本文主要是介绍单表千亿电信大数据场景,使用Spark+CarbonData替换Impala案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

国内某移动局点使用Impala组件处理电信业务详单,每天处理约100TB左右详单,详单表记录每天大于百亿级别,在使用impala过程中存在以下问题:
详单采用Parquet格式存储,数据表使用时间+MSISDN号码做分区,使用Impala查询,利用不上分区的查询场景,则查询性能比较差。
在使用Impala过程中,遇到很多性能问题(比如catalog元数据膨胀导致元数据同步慢等),并发查询性能差等。
Impala属于MPP架构,只能做到百节点级,一般并发查询个数达到20左右时,整个系统的吞吐已经达到满负荷状态,在扩容节点也提升不了吞吐量。
资源不能通过YARN统一资源管理调度,所以Hadoop集群无法实现Impala、Spark、Hive等组件的动态资源共享。给第三方开放详单查询能力也无法做到资源隔离。
针对上面的一系列问题,移动局点客户要求我们给出相应的解决方案,我们大数据团队针对上面的问题进行分析,并且做技术选型,在这个过程中,我们以这个移动局点的几个典型业务场景作为输入,分别对Spark+CarbonData、Impala2.6、HAWQ、Greenplum、SybaseIQ进行原型验证,性能调优,针对我们的业务场景优化CarbonData的数据加载性能,查询性能并贡献给CarbonData开源社区,最终我们选择了Spark+CarbonData的方案,这个也是典型的SQL On Hadoop的方案,也间接印证了传统数据仓库往SQL on Hadoop上迁移的趋势。参考社区官网资料,结合我们验证测试和理解:CarbonData是大数据Hadoop生态高性能数据存储方案,尤其在数据量较大的情况下加速明显,与Spark进行了深度集成,兼容了Spark生态所有功能(SQL,ML,DataFrame等),Spark+CarbonData适合一份数据满足多种业务场景的需求,它包含如下能力:
存储:行、列式文件存储,列存储类似于Parquet、ORC,行存储类似Avro。支持针对话单、日志、流水等数据的多种索引结构。
计算:与Spark计算引擎深度集成和优化;支持与Presto, Flink, Hive等引擎对接;
接口:
API:兼容DataFrame, MLlib, Pyspark等原生API接口;
SQL:兼容Spark语法基础,同时支持CarbonSQL语法扩展(更新删除,索引,预汇聚表等)。
数据管理:
支持增量数据入库,数据批次管理(老化管理)
支持数据更新,删除
支持与Kafka对接,准实时入库
详细的关键技术介绍以及使用,请上官网阅读查看文档https://carbondata.apache.org/
这里补充介绍下为什么选取SQL on Hadoop技术作为最终的解决方案。
接触过大数据的人都知道,大数据有个5V特征,从传统互联网数据到移动互联网数据,再到现在很热门的IoT,实际上随着每一次业界的进步,数据量而言都会出现两到三个数量级的增长。而且现在的数据增长呈现出的是一个加速增长的趋势,所以现在提出了一个包括移动互联网以及物联网在内的互联网大数据的5大特征:Volume、 Velocity、Variety、Value、Veracity。随着数据量的增长传统的数据仓库遇到的挑战越来越多。
传统数据仓库面临的挑战:
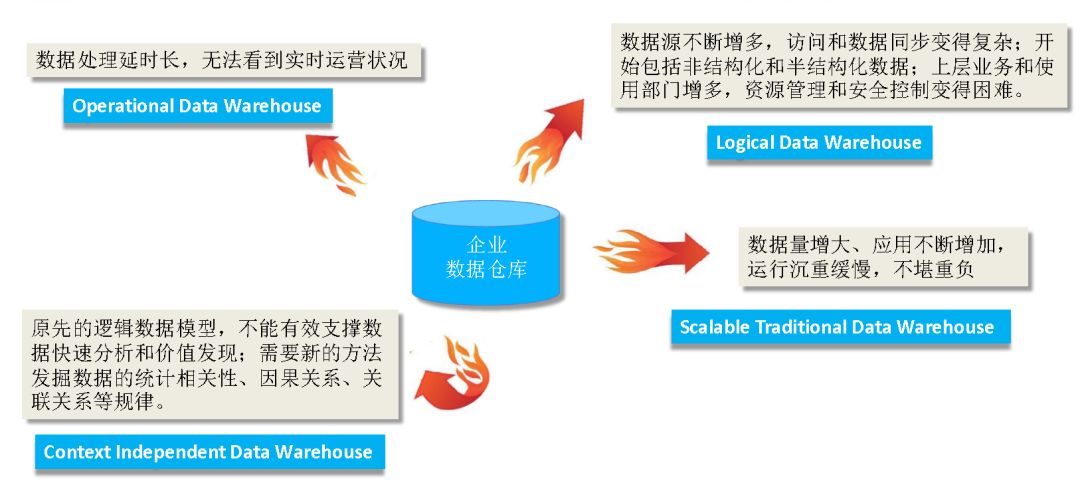
同时数据体系也在不断的进化
存储方式的进化:离线、近线 -> 全部在线
存储架构的进化:集中式存储 -> 分布式存储
存储模型的进化:固定结构 -> 灵活结构.
数据处理模式的进化
固定模型固定算法 -> 灵活模型灵活算法
数据处理类型的进化
结构化集中单源计算 -> 多结构化分布式多源计算
数据处理架构的进化
数据库静态处理 -> 数据实时/流式/海量处理
针对上述的变化数据库之父Kimball提出了一个观点:
 Kimball的核心观点:
Kimball的核心观点:
hadoop改变了传统数仓库的数据处理机制,传统数据库的一个处理单元在hadoop中解耦成三层:
存储层:HDFS
元数据层:Hcatalog
查询层:Hive、Impala、Spark SQL
Schema on Read给了用户更多的选择:
数据以原始格式导入存储层
通过元数据层来管理目标数据结构
由查询层来决定什么时候提取数据
用户在长期探索和熟悉数据之后,可以采取Schema on Write模式固化中间表,提高查询性能
序号 | 基于RDBMS的数据处理模式 | 基于hadoop的数据处理模式 |
1 | 强一致性 | 最终一致性,处理效率高于数据精确度 |
2 | 数据必须进行转换,否则后续流程无法继续 | 数据可以不做转换,长期以原始格式存储 |
3 | 数据必须进行清洗、范式化 | 数据不建议进行清洗和范式化 |
4 | 数据基本上都保存在物理表中,文件方式访问效率低 | 数据大部分保存在文件中,物理表等同于结构化文件 |
5 | 元数据局限为字典表 | 元数据扩展为HCatalog服务 |
6 | 数据处理引擎只有SQL一种 | 开放式的数据处理引擎:SQL、NOSQL、Java API |
7 | 数据加工过程完全由IT人员掌控 | 数据工程师、数据科学家、数据分析人员都可以参与数据加工 |
SQL on Hadoop数据仓库技术
数据处理和分析
• SQL on hadoop
• Kudu+Impala、Spark、HAWQ、Presto、Hive等
• 数据建模和存储
• Schema on Read
• Avro & ORC & Parquet & CarbonData
• 流处理
• Flume+Kafka+Spark Streaming
SQL-on-Hadoop技术的发展和成熟推动变革
经过上述的技术分析,最终我们选择了SQL on Hadoop的技术作为我们平台未来的数据仓库演进方向,这里肯定有人问了,为什么不选取MPPDB这种技术呢,这里我们同样把SQL on Hadoop与MPPDB进行过对比分析(注Impala其实也是一种类似MPPDB的技术):
对比项 | SQL on Hadoop | MPPDB |
容错性 | 支持细粒度容错,细粒度容错是指某个task失败会自动重试,不用重新提交整个查询 | 粗粒度容错,不能处理落后节点 (Straggler node)。粗粒度容错是指某个task执行失败将导致整个查询失败,然后系统重新提交整个查询来获取结果 |
扩展性 | 集群节点数量可以扩展到几百甚至上千个 | 很难扩展到100个节点以上,一般在50个节点左右(比如之前我们使用Greenplum验证超过32台机器性能出现下降) |
并发性 | 随着集群规模可用资源增加,并发数近线性增长 | MPPDB针对查询会最大化利用资源,以提升查询性能,因此支撑的并发数较低,一般并发查询个数达到 20 左右时,整个系统的吞吐已经达到满负荷状态 |
查询时延 | 1、数据规模小于1PB,单表10亿记录级别,单个查询时延通常在10s左右 2、数据规模大于1PB,可通过增加集群资源,保证查询性能 | 1、数据规模小于1PB,单表10亿记录级别,单个查询MPP时延通常在秒计甚至毫秒级以内就可以返回查询结果 2、数据规模大于1PB,受架构限制,查询性能可能会出现急剧下降 |
数据共享 | 存储与计算分离,通用的存储格式可以支撑不同的数据分析引擎,包括数据挖掘等 | 独有的MPPDB数据库的存储格式,无法直接供其他数据分析引擎使用 |
局点2018年9月底上线Spark+CarbonData替换Impala后运行至今,每天处理大于100TB的单据量,在业务高峰期,数据加载性能从之前impala的平均单台60MB/s到平台单台100MB/s的性能,在局点典型业务场景下,查询性能在20并发查询下,Spark+CarbonData的查询性能是Impala+parquet的2倍以上。
同时解决了以下问题:
Hadoop集群资源共享问题,Impala资源不能通过Yarn统一资源调度管理,Spark+CarbonData能通过Yarn统一资源调度管理,实现与其他如Spark,Hive等组件的动态资源共享。
Hadoop集群扩容问题,之前Impala只能使用百台机器,现在Spark+CarbonData能做到上千台节点集群规模。
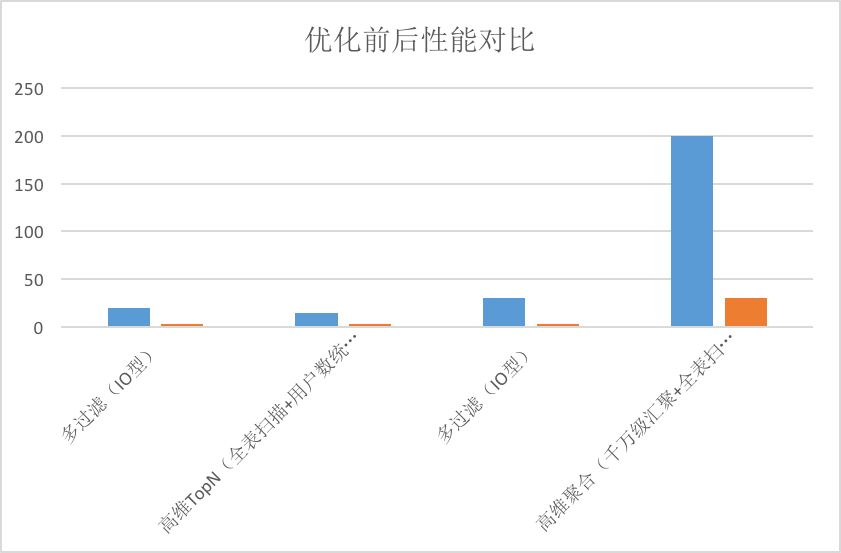
实施过程中注意项:
数据加载使用CarbonData的local sort方式加载,为了避免大集群产生过多小文件的问题,加载只指定少数机器上进行数据加载,另外对于每次加载数据量比较小的表可以指定表级别的compaction来合并加载过程中产生的小文件。
根据业务的查询特点,把经常查询过滤的字段设置为数据表的sort column属性(比如电信业务经常查询的用户号码等),并且设置sort column的字段顺序先按照字段的查询频率由高到低排列,如果查询频率相差不大,则再按照字段distinct值由高到低排列,来提升查询性能。
创建数据表设置的blocksize大小,单个表的数据文件block大小可以通过TABLEPROPERTIES进行定义,单位为MB,默认值为1024MB。这个根据实际数据表的每次加载的数据量,根据我们实践经验:一般建议数据量小的表blocksize设置成256MB,数据量比较大的表blocksize设置成512MB。
查询性能的调优,还可以结合业务查询的特点,对查询高频率的字段,创建bloomfilter等datamap来提升查询性能。
还有一些Spark相关的参数设置,对于数据加载和查询,先结合SparkUI分析性能瓶颈点,在针对性的调整相关的参数,这里不一一介绍了,记住一点性能调优是个技术细活,参数调整要针对性的调整,一次调整只调相关的一个或者几个参数,在看效果,不生效就调整回去,切记千万不要一次性调整的参数过多。
原文链接:https://my.oschina.net/u/4029686/blog/2878526?from=groupmessage
推荐阅读:
sparkrdd的另类解读
SparkStreaming VS Flink
Structured Streaming VS Flink
kafka消费者分组消费的再平衡策略
470+~好友都在知识星球

这篇关于单表千亿电信大数据场景,使用Spark+CarbonData替换Impala案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






