本文主要是介绍日增进:记一次PG主从搭建及数据同步性能测试流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景
PG安装
主从配置
主库配置
从库配置
验证主从搭建
数据同步
背景
随着金融领域关系型数据库的去ORACLE化,越来越多的客户现场开始采用国内自产云数据库或者开源数据库。国内自产的数据库有OceanBase,达梦,以及我们恒生的LightDB(超好用,极推),他们都有很强大的性能和客户至上的运维,这里便不再多说。我们的产品所用到的开源RDBMS目前以MySQL为主,它的优点是很多的,体积小、速度快、总体拥有成本低、开放源代码等等,这也是客户用的最多产品。但是MySQL有一个缺点是大事务下主从同步极慢,北京某一现场在同步某些特大数据表,如基金评价数据时(千万量级)竟会造成主从同步停滞,严重影响了产品使用。当然后续经过清空代替删除,减小每次提交量等方式也算是合理而有效的解决了这一问题。由于后面要上PG版本,为了防止数据同步时再有此情况发生,领导便让我开始测试PG主从同步,值此记录一下,供后续现场应用和新库测试起一点点小小的参考。

PG安装
默认环境Linux centos7发行版
- 创建目录
# mkdir -p /opt/database/
- 下载解压
推荐在官网下载安装包:选择版本后(我们这里12.2),选择tar.gz格式https://www.postgresql.org/ftp/source/![]() https://www.postgresql.org/ftp/source/
https://www.postgresql.org/ftp/source/

把安装包放到/opt/database/目录下
# tar -zxvf postgresql-12.2.tar.gz
- 安装依赖
# yum install -y bison
# yum install -y flex
# yum install -y readline-devel
# yum install -y zlib-devel
- 编译安装
# ./configure --prefix=/opt/database/postgresql-12.2
# make
# make install
- 创建用户
# groupadd postgres
# useradd -g postgres postgres
# chown -R postgres:postgres /opt/database/postgresql-12.2
# mkdir -p /opt/database/postgresql-12.2/data
- 安装初始化
# su postgres
$ /opt/database/postgresql-12.2/bin/initdb -D /opt/database/postgresql-12.2/data/$ /opt/database/postgresql-12.2/bin/pg_ctl -D /opt/database/postgresql-12.2/data/ -l logfile start --启动数据库
$ /opt/database/postgresql-12.2/bin/pg_ctl -D /opt/database/postgresql-12.2/data/ stop --停止数据库
$ /opt/database/postgresql-12.2/bin/pg_ctl restart -D /opt/database/postgresql-12.2/data/ -m fast --重启数据库
- 环境变量
$ su root
# cd /home/postgres
# vim .bash_profile添加:
export PGHOME=/opt/database/postgresql-12.2
export PGDATA=/opt/database/postgresql-12.2/data
PATH=$PATH:$HOME/bin:$PGHOME/bin# source .bash_profile
- 开机自启
# cp /opt/database/postgresql-12.2/contrib/start-scripts/linux /etc/init.d/postgresql
# chmod a+x /etc/init.d/postgresql
# vim /etc/init.d/postgresql更改prefix 和 PGDATA ,更改内容见上
# chkconfig --add postgresql (添加开机启动项目)
# chkconfig (查证是否添加准确)
- 设置密码
PostgreSQL安装后会自动创建一个数据库用户,名为postgres
$ service postgresql start
$ psql -U postgres
postgres=# ALTER USER postgres with encrypted password '${PASSWD}'; (密码自由设置)postgres=# \q (可退出)
注:以上步骤主库服务器和备库服务器都要实施一遍,即都安装上PG数据库
主从配置
通过上面的安装配置,在主从服务器上都已经安装好PostgreSQL数据库
主库配置
- 创建复制权限账户
CREATE ROLE replica login replication encrypted password '${PASSWD}';- 修改角色授权
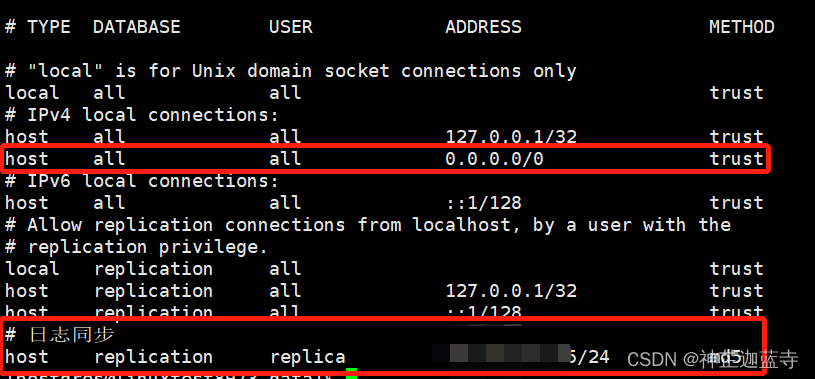
# vim /opt/database/postgresql-12.2/date/pg_hba.conf
添加所有IP均可访问:host all all 0.0.0.0/0 trust
添加从库复制: host replication replica 从机器IP/24 md5
- 修改配置文件
# vim /opt/database/postgresql-12.2/date/postgresql.conf
# 新增或修改下列属性设置
# 监听所有IP
listen_addresses = '*'
# 开启归档
archive_mode = on
#归档命令pg数据库的data文件夹
archive_command = 'test ! -f /opt/database/postgresql-12.2/data/pg_archive/%f && cp %p /opt/database/postgresql-12.2/data/pg_archive/%f'
#热备模式
wal_level = replica
#最多有2个流复制连接
max_wal_senders = 2
wal_keep_segments = 16
#流复制超时时间
wal_sender_timeout = 60s
#最大连接数,从机需要大于或等于该值
max_connections = 100- 重启数据库
$ pg_ctl -D /opt/database/postgresql-12.2/data -l /opt/database/postgresql-12.2/data/logfile restart
从库配置
从库配置较主库比较简单
1.停止服务
$ pg_ctl -D /opt/database/postgresql-12.2/data -l /opt/database/postgresql-12.2/data/logfile stop2.清空文件
$ rm -rf /opt/database/postgresql-12.2/data/*3.copy主服务器上数据
$ pg_basebackup -h 主节点IP -p 5432 -U replica -Fp -Xs -Pv -R -D /opt/database/postgresql-12.2/data/4.编辑data目录下会出现的standby.signal文件,加入 standby_mode = 'on'
$ vim /opt/database/postgresql-12.2/data/standby.signal5.编辑 postgresql.conf 文件,内容见下
$ vim /opt/database/postgresql-12.2/data/postgresql.conf
#从机信息和连接用户
primary_conninfo = 'host=主节点IP port=5432 user=replica password=replica用户的密码'
#说明恢复到最新状态
recovery_target_timeline = latest
#大于主节点,正式环境应当重新考虑此值的大小
max_connections = 120
#说明这台机器不仅用于数据归档,还可以用于数据查询
hot_standby = on
#流备份的最大延迟时间
max_standby_streaming_delay = 30s
#向主机汇报本机状态的间隔时间
wal_receiver_status_interval = 10s
#r出现错误复制,向主机反馈
hot_standby_feedback = on 最后启动数据库服务即可
$ pg_ctl -D /opt/database/postgresql-12.2/data -l /opt/database/postgresql-12.2/data/logfile start
验证主从搭建
连接主库运行sql
select client_addr,sync_state from pg_stat_replication;返回以下值即代表成功,也可通过在主库建表,插入,清空等操作看从库是否同步实现

数据同步
现在进行数据同步验证,看看往配置主从的PG数据库里同步大量数据是否能快速运行,是否会产生一些其他问题?
我们这里采用的是kettle这个ETL工具来实现文本数据写入,数据同步,数据计算等操作

经大量数据验证,测试结果如下:
- truncate这些DDL操作可以主从同步,秒完成
- 批量写入过程中,主从同步始终保持数据一致性
- 批量写入速率过慢,320w数据用时960秒(3333r/s)
- 进程清理机制有问题,每次运行失败后,需删除该sql进程,否则再次运行将停滞(锁表)
- 是强类型的,字段相互比较或赋值时必须要类型一致
- update 采用update table1 from table2的性能是最快的
- 参考其他同步工具如datax,发现提升速率无非是去除索引,读写分离,关闭归档这些行方现场肯定不会做的操作,PG没有类似MySQL的rewriteBatchedStatements强制批量提交
这篇关于日增进:记一次PG主从搭建及数据同步性能测试流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







