本文主要是介绍NASA数据集:非洲季风多学科分析African Monsoon Multidisciplinary Analyses (AMMA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
African Monsoon Multidisciplinary Analyses (AMMA)
非洲季风多学科分析:国际研究项目和实地活动
简介
非洲季风多学科分析(AMMA)是一个国际项目,旨在提高我们对西非季风(WAM)及其变异性的认识和了解,重点是日到年的时间尺度。推动 AMMA 项目的动力是对基础科学问题的兴趣,以及改进西非季风及其对西非国家影响预测的社会需求。认识到社会需要制定战略来减少世界气象组织变化对社会经济的影响,非洲气象学和海洋学 协会将促进必要的多学科研究,以提供更好的世界气象组织预测及其影响。这将通过以下五个国际工作组来实现和协调:i) 西非季风和全球气候;ii) 水循环;iii) 地表-大气反馈;iv) 气候影响预测;v) 高影响天气预测和可预测性。
AMMA 促进正在开展的活动、基础研究以及西非和热带大西洋多年实地活动的国际协调。非洲气象学和海洋学部长级会议正在世界气象组织基础研究、业务预报和决策参与 者之间建立密切的伙伴关系,并正在为非洲人开展混合培训和教育活动。
AMMA得到了世界气候研究计划(WCRP)的认可,并继续与气候变异性和可预测性(CLIVAR)以及全球能源和水循环实验(GEWEX)合作发展。AMMA还得到了国际地圈生物圈计划(IGBP)中两个项目的认可:国际全球大气化学(IGAC)和陆地生态系统-大气过程综合研究(ILEAPS)。 AMMA 正在与其他国际项目和计划合作,以实现其目标,包括全球气候观测系统(GCOS)、全球海洋观测系统(GOOS)和观测系统研究与可预测性实验(THORPEX)。
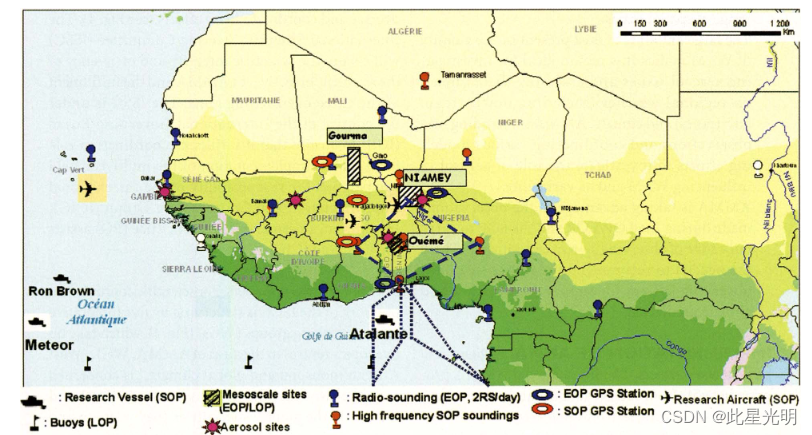
WAM 的年际和年代际变率有据可查,并激发了大量研究工作(如 Nicholson,1981 年;Lamb,1983 年;Folland 等,1986 年;Fontaine 和 Janicot,1996 年;Le Barbe 等,2002 年)。 整个地区从 20 世纪 50 年代和 60 年代的湿润条件急剧转变为 70 年代、80 年代和 90 年代的干燥条件,这是 20 世纪地球上最强烈的年代际信号之一。 在此基础上,近几十年来明显的年际变化导致极端干旱的年份,对环境和社会经济造成了破坏性影响。这种变异性提出了与该地区可持续性、土地退化以及粮食和水安全相关的重要问题。
代码
!pip install leafmap
!pip install pandas
!pip install folium
!pip install matplotlib
!pip install mapclassifyimport pandas as pd
import leafmapurl = "https://github.com/opengeos/NASA-Earth-Data/raw/main/nasa_earth_data.tsv"
df = pd.read_csv(url, sep="\t")
dfleafmap.nasa_data_login()results, gdf = leafmap.nasa_data_search(short_name="AMMA",cloud_hosted=True,bounding_box=(-180.0, -90.0, 180.0, 90.0),temporal=("2006-06-25", "2017-08-08"),count=-1, # use -1 to return all datasetsreturn_gdf=True,
)gdf.explore()#leafmap.nasa_data_download(results[:5], out_dir="data")引用
African Monsoon Multidisciplinary Analysis: An International Research Project and Field Campaign in: Bulletin of the American Meteorological Society Volume 87 Issue 12 (2006)
网址推荐
0代码在线构建地图应用
https://invite.mapmost.com/#/login?source_inviter=nClSZANO
机器学习
https://www.cbedai.net/xg
这篇关于NASA数据集:非洲季风多学科分析African Monsoon Multidisciplinary Analyses (AMMA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






