本文主要是介绍GPU渲染架构-IMR TBR TBDR,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题
IMR机制相比于TBR/TBDR,为什么会有更多的带宽消耗?
TBR & TBDR 相比于 IMR架构,在渲染管线的执行过程中实现了部分延迟机制。根本原因在于x86 PC机有显存。arm的移动设备没有显存,需要考虑带宽性能。
GPU架构
GPU 是流水线处理器,通常在流水线中没有缓存,即 GPU 中的各个内核没有缓存,但 GPU 与其 DRAM 或 CPU(在 APU 中)之间可能存在缓存。
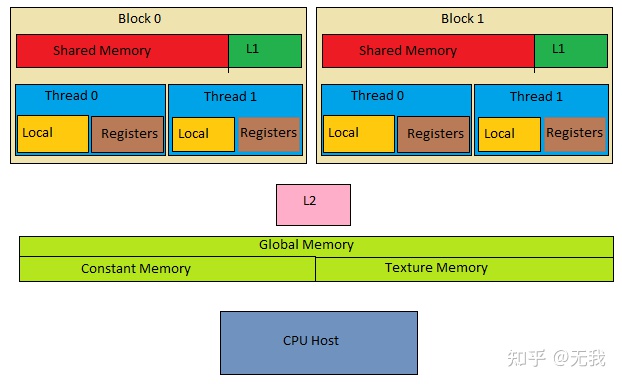
GPU内存架构
可以参考:GPU 内存架构 CUDA-GPU-memory-architecture
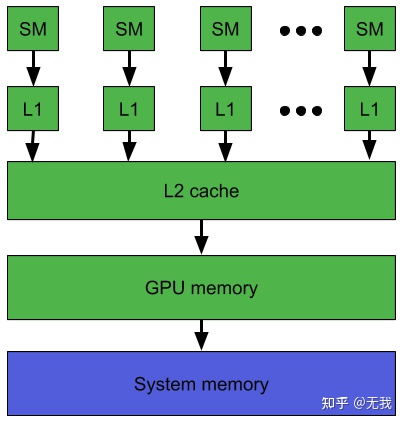

GPU常见的两种架构
IMR
Immediate Mode Rendering(即时渲染),传统的桌面 GPU 架构通常称为即时模式架构。
- 场景(渲染图元的完整对象模型)保留在客户端的内存空间中。
- 每次刷新帧时,应用程序都必须重新发送描述整个场景所需要的所有绘制命令。
- 即时渲染一方面为应用程序提供了最大程度的控制和灵活性。
- 另一方面它也会在CPU上产生持续的工作负载。
每一个三角形的渲染,都需要重新读写Frame Buffer和Depth Buffer (深度缓冲)。

左:Color Buffer 右:Depth Buffer
在这种架构下,每一次渲染完的Color和Depth数据写回到Frame Buffer和 Depth Buffer都会产生很大的带宽消耗。
在 IMR 中,图形流水线从上到下为每个基元进行,在每个基元的基础上访问内存。
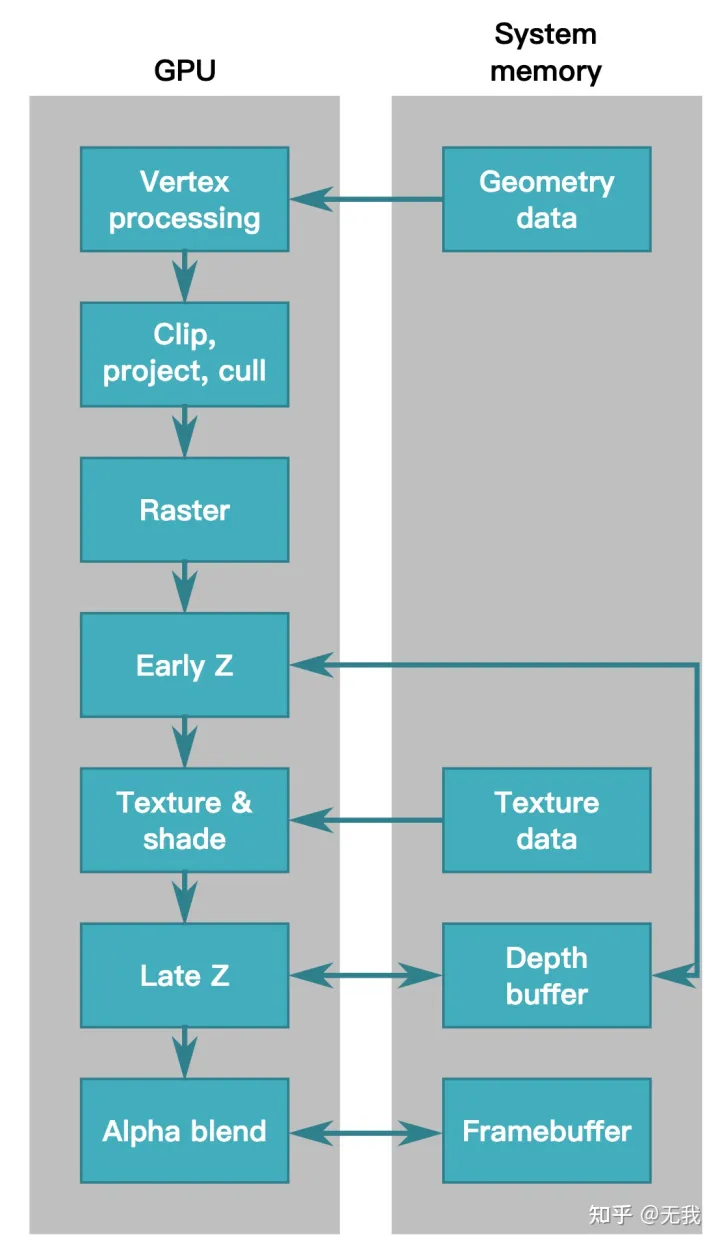
IMR-渲染管线
对IMR的带宽优化采用的是缓存方式。
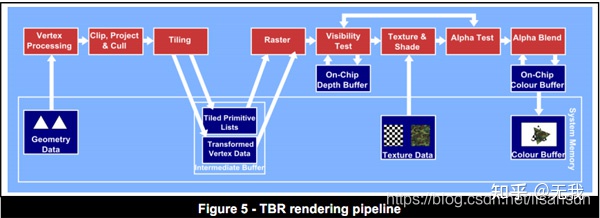
IMR流程
1. GPU 的首要任务是获取此顶点列表并将它们转换为屏幕上的三角形。

IMR Rendering Pipeline
2. 定义好几何图形后,GPU 的下一项工作是光栅化: 找出覆盖每个三角形的像素。 参考:无我:渲染管线 实时计算 & 光栅化实现原理
3. 每个像素的颜色由覆盖该像素的纹理和/或在该像素上运行的像素着色器程序确定.
4. 纹理 &半透明 & 着色算法, 这些颜色值被写入内存中的帧缓冲区,并且帧缓冲区显示在屏幕上.
即时模式 GPU 将渲染处理为严格的命令流,在每次绘制调用中按顺序在每个图元上执行顶点和片段着色器。
/***伪代码如下*/
for draw in renderPass: for primitive in draw:for vertex in primitive:execute_vertex_shader(vertex) //对每个顶点执行顶点着色器处理if primitive not culled:for fragment in primitive:execute_fragment_shader(fragment) //对每个片源执行片源着色器处理
硬件数据流和内存交互
优点
- 顶点着色器和其他几何相关着色器的输出可以保留在 GPU 内部的芯片上。
- 这些着色器的输出可以存储在 FIFO 缓冲区中,直到管道中的下一个阶段准备好使用数据。
- 这意味着 GPU 使用很少的外部内存带宽来存储和检索中间几何结果。
缺点
片段着色根据每次绘制中三角形的位置在屏幕上跳跃。 参考上边的gif图。
发生这种情况是因为流中的任何三角形都可能覆盖屏幕的任何部分,并且三角形是按绘制顺序处理的。
这样做的效果意味着活动工作集是整个帧缓冲区的大小。
例如,考虑一个分辨率为 1440p 的设备,它使用 32位每像素(BPP) 的颜色和 32 BPP 的打包深度/模板。这给出了 30MB 的总工作集,这对于保持在芯片上来说太大了,因此必须在芯片外存储在 DRAM 中。
GPU 必须从这个工作集中为每个混合、深度测试和模板测试操作获取当前片段的像素坐标的数据的当前值。
通常,所有阴影片段都访问此工作集。因此,在高分辨率下,由于每个片段都有多个读取-修改-写入操作,因此该内存上的带宽负载可能非常高。但是,缓存可以通过使最近访问的帧缓冲区部分靠近 GPU 来减轻高带宽负载。
TBR
Tile-Based Rendering
将帧缓冲分割为一小块一小块,然后逐块进行渲染.

对于TBR来讲,整个光栅化和像素处理会被分为一个个Tile进行处理,通常为16×16大小的Tile。TBR的结构通过On-Chip Buffers来储存Tiling后的Depth Buffer和Color buffer。(作用在更小的Depth& Color buffer,减少带宽)
Tile-Base-Rendering
从上图可以看到在TBR的架构里,并不是来一个基元绘制指令就执行一个,因为任何一个绘制都可能影响到到整个FrameBuffer。如果来一个画一个,那么GPU可能会在每一个绘制上都来回运输所有的Tile,这会比立即模式还要慢。
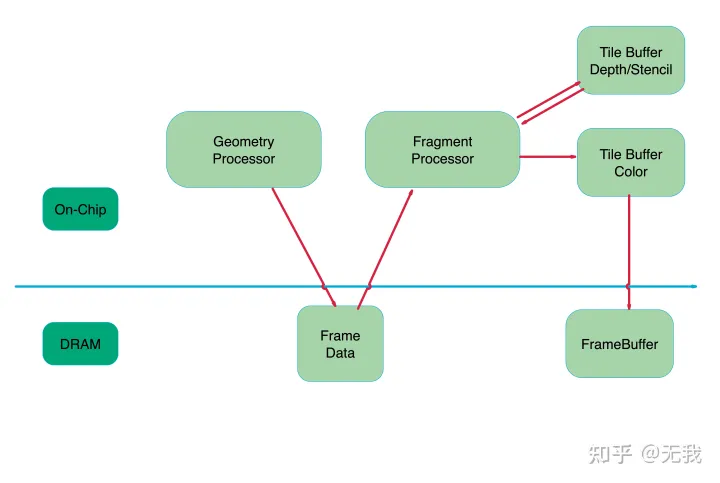
1、所以TBR一般的实现策略是对于Cpu过来的绘制,只对他们做顶点处理,也就是上图中的Geometry Processor部分,产生的结果(Frame Data)暂时写回到物理内存(在这里产生了执行延迟)。
2、等到非得刷新整个FrameBuffer的时候,比如说在代码里显示的执行GLFlush,GLFinish,Bind和Unbind FrameBuffer这类操作的时候,总之就是我告诉GPU现在我就需要用到FrameBuffer上数据的时候,GPU才知道拖不了了,就会将这批绘制做光栅化,做tile-based-rendering。
读取只发生在需要几何以及纹理信息的时候,写回也只发生在整批绘制画完的时候,具体的绘制都是在On_Chip Memory上完成的,也就是带宽消耗最大的DepthBuffer 和 ColorBuffer的读写都发生在On_Chip Memory上。
TBDR
TBDR 将场景细分为几百像素数量级的更小图块。 采用不同的方法来处理渲染通道,这称为基于图块的渲染。 顶点处理和着色照常继续,但在光栅化之前,场景被分割成图块。这就是延迟标签的用武之地。光栅化被延迟到平铺之后,纹理/着色被延迟更长的时间,直到通过隐藏表面去除 (HSR) 消除/最小化过度绘制之后。
这种方法旨在最大限度地减少 GPU 在片段着色期间需要的外部存储器访问量。
基于图块的渲染将屏幕分割成小块,并在将每个小图块写入内存之前对每个小图块进行分段着色。为了完成这项工作,GPU 必须预先知道哪个几何图形对每个图块有贡献。
因此,基于图块的渲染器将每个渲染通道分成两个处理通道:
- 第一遍执行所有与几何相关的处理,并生成一个图块列表数据结构,指示哪些图元对每个屏幕图块有贡献。
- 第二遍执行所有片段处理,逐块执行,并在块完成后将它们写回内存。
图块的
以下是基于 tile 架构的渲染算法示例:
// Pass one
for draw in renderPass:for primitive in draw:for vertex in primitive:execute_vertex_shader(vertex)if primitive not culled:append_tile_list(primitive)// Pass two
for tile in renderPass:for primitive in tile:for fragment in primitive:execute_fragment_shader(fragment)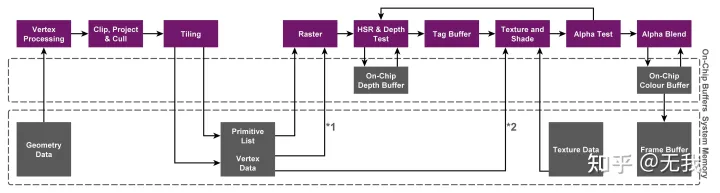
TBDR架构图
延迟渲染意味着架构将延迟所有纹理和着色操作,直到所有对象都经过可见性测试。PowerVR 隐藏表面移除 (HSR)(隐藏表面去除,隐藏表面消除) 的效率足够高,可以完全移除过度绘制以实现完全不透明的渲染。这显着降低了系统内存带宽要求,进而提高了性能并降低了功率要求。

Tile Base Render Pipeline
硬件数据流和内存交互
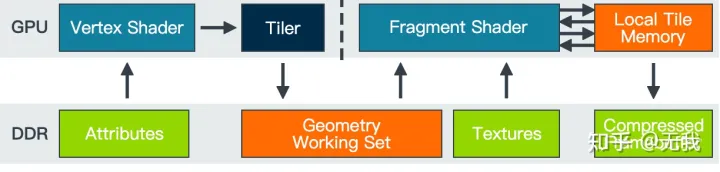
优势
带宽
基于瓦片的渲染的主要优点是瓦片只是总帧缓冲区的一小部分。
可以将颜色、深度和模板的整个工作集存储在与 GPU 着色器核心紧密耦合的快速片上 RAM 上。(Chip Cache)
GPU 用于深度测试和混合透明片段所需的帧缓冲区数据无需外部存储器访问即可获得。通过减少 GPU 对常见帧缓冲区操作所需的外部存储器访问次数,可以显着提高片段密集型内容的能效。
很大一部分内容具有瞬态的深度和模板缓冲区,并且只需要在着色过程的持续时间内存在。如果 驱动程序不需要保留附件,则驱动程序不会将它们写回主存储器。
更多带宽优化是可能的,GPU 只需在渲染完成后将图块的颜色数据写回内存,此时您知道其最终状态。您可以通过“循环冗余校验”(CRC) 检查将图块的内容与主内存中已有的当前数据进行比较。这会运行一个称为“事务消除”的过程。如果颜色没有变化,此过程会跳过将图块写入外部存储器。
在许多情况下,事务消除对性能没有帮助,因为片段着色器仍必须构建图块内容。但是,该过程在许多常见用例(例如 UI 渲染和休闲游戏)中大大降低了外部内存带宽。因此,它还降低了系统功耗。
算法
基于图块的渲染器启用了一些算法,否则这些算法计算量太大或带宽太重。
瓦片足够小,以至于 Mali GPU 可以在内存中本地存储足够的样本以支持多样本抗锯齿(MSAA)。因此,硬件可以在瓦片回写到外部存储器期间将多个样本解析为单个像素颜色,而无需单独的解析过程。Mali 架构在执行抗锯齿时允许非常低的性能开销和带宽成本。
一些高级技术(例如延迟光照)可以从片段着色器中受益,这些着色器以编程方式访问由先前片段存储在帧缓冲区中的值。
传统算法将使用多渲染目标(MRT) 渲染来实现延迟光照,将每个像素的多个中间值写回主存储器,然后在第二遍中重新读取它们。
降低带宽使用
基于瓦片的渲染器可以启用较低带宽的方法,其中每个像素的中间数据直接从瓦片内存共享,而 GPU 仅将最终点亮的像素写回内存。
对于可以使用四个 1080p 32bpp 中间纹理的延迟着色 G-Buffer,这种方法可以在 60 FPS 下节省高达 4GB/s 的带宽。
以下扩展在 OpenGL ES 中公开了此功能:
ARM_shader_framebuffer_fetchARM_shader_framebuffer_fetch_depth_stencilEXT_shader_pixel_local_storage
在 Vulkan 中,使用可合并子通道允许访问此功能。
缺点
基于图块的渲染具有许多优点,特别是它显着减少了与帧缓冲区数据相关的带宽,并提供了低成本的抗锯齿。但是,有一个重要的缺点需要考虑。
任何基于图块的渲染方案的主要额外开销都适用于从几何通道到片段通道的切换点。
GPU 必须将几何通道的输出(每个顶点变化的数据和分块器中间状态)存储到主存储器,片段通道随后将读取这些输出。因此,需要在与几何相关的额外带宽成本和帧缓冲区数据的带宽节省之间取得平衡。
同样重要的是要考虑到某些渲染操作,例如曲面细分,对于基于图块的架构来说是不成比例的昂贵。这些操作旨在适应即时模式架构的优势,其中几何数据的爆炸可以缓存在片上 FIFO 缓冲区内,而不是写回主存储器。
参考:
https://ashanpriyadarshana.medium.com/cuda-gpu-memory-architecture-8c3ac644bd64
GameDev | Samsung Developers
Documentation - Arm Developer
Documentation - Arm Developer
Understanding GPU caches
Samsung Galaxy S 2 (International) Review - The Best, Redefined
Unified and non-unified shader architectures
周陶生:渲染架构比较:IMR、TBR & TBDR
A look at the PowerVR graphics architecture: Tile-based rendering - Imagination
YiQiuuu:IMR, TBR, TBDR 还有GPU架构方面的一些理解
这篇关于GPU渲染架构-IMR TBR TBDR的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








