本文主要是介绍设计模式2个黄鹂鸣翠柳-《分析模式》漫谈23,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DDD领域驱动设计批评文集
做强化自测题获得“软件方法建模师”称号
《软件方法》各章合集
“Analysis Patterns”的第一章有这么一句:
The "Gang of Four" book has had much more influence in software patterns than Alexander's work, and three out of those four authors had not read Alexander before writing that book.
2004(机械工业出版社)中译本的译文为:

标红字的地方都准确译出来了。
2020(人民邮电出版社)中译本的译文为:

虽然没有到让读者产生误解的地步,但还是存在这么几个问题:
(1)"Gang of Four" book改成了《设计模式》
虽然读者会自行脑补《设计模式》大概率就是GoF的那本《设计模式》,但建议还是尽量尊重原文。
*****以下是扩展*****
GoF的书面世三十年来,书名中有“模式”或“patterns”的书犹如滔滔江水绵绵不绝,其中一部分书的内容是用各种编程语言变着花样复刻GoF23模式,另一部分书的内容则是GoF23模式之外的新模式。
GoF(1995)有23个模式;Kent Beck的Smalltalk Best Practice Patterns(1997)有92个模式(就是格式不太规范);POSA(面向模式的软件架构)系列从1996年到2007年出了5本,作者说有114个模式;PLoPD(程序设计模式语言)系列从1995年到2006年也出了5本,手上资料不全暂时数不了,不过每一本的页数是对应POSA的近两倍;Fowler的《企业应用架构模式》有51个模式……
还有,PLoP年年开会,今年是第31届了。

这时候,如果只是说“设计模式”,指向性已经减弱。
如果GoF23模式像数学的基本定理一样,是软件模式学科中推导其他模式的起点,GoF23模式一直占用“设计模式”这个名头还可以理解。
可是,GoF23模式只不过是比较早归纳在书上,而碰巧这本书在所有模式出版物中最出名。并没有证据说明,跳过GoF23模式直接学习和使用其他模式会有什么问题。
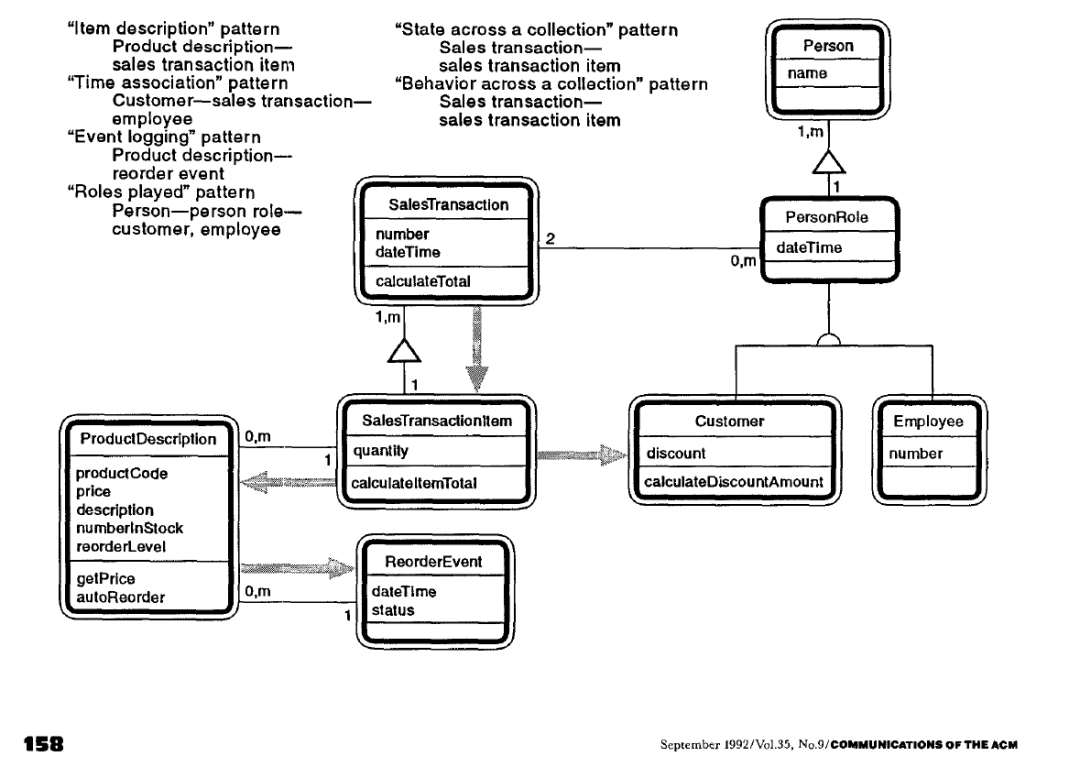
例如,下面是Peter Coad在1992年(比GoF的书早)归纳的模式,我觉得对于领域建模而言更有用。

长期以来在软件开发人员中存在一个误解:模式=设计模式=GoF23模式。
我提供服务的这些年,经常碰到这样的情况:
客户:潘老师,来给我们讲讲设计模式吧!
我:我猜你说的设计模式就是那23个模式吧,设计可以讲,模式也可以讲,这些都有用,光讲那23个没用的。
客户(愕然):啊?设计不就是学那23个设计模式吗,不是说学会了23个设计模式就掌握设计了吗?
现在的模式数量已经非常多,开发团队只需根据自己所做的系统挑选一些模式来学习,包括:(1)系统所聚焦核心域的分析模式(2)系统所使用非核心域的设计模式。
例如,开发团队在做一个医疗系统,使用的平台是.NET,那么应该去搜索“医疗领域分析模式”、“.NET架构模式”或“.NET设计模式”来学习。
(2)阿拉伯数字的使用
如果原文使用单词,中文译文用汉字更合适,除非有特别的原因。
前面翻译Gang of Four时(参见:设计模式Gang of Four怎么翻译-《分析模式》漫谈21),2020中译本写的也是“四人组”而不是“4人组”。
*****以下是扩展*****
我在《软件方法》的勘误中说过这个苦恼:
原稿写“一十八年过去,弹指一挥间”,是化用伟人诗词。编辑估计没读过,随手把“一十八”改成了“18”,类似于“2个黄鹂鸣翠柳,1行白鹭上青天”。
(3)writing that book没有翻译
“写那本书之前”缩减成了“之前”。
*****以下是扩展*****
我的观点是应该尽量尊重原文,因为怕读者会联想:
翻译这样有原文白纸黑字可以对照的东西,其中还掺杂这么多“技巧”和“变化”,其他没有原文白纸黑字对照的,会怎么样呢?
以上的“技巧”和“变化”还算好的,之前我批评过的《实现领域驱动设计》的翻译,和这对比简直就是儿戏:
《实现领域驱动设计》中译本和原文的评点纠错合集>>
这篇关于设计模式2个黄鹂鸣翠柳-《分析模式》漫谈23的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






