本文主要是介绍英伟达发布Nemotron-4 340B通用模型:专为生成合成数据设计的突破性AI,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
2023年6月14日,英伟达发布了Nemotron-4 340B通用模型,专为生成训练大语言模型的合成数据而设计。这一模型可能彻底改变训练大模型时合成数据的生成方式,标志着AI行业的一个重要里程碑。本文将详细介绍Nemotron-4 340B的各个方面,包括其性能、设计特点、训练数据以及实际应用和潜在影响。
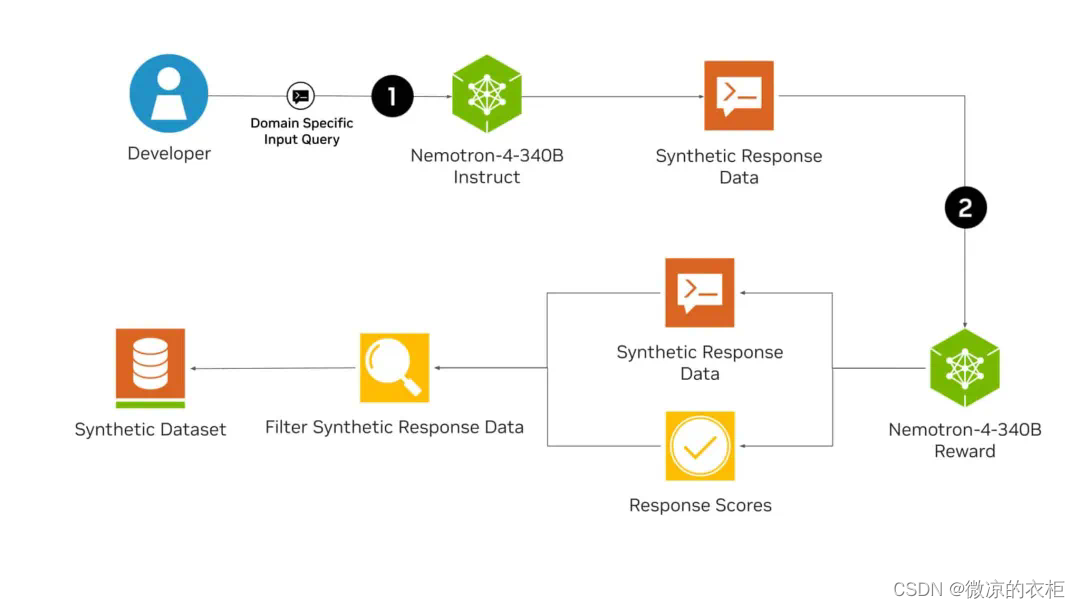
在这个合成数据 pipeline 中,(1)Nemotron-4 340B Instruct 模型用于生成基于文本的合成输出。然后,评估模型(2) Nemotron-4 340B Reward 评估生成的文本并提供反馈,从而指导迭代改进并确保合成数据的准确。
Nemotron-4 340B模型概述
三个版本的模型
Nemotron-4 340B包括基础模型Base、指令模型Instruct和奖励模型Reward。这些模型共同构建了一个生成高质量合成数据的完整流程,支持多达50多种自然语言和40多种编程语言,使用了高达9万亿个token进行训练。
性能表现
在多项基准测试中,Nemotron-4 340B的表现令人印象深刻。基础模型在常识推理任务(如ARC-Challenge、MMLU和BigBench Hard)中可以媲美或超越Llama-3 70B、Mixtral 8x22B和Qwen-2 72B模型。指令模型在指令跟随和聊天能力方面也表现出色,而奖励模型在RewardBench上实现了最高的准确性,甚至超过了一些专有模型如GPT-4o-0513和Gemini 1.5 Pro-0514。
设计特点与技术细节
合成数据生成与质量提升
Nemotron-4 340B的一个关键特点是能够生成高质量的合成训练数据。这些数据模仿了真实世界的数据特征,显著提升了各个领域定制大语言模型的性能和稳定性。为了进一步提高数据质量,开发者可以使用奖励模型来筛选高质量的响应,并根据有用性、正确性、一致性、复杂性和冗长性这五个属性对响应进行评分。
预训练数据与模型架构
模型的预训练数据截止到2023年6月,基于三种不同类型的混合数据,共计9万亿token。其中70%的数据是英语自然语言,15%是多语种自然语言(包含53种语言),另外15%是代码(包含43种编程语言)。模型基于仅解码器的Transformer架构,使用了因果注意力掩码、旋转位置嵌入(RoPE)、SentencePiece分词器和分组查询注意力(GQA)等技术。
分布式训练与推理优化
Nemotron-4 340B在768个DGX H100节点上进行训练,每个节点包含8个H100 80GB SXM5 GPU,采用了8路张量并行、12路交错流水线并行和数据并行相结合的方法。在推理方面,利用开源的NVIDIA NeMo和NVIDIA TensorRT-LLM框架,开发者可以优化指令模型和奖励模型的效率,从而生成合成数据并对响应进行评分。
实际应用与潜在影响
医疗领域
在医疗领域,Nemotron-4 340B可以生成高质量的合成数据,可能会带来药物发现、个性化医疗和医学影像方面的突破。合成数据能够弥补真实数据的不足,提供更多样化和丰富的训练数据,从而提高AI模型的准确性和可靠性。
金融领域
在金融领域,基于合成数据训练的定制大语言模型可能会彻底改变欺诈检测、风险评估和客户服务。合成数据可以模拟各种复杂的金融场景和行为,为模型提供更加全面的训练,从而提升其识别和预测能力。
制造业与零售业
在制造业和零售业方面,特定领域的大模型可以实现预测性维护、供应链优化和个性化客户体验。合成数据的使用使得AI模型能够更好地理解和预测市场需求和趋势,提高运营效率和客户满意度。
挑战与未来展望
尽管Nemotron-4 340B在合成数据生成和AI模型训练方面表现出色,但也提出了一些隐忧。例如,如何保证数据隐私和安全?用合成数据训练AI模型是否会引发伦理问题?这些问题需要在未来的研究和应用中得到进一步解决。
总的来说,Nemotron-4 340B的发布展示了合成数据在AI训练中的巨大潜力和广泛应用前景。随着技术的不断进步和完善,合成数据将成为AI发展的重要驱动力,推动各行各业实现新的突破和创新。

这篇关于英伟达发布Nemotron-4 340B通用模型:专为生成合成数据设计的突破性AI的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





