本文主要是介绍从零实现GPT【1】——BPE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Embedding 的原理
- 训练
- 特殊 token 处理和保存
- 编码
- 解码
- 完整代码
BPE,字节对编码
Embedding 的原理
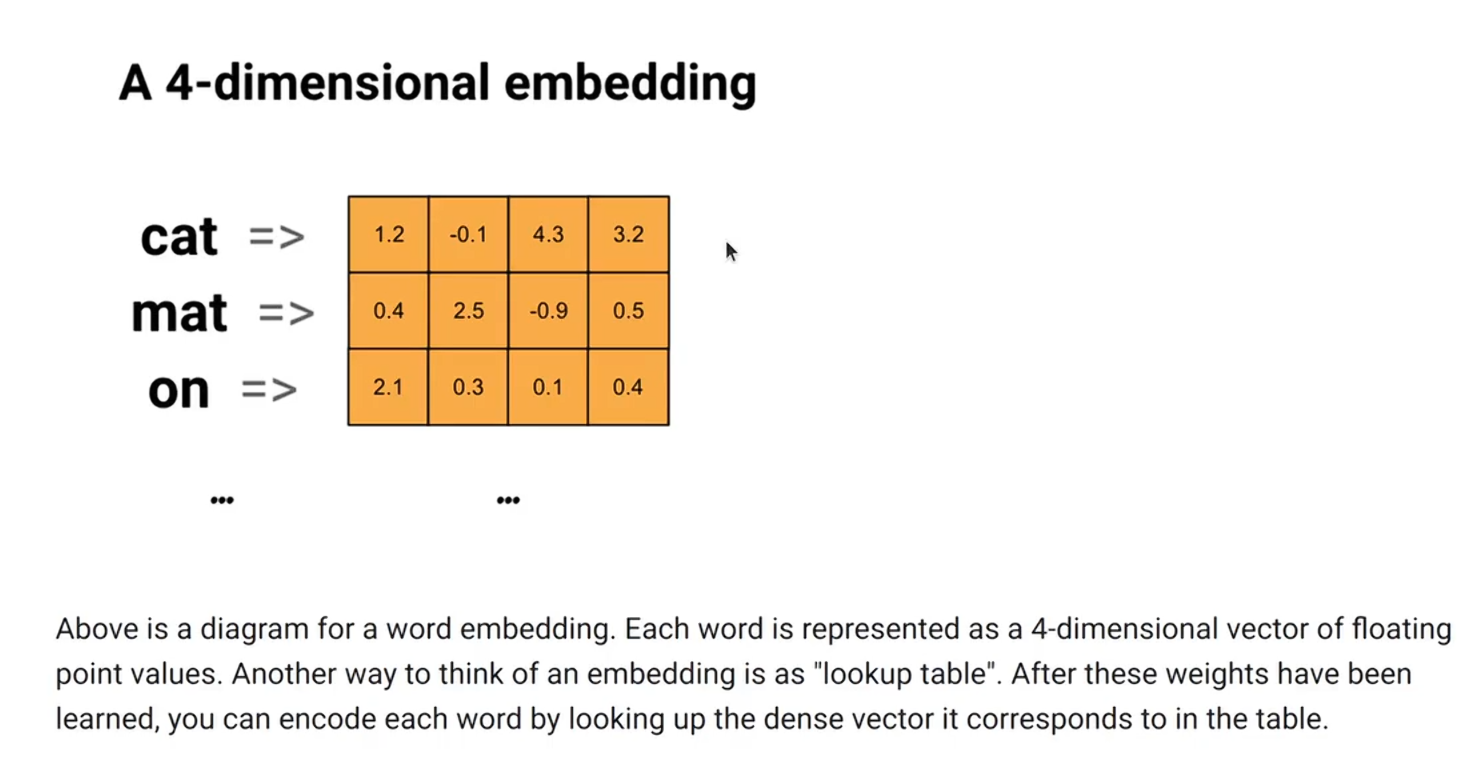
- 简单来说就是查表
# 解释embedding
from torch.nn import Embedding
import torch# 标准的正态分布初始化 也可以用均匀分布初始化
emb = Embedding(10, 32)
res = emb(torch.tensor([[0, 1, 2]
]))
print(res.shape) # torch.Size([1, 3, 32]) [batch, seq_len, dim]
- 自己实现
# 解释embedding
from torch.nn import Embedding, Parameter, Module
import torchclass MyEmbing(Module):def __init__(self, vocab_size, dim):super().__init__()self.emb_matrix = Parameter(torch.randn(vocab_size, dim))# Parameter标记self.emb_matrix需要被训练def forward(self, ids):return self.emb_matrix[ids] # 取索引这个操作可以反向传播emb = MyEmbedding(10, 32)
res = emb(torch.tensor([[0, 1, 2]
]))
print(res.shape) # torch.Size([1, 3, 32]) [batch, seq_len, dim]
训练
- 初始化词表,一般是 0-255 个 ASCII 编码
- 设置词表大小 Max_size
- 循环统计相邻两个字节的频率,取最高的合并后作为新的 token 加入到词表中
- 合并新的 token
- 重复 c、d,直到词表大小到Max_size 或者 没有更多的相邻 token
class BPETokenizer:def __init__(self):self.b2i = OrderedDict() # bytes to idself.i2b = OrderedDict() # id to bytes (b2i的反向映射)self.next_id = 0# special tokenself.sp_s2i = {} # str to idself.sp_i2s = {} # id to str# 相邻token统计def _pair_stats(self, tokens, stats):for i in range(len(tokens)-1):new_token = tokens[i]+tokens[i+1]if new_token not in stats:stats[new_token] = 0stats[new_token] += 1# 合并相邻tokendef _merge_pair(self, tokens, new_token):merged_tokens = []i = 0while i < len(tokens):if i+1 < len(tokens) and tokens[i]+tokens[i+1] == new_token:merged_tokens.append(tokens[i]+tokens[i+1])i += 2else:merged_tokens.append(tokens[i])i += 1return merged_tokensdef train(self, text_list, vocab_size):# 单字节是最基础的token,初始化词表for i in range(256):self.b2i[bytes([i])] = iself.next_id = 256# 语料转bytetokens_list = []for text in text_list:tokens = [bytes([b]) for b in text.encode('utf-8')]tokens_list.append(tokens)# 进度条progress = tqdm(total=vocab_size, initial=256)while True:# 词表足够大了,退出训练if self.next_id >= vocab_size:break# 统计相邻token频率stats = {}for tokens in tokens_list:self._pair_stats(tokens, stats)# 没有更多相邻token, 无法生成更多token,退出训练if not stats:break# 合并最高频的相邻token,作为新的token加入词表new_token = max(stats, key=stats.get)new_tokens_list = []for tokens in tokens_list:# self._merge_pair(tokens, new_token) -> listnew_tokens_list.append(self._merge_pair(tokens, new_token))tokens_list = new_tokens_list# new token加入词表self.b2i[new_token] = self.next_idself.next_id += 1# 刷新进度条progress.update(1)self.i2b = {v: k for k, v in self.b2i.items()}
特殊 token 处理和保存
- 特殊 token 加到词表中
tokenizer = BPETokenizer()# 特殊token
tokenizer.add_special_tokens((['<|im_start|>', '<|im_end|>', '<|endoftext|>', '<|padding|>']))# 特殊token
def add_special_tokens(self, special_tokens):for token in special_tokens:if token not in self.sp_s2i:self.sp_s2i[token] = self.next_idself.sp_i2s[self.next_id] = tokenself.next_id += 1
- 保存和加载
tokenizer.save('tokenizer.bin')def save(self, file):with open(file, 'wb') as fp:fp.write(pickle.dumps((self.b2i, self.sp_s2i, self.next_id)))# 还原
tokenizer = BPETokenizer()
tokenizer.load('tokenizer.bin')
print('vocab size:', tokenizer.vocab_size())def load(self, file):with open(file, 'rb') as fp:self.b2i, self.sp_s2i, self.next_id = pickle.loads(fp.read())self.i2b = {v: k for k, v in self.b2i.items()}self.sp_i2s = {v: k for k, v in self.sp_s2i.items()}
编码
- 分离特殊 token,用于直接映射特殊 token
- 进行编码,特殊 token 直接编码就好,普通 token 继续
while True:
- 对于普通 token, 统计相邻 token 频率
- 选择合并后的 id 最小的 pair token 合并(也就是优先合并短的)
- 重复 c d,直到没有合并的 pair token
不断循环 token,统计相邻 token 的频率,取 id 最小的 pair 进行合并,从而可以拼接成更大的 id
# 编码
ids, tokens = tokenizer.encode('<|im_start|>system\nyou are a helper assistant\n<|im_end|>\n<|im_start|>user\n今天的天气\n<|im_end|><|im_start|>assistant\n')
print('encode:', ids, tokens)
'''
encode:
[300, 115, 121, 115, 116, 101, 109, 10, 121, 111, 117, 32, 97, 114, 276, 97, 32, 104, 101, 108, 112, 101, 293, 97, 115, 115, 105, 115, 116, 97, 110, 116, 10, 301, 10, 300, 117, 115, 101, 114, 10, 265, 138, 266, 169, 261, 266, 169, 230, 176, 148, 10, 301, 300, 97, 115, 115, 105, 115, 116, 97, 110, 116, 10] [b'<|im_start|>', b's', b'y', b's', b't', b'e', b'm', b'\n', b'y', b'o', b'u', b' ', b'a', b'r', b'e ', b'a', b' ', b'h', b'e', b'l', b'p', b'e', b'r ', b'a', b's', b's', b'i', b's', b't', b'a', b'n', b't', b'\n', b'<|im_end|>', b'\n', b'<|im_start|>', b'u', b's', b'e', b'r', b'\n', b'\xe4\xbb', b'\x8a', b'\xe5\xa4', b'\xa9', b'\xe7\x9a\x84', b'\xe5\xa4', b'\xa9', b'\xe6', b'\xb0', b'\x94', b'\n', b'<|im_end|>', b'<|im_start|>', b'a', b's', b's', b'i', b's', b't', b'a', b'n', b't', b'\n']
''''''
在Python中,Unicode字符通常以"\x"开头,后面跟着两个十六进制数字,或者以"\u"开头,后面跟着四个十六进制数字。
'''def encode(self, text):# 特殊token分离pattern = '('+'|'.join([re.escape(tok) for tok in self.sp_s2i])+')'splits = re.split(pattern, text) # [ '<|im_start|>', 'user', '<||>' ]# 编码结果enc_ids = []enc_tokens = []for sub_text in splits:if sub_text in self.sp_s2i: # 特殊token,直接对应idenc_ids.append(self.sp_s2i[sub_text])enc_tokens.append(sub_text.encode('utf-8'))else:tokens = [bytes([b]) for b in sub_text.encode('utf-8')]while True:# 统计相邻token频率stats = {}self._pair_stats(tokens, stats)# 选择合并后id最小的pair合并(也就是优先合并短的)new_token = Nonefor merge_token in stats:if merge_token in self.b2i and (new_token is None or self.b2i[merge_token] < self.b2i[new_token]):new_token = merge_token# 没有可以合并的pair,退出if new_token is None:break# 合并pairtokens = self._merge_pair(tokens, new_token)enc_ids.extend([self.b2i[tok] for tok in tokens])enc_tokens.extend(tokens)return enc_ids, enc_tokens
解码
# 解码
s = tokenizer.decode(ids)
print('decode:', s)
'''
decode:
<|im_start|>system
you are a helper assistant
<|im_end|>
<|im_start|>user
今天的天气
<|im_end|><|im_start|>assistant
'''def decode(self, ids):bytes_list = []for id in ids:if id in self.sp_i2s:bytes_list.append(self.sp_i2s[id].encode('utf-8'))else:bytes_list.append(self.i2b[id]) # self.i2b 这里已经是字节了 id to byte return b''.join(bytes_list).decode('utf-8', errors='replace')
完整代码
from collections import OrderedDict
import pickle
import re
from tqdm import tqdm# Byte-Pair Encoding tokenizationclass BPETokenizer:def __init__(self):self.b2i = OrderedDict() # bytes to idself.i2b = OrderedDict() # id to bytes (b2i的反向映射)self.next_id = 0# special tokenself.sp_s2i = {} # str to idself.sp_i2s = {} # id to str# 相邻token统计def _pair_stats(self, tokens, stats):for i in range(len(tokens)-1):new_token = tokens[i]+tokens[i+1]if new_token not in stats:stats[new_token] = 0stats[new_token] += 1# 合并相邻tokendef _merge_pair(self, tokens, new_token):merged_tokens = []i = 0while i < len(tokens):if i+1 < len(tokens) and tokens[i]+tokens[i+1] == new_token:merged_tokens.append(tokens[i]+tokens[i+1])i += 2else:merged_tokens.append(tokens[i])i += 1return merged_tokensdef train(self, text_list, vocab_size):# 单字节是最基础的token,初始化词表for i in range(256):self.b2i[bytes([i])] = iself.next_id = 256# 语料转bytetokens_list = []for text in text_list:tokens = [bytes([b]) for b in text.encode('utf-8')]tokens_list.append(tokens)# 进度条progress = tqdm(total=vocab_size, initial=256)while True:# 词表足够大了,退出训练if self.next_id >= vocab_size:break# 统计相邻token频率stats = {}for tokens in tokens_list:self._pair_stats(tokens, stats)# 没有更多相邻token, 无法生成更多token,退出训练if not stats:break# 合并最高频的相邻token,作为新的token加入词表new_token = max(stats, key=stats.get)new_tokens_list = []for tokens in tokens_list:# self._merge_pair(tokens, new_token) -> listnew_tokens_list.append(self._merge_pair(tokens, new_token))tokens_list = new_tokens_list# new token加入词表self.b2i[new_token] = self.next_idself.next_id += 1# 刷新进度条progress.update(1)self.i2b = {v: k for k, v in self.b2i.items()}# 词表大小def vocab_size(self):return self.next_id# 词表def vocab(self):v = {}v.update(self.i2b)v.update({id: token.encode('utf-8')for id, token in self.sp_i2s.items()})return v# 特殊tokendef add_special_tokens(self, special_tokens):for token in special_tokens:if token not in self.sp_s2i:self.sp_s2i[token] = self.next_idself.sp_i2s[self.next_id] = tokenself.next_id += 1def encode(self, text):# 特殊token分离pattern = '('+'|'.join([re.escape(tok) for tok in self.sp_s2i])+')'splits = re.split(pattern, text) # [ '<|im_start|>', 'user', '<||>' ]# 编码结果enc_ids = []enc_tokens = []for sub_text in splits:if sub_text in self.sp_s2i: # 特殊token,直接对应idenc_ids.append(self.sp_s2i[sub_text])enc_tokens.append(sub_text.encode('utf-8'))else:tokens = [bytes([b]) for b in sub_text.encode('utf-8')]while True:# 统计相邻token频率stats = {}self._pair_stats(tokens, stats)# 选择合并后id最小的pair合并(也就是优先合并短的)new_token = Nonefor merge_token in stats:if merge_token in self.b2i and (new_token is None or self.b2i[merge_token] < self.b2i[new_token]):new_token = merge_token# 没有可以合并的pair,退出if new_token is None:break# 合并pairtokens = self._merge_pair(tokens, new_token)enc_ids.extend([self.b2i[tok] for tok in tokens])enc_tokens.extend(tokens)return enc_ids, enc_tokensdef decode(self, ids):bytes_list = []for id in ids:if id in self.sp_i2s:bytes_list.append(self.sp_i2s[id].encode('utf-8'))else:bytes_list.append(self.i2b[id]) # self.i2b 这里已经是字节了 id to bytereturn b''.join(bytes_list).decode('utf-8', errors='replace')def save(self, file):with open(file, 'wb') as fp:fp.write(pickle.dumps((self.b2i, self.sp_s2i, self.next_id)))def load(self, file):with open(file, 'rb') as fp:self.b2i, self.sp_s2i, self.next_id = pickle.loads(fp.read())self.i2b = {v: k for k, v in self.b2i.items()}self.sp_i2s = {v: k for k, v in self.sp_s2i.items()}if __name__ == '__main__':# 加载语料cn = open('dataset/train-cn.txt', 'r').read()en = open('dataset/train-en.txt', 'r').read()# 训练tokenizer = BPETokenizer()tokenizer.train(text_list=[cn, en], vocab_size=300)# 特殊tokentokenizer.add_special_tokens((['<|im_start|>', '<|im_end|>', '<|endoftext|>', '<|padding|>']))# 保存tokenizer.save('tokenizer.bin')# 还原tokenizer = BPETokenizer()tokenizer.load('tokenizer.bin')print('vocab size:', tokenizer.vocab_size())# 编码ids, tokens = tokenizer.encode('<|im_start|>system\nyou are a helper assistant\n<|im_end|>\n<|im_start|>user\n今天的天气\n<|im_end|><|im_start|>assistant\n')print('encode:', ids, tokens)# 解码s = tokenizer.decode(ids)print('decode:', s)# 打印词典print('vocab:', tokenizer.vocab())
这篇关于从零实现GPT【1】——BPE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






