本文主要是介绍如何利用数据仓库进行业务分析:一名大数据工程师的视角,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在大数据时代,数据的有效利用对企业的成功至关重要。
本文将基于上面的流程图,详细介绍如何利用数据仓库进行业务分析,并提供实际的例子和代码演示,以帮助读者更好地理解和应用相关技术。
数据仓库的基本流程
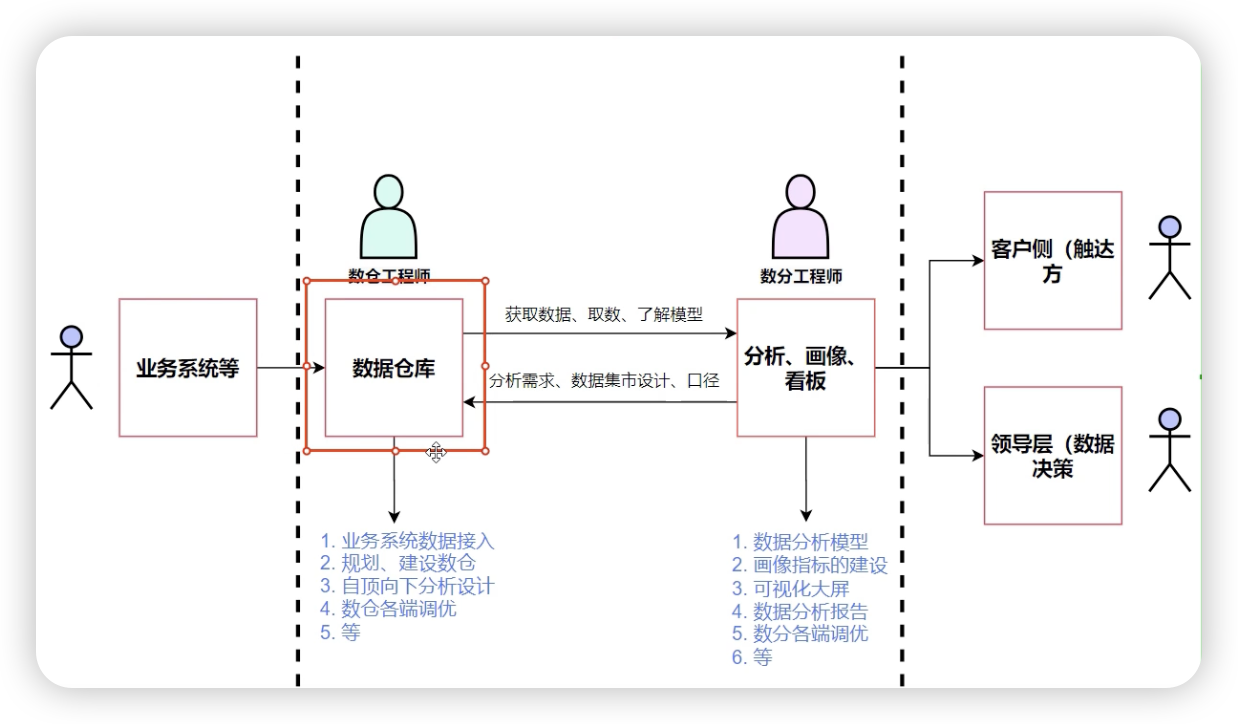
上图展示了一个典型的数据仓库流程,包括以下几个主要环节:
- 业务系统数据接入:业务系统等数据源将数据导入数据仓库。
- 数据仓库建设:规划、建设数据仓库,包括数据模型设计和数据集成。
- 数据分析需求获取:数据分析师根据业务需求获取数据、理解数据模型。
- 数据分析和可视化:通过分析和可视化工具(如报表、看板)展示数据结果。
接下来,我们将详细讲解每个环节的实现过程,并通过示例和代码进行说明。
数据接入和数据仓库建设
数据接入是整个流程的起点,通常包括从多个业务系统获取数据并存入数据仓库。以下是一个简单的数据接入代码示例,假设我们要将一个CSV文件导入到Hive中:
数据接入
使用Python和PyHive库将数据从CSV文件导入到Hive表中:
import pandas as pd
from pyhive import hive# 读取CSV文件
data = pd.read_csv('path/to/your/data.csv')# 创建Hive连接
conn = hive.Connection(host='your_hive_host', port=10000, username='your_username')# 将数据写入Hive表
with conn.cursor() as cursor:for index, row in data.iterrows():cursor.execute(f"INSERT INTO your_table_name VALUES ({row['column1']}, '{row['column2']}', ...)")print("Data imported successfully.")
数据仓库的构建
构建数据仓库通常涉及设计数据模型、创建表结构等步骤。以下是一个在Hive中创建用户信息表的SQL示例:
CREATE TABLE users (user_id INT,name STRING,email STRING,signup_date STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
数据分析需求获取
数据分析需求获取是确保数据分析师能够准确获取所需数据的关键步骤。数据分析师需要与业务团队沟通,明确分析需求,然后从数据仓库中提取相关数据。
以下是一个从Hive数据仓库中提取数据的示例,使用Python和PyHive:
# 查询数据
query = "SELECT user_id, name, email FROM users WHERE signup_date > '2023-01-01'"# 执行查询并获取数据
result = pd.read_sql(query, conn)print(result.head())
数据分析和可视化
数据分析是数据仓库流程的最终目的,通过分析和可视化工具,业务团队可以更直观地理解数据并做出决策。
以下是一个使用Matplotlib进行简单数据可视化的示例:
import matplotlib.pyplot as plt# 计算用户注册数量
signup_counts = result['signup_date'].value_counts()# 绘制注册数量曲线
signup_counts.plot(kind='line')
plt.title('User Signups Over Time')
plt.xlabel('Date')
plt.ylabel('Number of Signups')
plt.show()
总结
通过以上步骤,我们可以构建一个完整的数据仓库流程,从数据接入、数据仓库建设到数据分析和可视化。每个环节都有其独特的重要性,只有各环节协同工作,才能充分发挥数据的价值。
希望这篇文章和示例代码能帮助你更好地理解和实施数据仓库相关的工作。
这篇关于如何利用数据仓库进行业务分析:一名大数据工程师的视角的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






