本文主要是介绍通义千问Qwen 2大模型的预训练和后训练范式解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLMs,也就是大型语言模型,现在已经发展得挺厉害的。记得最开始的时候,我们只有GPT这样的模型,但现在,我们有了一些更复杂的、开放权重的模型。以前,训练这些模型的时候,我们主要就是做预训练,但现在不一样了,我们还会加上后训练这个阶段。

咱们今天就以通义千问Qwen 2这个模型为例,来好好分析一下Qwen 2的预训练和后训练都是怎么搞的。它在大型语言模型界里算是挺能打的。不过,虽然它很强,但可能因为一些原因,它还没有像国外Meta AI、Microsoft和Google的那些模型那么火。
Qwen 2模型基本情况
Qwen 2有五种不同的规格,就像手机有不同内存大小一样。它有四个常规的模型,参数量分别是5亿、15亿、70亿和720亿。参数就像是模型的大脑细胞,参数越多,模型能处理的信息就越多。除了这些,还有一个专家混合模型,这个模型有57亿参数,其中有14亿是同时工作的。
Qwen 2的一个亮点是它在30种语言上都表现得很好,这就像是个多语言的天才。它还有一个特别大的词汇表,有151,642个标记(tokens)。这比很多其他模型的词汇表都要大,比如Llama 2有32k个标记,Llama 3.1有128k个标记。词汇表越大,模型处理信息的时候就越灵活,尤其是在处理多种语言的时候。
再来看看Qwen 2和其他一些模型在MMLU基准测试上的分数。MMLU是个多项选择题的测试,虽然它有局限性,但大家还是挺喜欢用它来衡量模型的表现的。咱们稍后会详细看看这些分数。
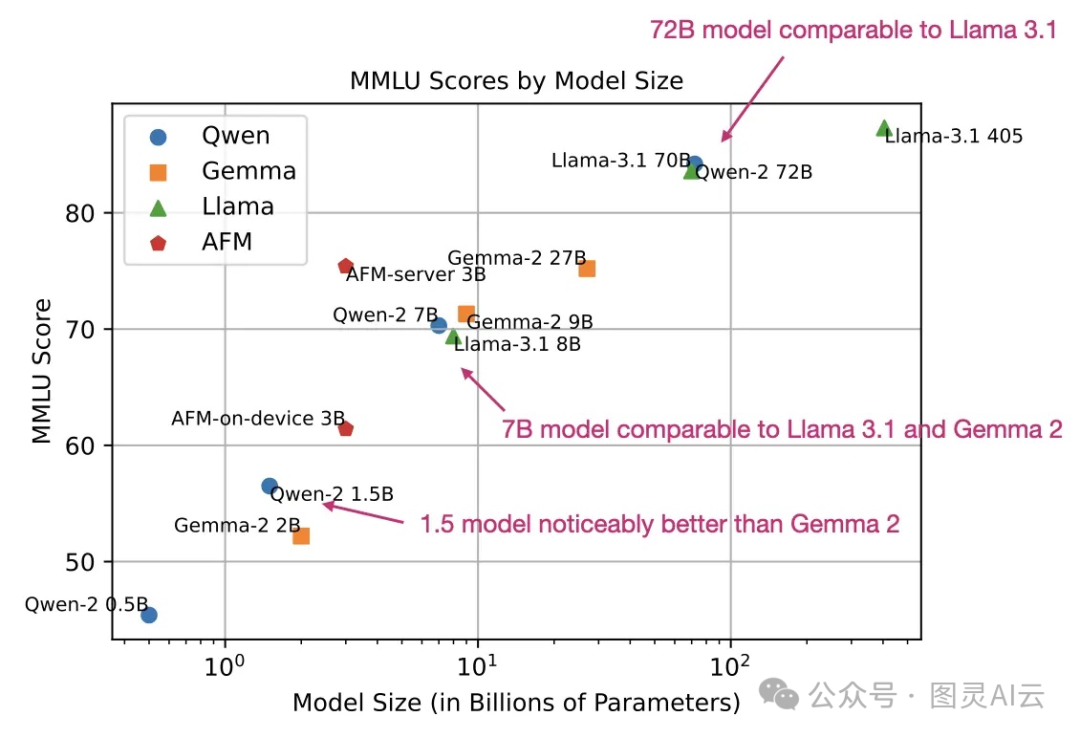
最新开放权重模型的MMLU基准测试分数(较高的值更好)
Qwen 2的预训练过程
Qwen 2团队在7万亿个训练标记上训练了15亿、70亿和720亿参数的模型。这个训练量听起来是不是挺吓人的?对比一下,Llama 2模型只用了2万亿个标记(tokens)来训练,而Llama 3.1模型则用了15万亿个标记。
但是,Qwen 2的5亿参数模型训练得更狠,用了12万亿个标记。研究人员没在更大的数据集上训练其他模型,因为他们发现这样训练效果提升不大,而且计算成本太高,不划算。
在预训练的时候,他们特别注重提高数据质量,比如过滤掉那些质量不高的数据,还有增加数据的多样性。这都是为了确保模型能学到更多有用的东西。
他们还用了一种挺聪明的方法,就是用Qwen模型自己生成一些预训练数据。这样可以让模型更好地理解上下文,以及如何根据指令来做出反应。
训练过程是分两个阶段的。先是常规的预训练,然后是长上下文训练。长上下文训练是在预训练快结束的时候进行的,用的是高质量的、长的数据。这个过程可以把模型处理上下文的能力从4,096个标记提高到32,768个标记,这就像是让模型的记忆力变得更强了。
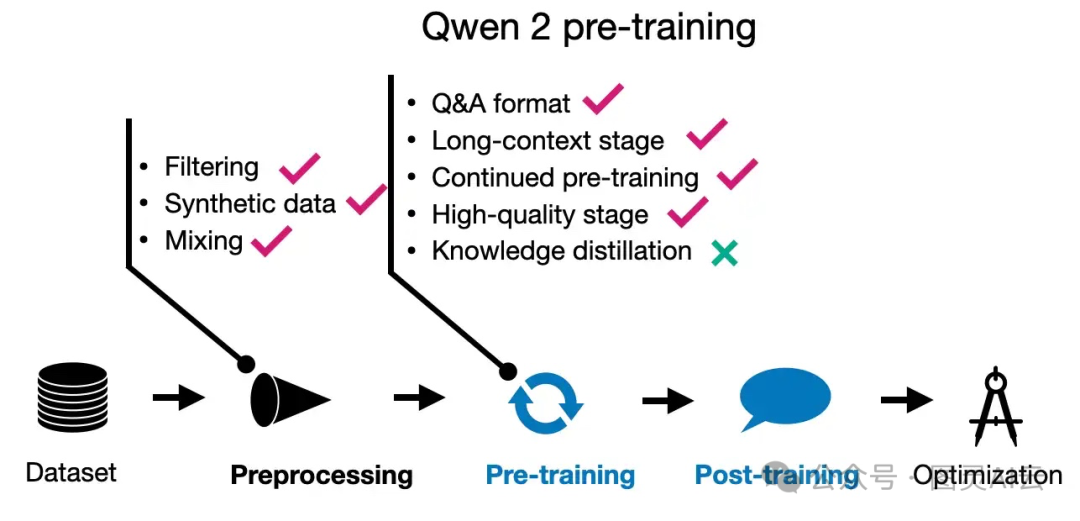
Qwen 2预训练技术,“持续预训练”指的是两阶段预训练,研究人员从常规预训练开始,然后进行了长上下文持续预训练
Qwen 2的后训练过程
Qwen 2团队用了一种流行的两阶段后训练方法。
第一阶段是监督指令微调(SFT),他们在500,000个示例上进行了2个周期的训练。这个阶段的目标是让模型在特定场景下给出更准确的回答。
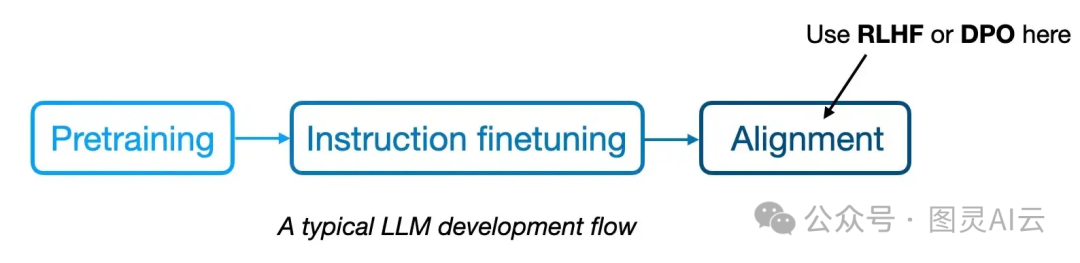
第二阶段,他们用直接偏好优化(DPO)来让模型更符合人类的偏好。SFT加上DPO的方法因为操作简便,比其他方法(比如带PPO的RLHF)更受欢迎。更多关于DPO的详情,可参见:《LLM 直接偏好优化(DPO)的一些研究》。关于PPO与DPO的对比,可以参见:《大模型对齐:DPO vs PPO》
对齐阶段也分两步走。首先是在现有的数据集上用DPO进行离线训练。然后是在线阶段,模型在训练时生成多个回答,奖励模型在训练过程中实时选择最优的回答。这个过程也叫做“拒绝采样”。
在构建数据集时,他们用了现有的语料库,并且加上了人工标注,来确定SFT的目标回答,以及识别DPO需要的偏好和拒绝回答。研究人员还自己合成了一些人工标注的数据。
此外,团队还用LLM生成了专门针对“高质量文学数据”的问答对,这样就能创建出用于训练的高质量Q&A对。这样可以让模型在处理文学类问题时表现得更好。
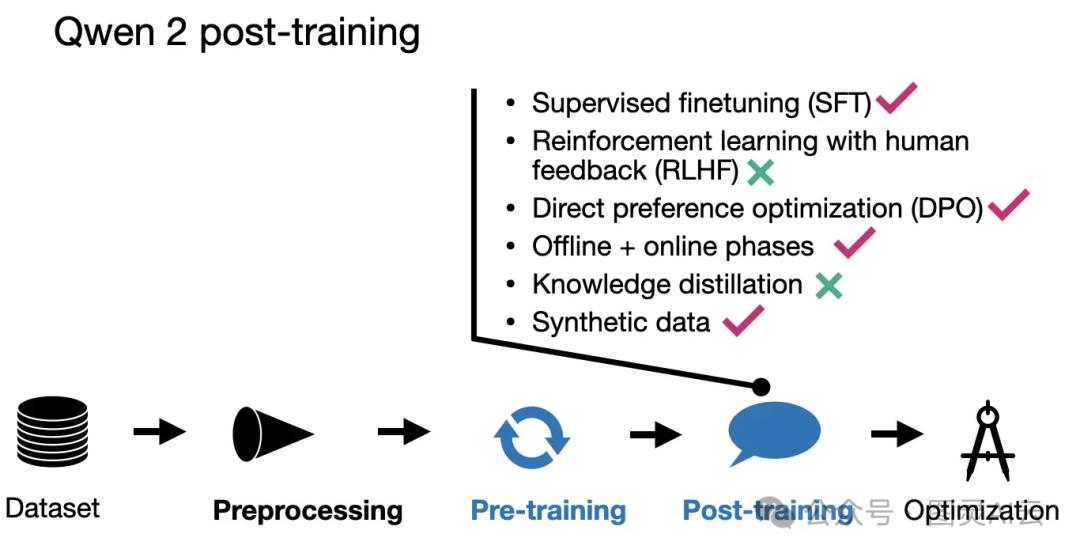
Qwen 2后训练技术
现在我们来总结一下,其实Qwen 2这个模型挺有两把刷子的。它和之前的Qwen模型一样,在2023年12月的NeurIPS LLM效率挑战赛上,很多获胜的方法都用了Qwen模型。
说到Qwen 2的训练流程,一个亮点就是他们用合成数据来预训练和后训练。这就像是用模型自己生成的练习题来提高自己的能力。
另外,他们特别注重数据集的质量,而不是一味地追求数据量。这意味着,他们更看重数据的质量而不是数量。在训练模型的时候,他们认为,数据不仅要多,更要精,只有高质量的数据才能帮助模型更好地学习。
所以,Qwen 2的训练团队在这方面做得挺到位的,他们知道怎么用有限的资源来达到最好的效果。这种注重质量的训练方法,值得其他模型训练团队学习。

这篇关于通义千问Qwen 2大模型的预训练和后训练范式解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





