本文主要是介绍【PyTorchTensorBoard实战】GPU与CPU的计算速度对比(附代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文基于PyTorch通过tensor点积所需要的时间来对比GPU与CPU的计算速度,并介绍tensorboard的使用方法。
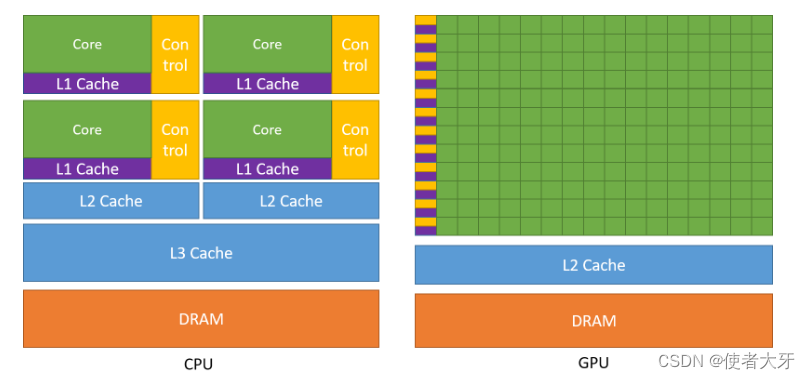
我在前面的科普文章——GPU如何成为AI的加速器GPU如何成为AI的加速器_使者大牙的博客-CSDN博客GPU如何成为AI的加速器 解释了GPU的多核心架构相比CPU更适合简单大量的计算,而深度学习计算的底层算法就是大量矩阵的点积和相加,本文将通过张量的点积运算来说明:与CPU相比,GPU有多“适合”深度学习算法。
加法相比于点积的计算量太小了,我感觉体现不出GPU的优势,所以没有用加法来对比两者的算力差距。
1. 准备工作
1.0 一台有Nvidia独立显卡的电脑
既然要使用GPU计算,一台有Nvidia独立显卡=支持CUDA的GPU的电脑就是必须的前置条件。如果不清楚CUDA、GPU和Nvidia关系的同学,可以再看下我的文章:GPU如何成为AI的加速器_使者大牙的博客-CSDN博客
1.1 PyTorch
在PyTorch的官网:Start Locally | PyTorch 选择合适的版本:

这里需要注意的是PyTorch的CUDA版本需要匹配电脑的GPU的CUDA版本,一般来说电脑>PyTorch的CUDA版本就没问题了。
例如我安装的PyTorch是CUDA 11.8版本,我的GPU驱动版本是12.2(查看路径:Nvidia控制面板>帮助>系统信息)。

1.2 Tensorboard
Tensorboard是TensorFlow官方提供的一个可视化工具,用于可视化训练过程中的模型图、训练误差、准确率、训练后的模型参数等,同时还提供了交互式的界面,让用户可以更加方便、直观地观察和分析模型。
这里需要注意的是Tensorboard虽然是由TensorFlow提供的,但是使用Tensorboard不需要安装TensorFlow!只要在虚拟环境下安装TensorboardX和Tensorboard即可,我使用的是Anaconda Prompt:
pip install tensorboardX
pip install tensorboard其使用方法为:
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("../logs") #这里有两个"."writer.add_scalars(main_tag, tag_scalar_dict, global_step=None):writer.close()另外需要注意SummaryWriter后面的路径要有两个“.”,这是因为我的代码文件在D:\DL\CUDA_test二级文件夹下面,我们需要把生成的tensorboard的event文件放在D:\DL\logs下面,而不是D:\DL\CUDA_test\logs路径下。这样做的理由是避免tensorboard报“No scalar data was found”

这里使用的是.add_scalars()方法来绘制多条曲线,参数如下:
- main_tag:字符串类型,要绘制的曲线主标题,本实例为“GPU vs CPU”
- tag_scalar_dict:字典类型,要绘制多条曲线的因变量,本实例为GPU和CPU的计算时间
{'GPU':CUDA,'CPU':CPU} - global_step: 标量,要绘制多条曲线的因变量,本实例为张量的大小tensor_size
在event文件生成后再在PyCharm的终端输入 tensorboard --logdir=logs ,点击链接就可以在浏览器中查看生成的曲线了。
2. 对比GPU与CPU的计算速度
本文的实例问题非常简单:分别使用CPU和GPU对尺寸为[tensor_size, tensor_size]的2个张量进行点积运算,使用time库工具对计算过程进行计时,对比CPU和GPU所消耗的时间。张量的大小tensor_size取值从1到10000。
我使用的硬件信息如下:
CPU:AMD Ryzen 9 7940H
GPU:NVIDIA GeForce RTX 4060
CPU计算时间:
import torch
import timedef CPU_calc_time(tensor_size):a = torch.rand([tensor_size,tensor_size])b = torch.rand([tensor_size,tensor_size])start_time = time.time()torch.matmul(a,b)end_time = time.time()return end_time - start_timeGPU计算时间:
import torch
import timedef CUDA_calc_time(tensor_size):device = torch.device('cuda')a = torch.rand([tensor_size,tensor_size]).to(device)b = torch.rand([tensor_size,tensor_size]).to(device)start_time = time.time()torch.matmul(a,b).to(device)end_time = time.time()return end_time - start_time3. 结果分析
最终生成的CPU和GPU计算张量点积的时间曲线如下:
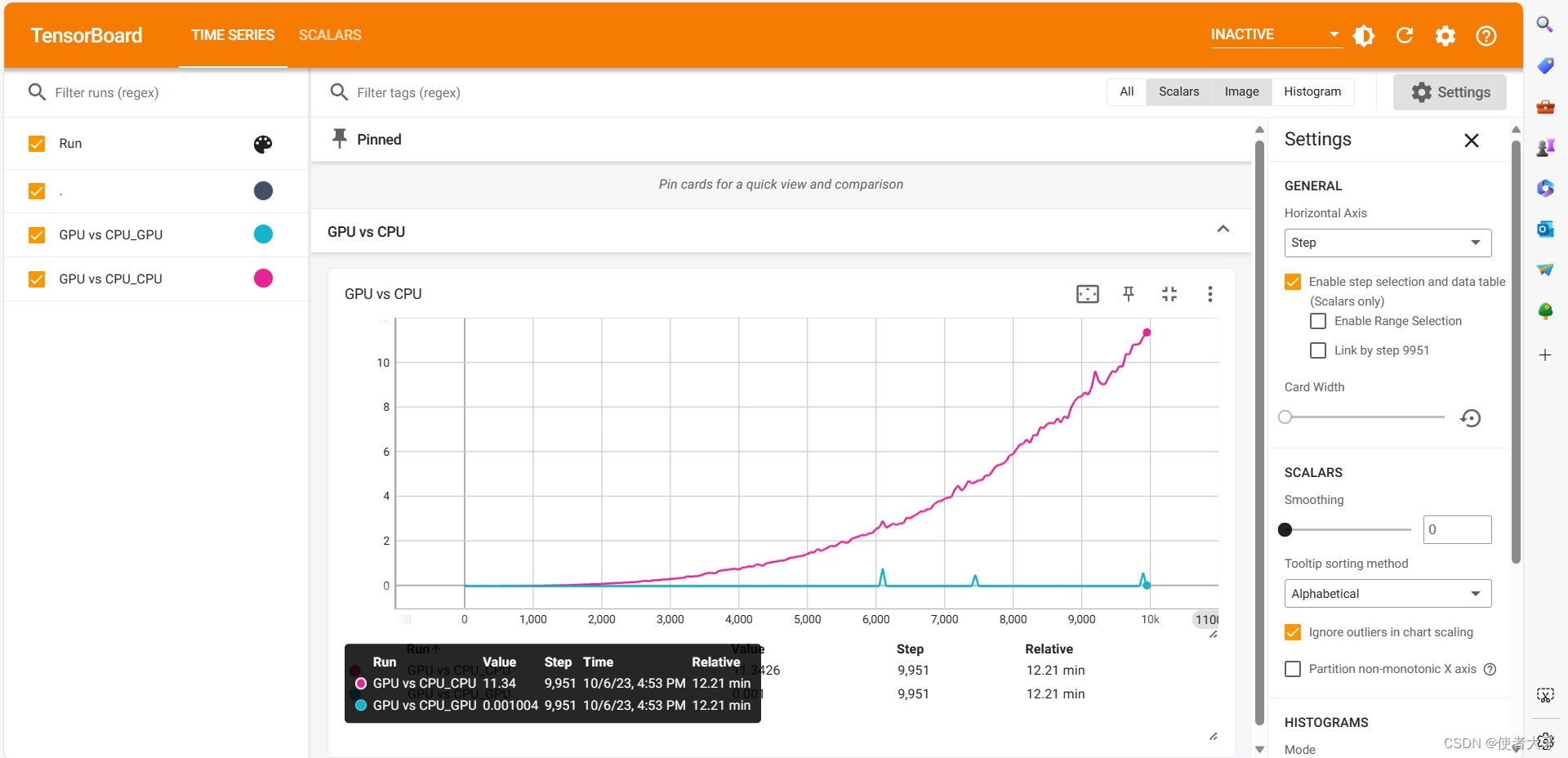
从图中可以看出,随着张量尺寸的增大,CPU计算时间明显增加(0~11.3s),而GPU的计算时间基本不变(0.001s左右),张量尺寸越大GPU的计算优势就越明显。
4. 完整代码
import torch
import time
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdmtorch.manual_seed(1)def CPU_calc_time(tensor_size):a = torch.rand([tensor_size,tensor_size])b = torch.rand([tensor_size,tensor_size])start_time = time.time()torch.matmul(a,b)end_time = time.time()return end_time - start_timedef CUDA_calc_time(tensor_size):device = torch.device('cuda')a = torch.rand([tensor_size,tensor_size]).to(device)b = torch.rand([tensor_size,tensor_size]).to(device)start_time = time.time()torch.matmul(a,b).to(device)end_time = time.time()return end_time - start_timeif __name__ == "__main__":writer = SummaryWriter("../logs")for tensor_size in tqdm(range(1,10000,50)):CPU = CPU_calc_time(tensor_size)CUDA = CUDA_calc_time(tensor_size)writer.add_scalars('GPU vs CPU',{'GPU':CUDA,'CPU':CPU},tensor_size)writer.close()# Command Prompt "tensorboard --logdir=logs"这篇关于【PyTorchTensorBoard实战】GPU与CPU的计算速度对比(附代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






