本文主要是介绍数据可视化实验一:Panda数据处理及matplotlib绘图初步,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
2024-6-17
一、请将所有含有发明家“吴峰”的发明专利的“申请日”打印出来。并将含有“吴峰”的所有发明专利条目保存到Excel中
1.1 代码实现
1.2 运行结果
二、读取文件创建城市、人口、性别比、城镇化率DataFrame对象,计算指标排名,尝试使用plot绘图
2.1 代码实现
2.2 绘制结果
一、请将所有含有发明家“吴峰”的发明专利的“申请日”打印出来。并将含有“吴峰”的所有发明专利条目保存到Excel中
1.1 代码实现
# 实验要求:请将 所有含有发明家“吴峰”的发明专利的“申请日”打印出来。并将含有“吴峰”的所有发明专利条目保存到Excel中# 导入pandas库
import pandas as pd# 从 Excel 读取数据
df = pd.read_excel("实验课数据1.xlsx")# 筛选出含有发明家“吴峰”的发明专利的“申请日”
filed_df = df[df["发明人"].str.contains("吴峰")]# 打印含有发明家“吴峰”的发明专利的“申请日”
print(filed_df[["申请日"]])# 保存含有“吴峰”的所有发明专利条目到 Excel 中
filed_df.to_excel("含有‘吴峰’的发明专利.xlsx", index=False)1.2 运行结果
(1)原数据“实验课数据1.xlsx”

(2)筛选后的结果

(申请号不一样的原因是系统自动转换的结果)
(3)打印申请日

二、读取文件创建城市、人口、性别比、城镇化率DataFrame对象,计算指标排名,尝试使用plot绘图
2.1 代码实现
# 实验要求:读取文件创建城市、人口、性别比、城镇化率DataFrame对象,计算指标排名,尝试使用plot绘图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm# 设置字体
plt.rcParams['font.family'] = ['Arial Unicode MS']# data=pd.read_excel('江西省2021年人口普查.xlsx ', engine='openpyxl')
# 创建包含城市、人口、性别比、城镇化率的 DataFrame,江西省不属于城市,不放入考虑范围
data = {'城市': ['南昌市', '景德镇市', '萍乡市', '九江市', '新余市', '鹰潭市', '赣州市', '吉安市', '宜春市', '抚州市', '上饶市'],'年末常住人口(万人)': [643.75, 162.06, 180.59, 456.07, 120.21, 115.5, 898, 442.51, 497.11, 357.94, 643.67],'总人口性别比(女性=100)': [109.98, 107.77, 103.8, 105.56, 109.45, 107.73, 106.02, 106.73, 107.04, 107.22, 106.71],'常住人口城镇化率(%)': [78.64, 65.94, 68.77, 62.15, 74.14, 65.43, 56.35, 53.41, 57.38, 57.96, 55.31]
}df = pd.DataFrame(data)
print(df)
# 计算指标排名
df['人口排名'] = df['年末常住人口(万人)'].rank(ascending=False)
df['性别比排名'] = df['总人口性别比(女性=100)'].rank(ascending=True)
df['城镇化率排名'] = df['常住人口城镇化率(%)'].rank(ascending=False)# 可视化数据
plt.figure(figsize=(12, 6))
plt.show()# 每个部分设置不同的颜色
plt.subplot(1, 3, 1)
df[['城市', '人口排名']].set_index('城市').plot(kind='bar', color='skyblue')
plt.title('人口排名')
plt.show()plt.subplot(1, 3, 2)
df[['城市', '性别比排名']].set_index('城市').plot(kind='bar', color='salmon')
plt.title('性别比排名')
plt.show()plt.subplot(1, 3, 3)
df[['城市', '城镇化率排名']].set_index('城市').plot(kind='bar', color='lightgreen')
plt.title('城镇化率排名')plt.tight_layout()
plt.show()2.2 绘制结果
(1)创建的DataFrame对象

(2)然后进行指标排名,绘图结果如下
I 按照人口排名
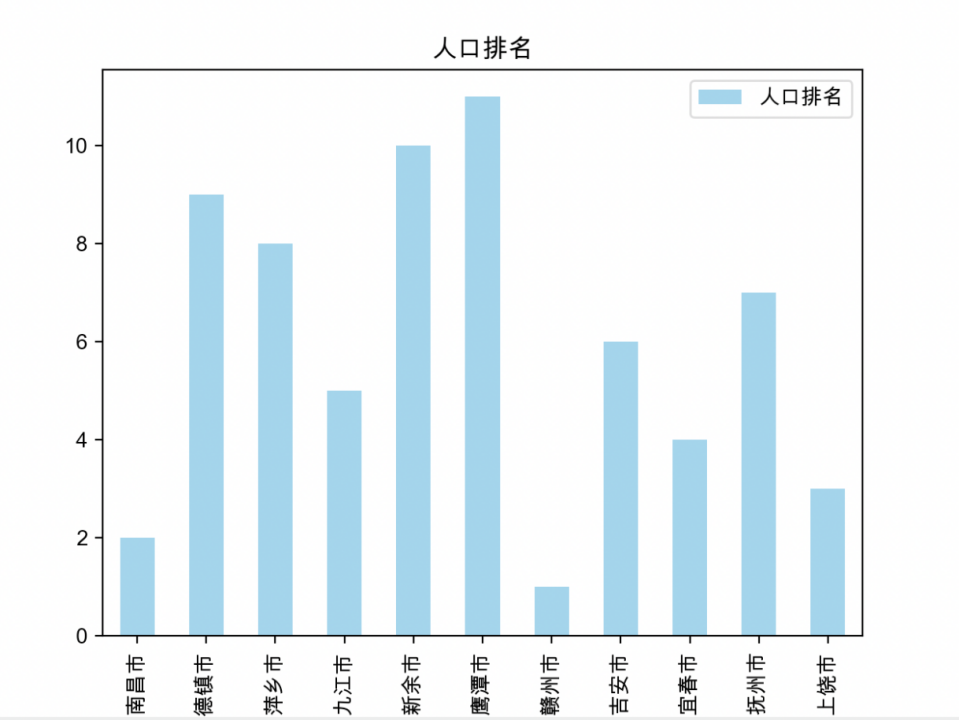
绘制结果如下,由于是根据人口排名而不是人口数量进行柱状图绘制,因此可以很直观的看出赣州市的人口数量最多;相反,鹰潭市的人口数量最少。
II 按照性别比排名
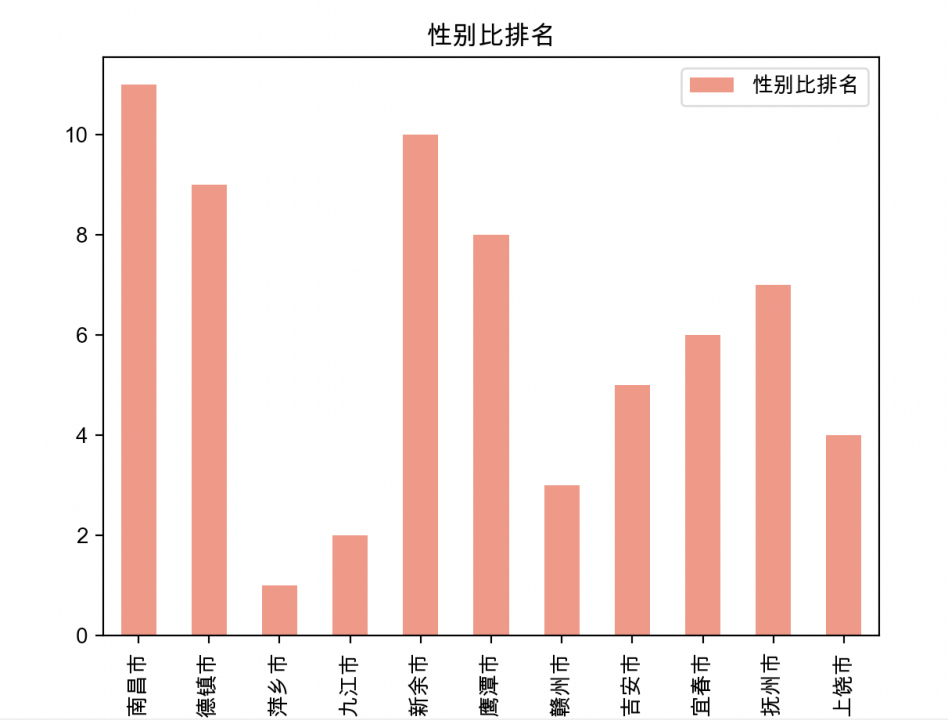
由上述图形可以看出,萍乡市的性别比排名第一,而南昌市则是最后一名。
III 按照城镇化率排名
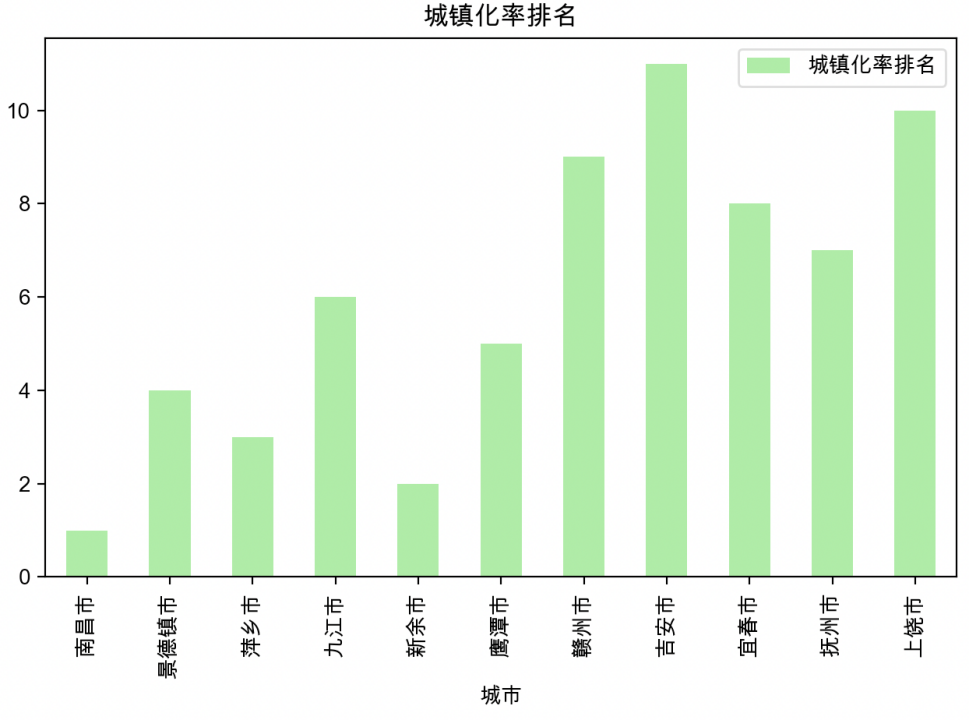
由上图可以看出南昌市的城镇化率是全省最高的,而吉安的城镇化率则居全省末尾。
--------------------
期末加油!
这篇关于数据可视化实验一:Panda数据处理及matplotlib绘图初步的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





