本文主要是介绍MDM大批量数据同步测试验证,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近期在进行主数据治理方案的实施落地,在主数据中存在人员主数据,而人员主数据主要对省内自然人进行记录,涉及数据量上千万条记录数,由于数据量巨大,需要对MDM主数据管理平台、ESB企业服务总线同步接口及集成流程进行测试,验证是否支持大批量数据同步。
本次大批量数据同步主要针对1千条、1万条、10万条、100万条、1000万条数据级别进行测试验证,其中1万条及以下采用批量同步方式,而1万条以上采用循环批量同步录入的方式,本文主要对测试方法、调优过程及测试结果分析进行主要说明。
1整体说明
本章主要针对测试的主要内容、测试的ESB应用集成流程具体实现情况以及遇到问题应该如何处理等进行详细说明。
1.1测试思路
在测试时主要针对1千条、1万条、10万条、100万条、1000万条数据级别进行测试验证,测试分为两个模块,具体如下:
1.对环境进行优化,分别优化主数据及ESB的CPU、内存,并对Redis、JVM、CentOS、Nginx等进行优化;
2.对每个数量级进行进行ESB层面测试,先用代码构造对应的入参,再使用ESB数据适配器中的数据插入组件记录每个数量级的同步时间;
3.复制原有集成流程,加入主数据调度接口进行数据的同步,记录同步时间,并与数据库批量插入同步时间进行对比,查看是否是因为同步接口降低同步时效;
4.对测试结果进行总结,将相关问题反馈至产品负责人员进行优化,并进行再次测试。
1.2测试流程
测试流程主要是针对不同数据量级别对ESB数据插入性能等进行测试,主要测试100W条及1000W条数据的写入测试,具体流程如下:
1.批量处理具体流程如下:
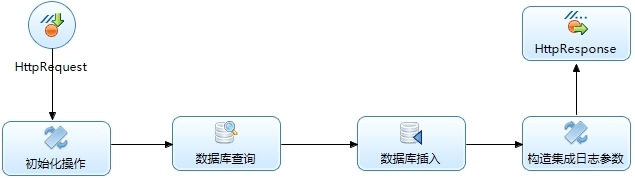
a)初始化操作记录数据起始时间;
b)查询出1千/1万条数据,并进行记录;
c)数据库直接批量数据插入;
d)记录截止时间并进行时间计算。
2.循环批量处理流程如下:

a)初始化操作记录数据起始时间;
b)使用Java转换节点构造1万条数据;
c)数据库直接批量数据插入;
d)索引自增长并进行循环;
e)构造集成日志参数并记录流程执行时间。
1.3结果验证
对数据执行结果进行分析,与开发人员反馈具体优化点,因为主数据不仅仅是数据的存储,还有数据的展现及分析,需要对人员数据管理进行查看验证&#x
这篇关于MDM大批量数据同步测试验证的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




