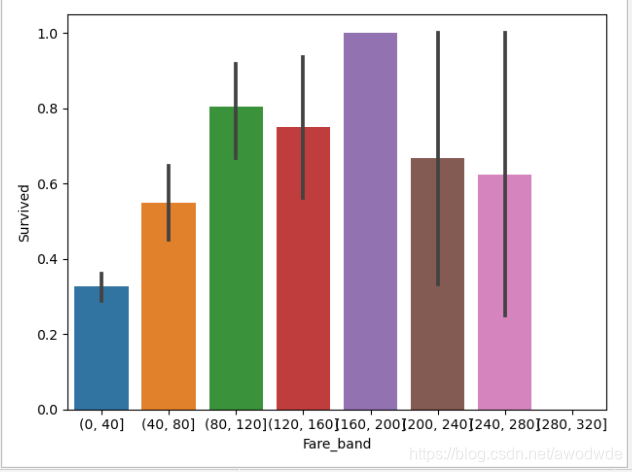
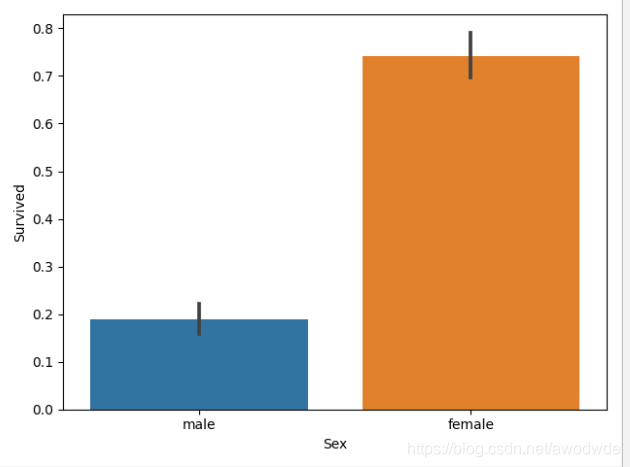
分析其他的数据和存活率的关系,由于代码一样就展示图:

性别影响真的很大
这篇关于暑期实训Python第十天,seaborn画图 --------<泰坦尼克号沉船>数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





