本文主要是介绍码住!详解时序数据库不同分类与性能对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

加速发展中的时序数据库,基于不同架构,最流行的类别是?
作为管理工业场景时序数据的新兴数据库品类,时序数据库凭借着对海量时序数据的高效存储、高可扩展性、时序分析计算等特性,一跃成为物联网时代工业领域颇受欢迎的数据库。
从诞生到发展至今,时序数据库应用的关键技术也在不断进步。其中,管理海量时序数据,为其适配灵活、高压缩、支持高读写性能的存储架构便是亟需解决的难点之一。
根据存储架构的不同,时序数据库可以进一步分类。本文将详细解析三种不同存储架构下,每一类时序数据库的特点,及其对时序数据的读写、压缩等性能。
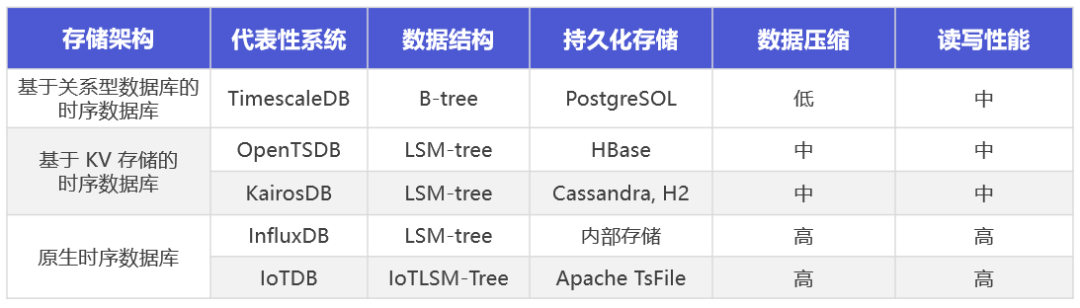
三类时序数据库的存储架构分类、代表性系统与性能对比
01
基于关系型数据库的时序数据库
在没有专门管理时序数据的数据库之前,人们通常使用关系型数据库管理时序数据。
关系型数据库通常基于 B+tree 数据结构,这种数据结构在处理单个时间序列的批量数据写入时具有很高的性能。但是随着时序数据规模的不断增长,这种数据结构在同时处理数千、数万个时间序列的批量数据写入请求时,性能会急剧下降。
因此,在海量时序数据写入的工业场景中,关系型数据库的性能会显得捉襟见肘,并不适用。
部分时序数据库继承了关系型数据库的生态优势,如原生支持标准 SQL 语法,并通过扩展关系型数据库以优化时序数据存储。这类时序数据库在数据写入后建立针对时序数据的表模型,并按时间分区进行数据点的分区存储和压缩,最终写入关系型数据库中。
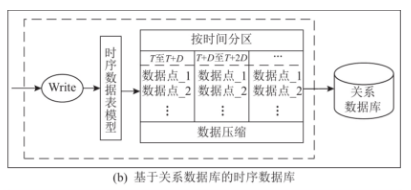
该类时序数据库的典型代表如 TimescaleDB,其通过扩展关系型数据库 PostgreSQL 实现时序数据管理。TimescaleDB 通过在 PostgreSQL 的查询计划器、数据模型和执行引擎添加钩子,可以构建高度定制化的扩展层。基于该扩展模型,TimescaleDB 可以利用 PostgreSQL 的多个属性,例如可靠性、安全性以及丰富的第三方工具。
总结来看,基于关系型数据库的时序数据库提供了全部的 SQL 功能,但由于无法避免时序数据场景中不需要的事务保证,对读写性能具有较大副作用。且由于关系型数据库基于行式存储构建时序数据的表模型,对于测点数、数据量大的时序数据来说,写入速度和压缩比相比采用列式存储的时序数据库,会有较大的差距,其分布式架构的可扩展性也存在短板。
02
基于 KV 存储的时序数据库
基于 KV (key-value)存储的时序数据库,通过扩展 NoSQL 数据库实现时序数据存储,其将写入的时序数据解析后,构建成 KV 模型,并以 KV 形式将数据持久化在分布式文件系统上。一组键值对中,key 是由测量指标、标签组合、测量字段键构成,value 则是由测量字段值和时间戳构成。
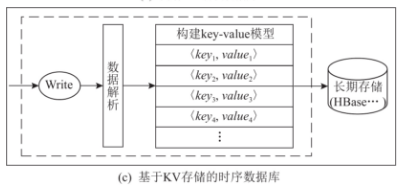
该类数据库的代表是 OpenTSDB,其使用了日志结构合并树(log structured merge tree,LSM-tree)的数据结构。这是一种针对写入密集的工作负载优化的数据结构,非常适合时序数据写入频率高、体量大的应用场景。
LSM-tree 结构由三部分组成:预写日志(WAL)、内存表(分为可变内存表和不可变内存表)和排序字符串表(sorted string table,sstable)。
在此结构下写入或更新数据时,每条 KV 数据将以追加的方式写入预写日志(WAL),相同的数据也被再次写入可变内存表中,这个内存表也就是时序数据的缓存表。当可变内存表的大小达到阈值后,会变成不可变内存表,并首先对其缓存的数据按照 key 的字典顺序排序,然后将排序后的 KV 数据以数据块的形式顺序写入 sstable 文件。
需要注意的是,LSM-tree 层级(level)中只能容纳一定大小的 sstable 文件,不同文件之间可能存在 key 范围重叠的情况,这时会触发合并操作。数据库会将当前层级中与下一层级中存在 key 范围重叠的 sstable 文件合并写入一个新的 sstable 文件。
总体而言,基于 KV 存储的时序数据库运用 LSM-tree 结构,具有高通量写入的天然性能优势,再加上使用了分布式文件系统,因此具有很高的扩展性。
但是这类数据库也存在一定的问题。由于合并操作的存在,相同的数据会在不同层级之间重复写入,因此产生了写放大问题,从而导致数据的写入吞吐量降低。同时,时序数据通常具有多个标签组合,当标签集的数据量增加时,基于标签组合的 key 的数量会急剧膨胀,而 key 通常是在内存中索引的,所以内存资源占用也会急剧增加。
03
原生时序数据库
原生时序数据库是面向时序数据存储全新研发的时序数据库。该类型时序数据库不依赖第三方存储,使用列式存储,提供极致的数据写入、查询和压缩能力,部署和运维更加简单。
从下图可以看出,这类数据库灵活运用了时序索引、数据缓存、数据分区、预写日志等多类设计,在存储结构 LSM-tree 的基础上,旨在全面提升全链路的时序数据管理性能。
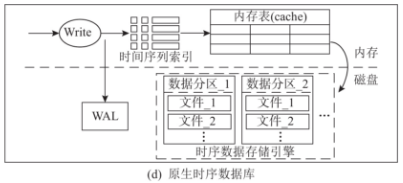
原生时序数据库的代表是 InfluxDB 和 IoTDB。InfluxDB 在其类似 LSM-tree 的 TSM-tree 结构中,引入了 series-key 的概念,根据时间特征对数据实现了很好的分类,从而有效减少了冗余存储,提高了数据压缩率。
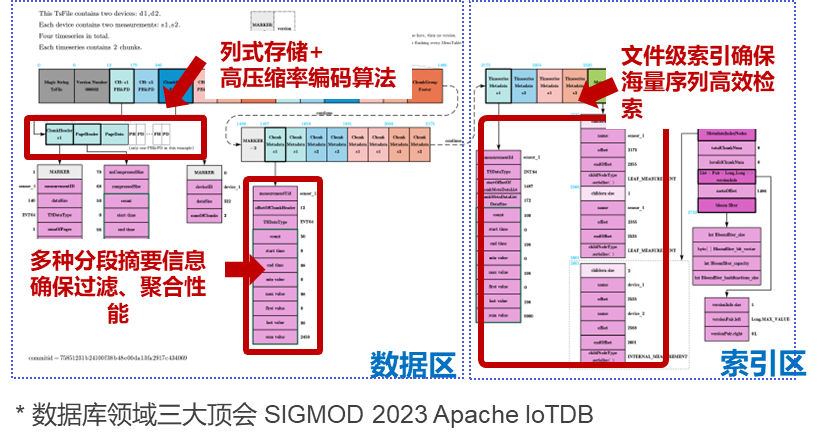
IoTDB 则依靠自研的时序数据标准文件格式 Apache TsFile,为其写入、压缩、查询的优异性能提供了良好的基础。TsFile 是 IoTDB 的底层数据文件存储格式,其结构分为数据区与索引区,通过索引区的文件级索引,并仅将必要的数据列加载到内存中,TsFile 可实现海量序列低延迟查询;通过数据区的多种分段摘要信息,TsFile 能够保障 IoTDB 的数据过滤、聚合性能。
同时,TsFile 支持列式存储,并采用二阶差分编码、游程编码(RLE)、位压缩和 Snappy 等先进的编码和压缩技术,优化时序数据的存储和访问,实现时序数据高压缩比,相比 InfluxDB 磁盘空间占用可降低 80%。TsFile 也支持对时间戳列和数据值列进行单独编码,以达到更好的数据处理效能。
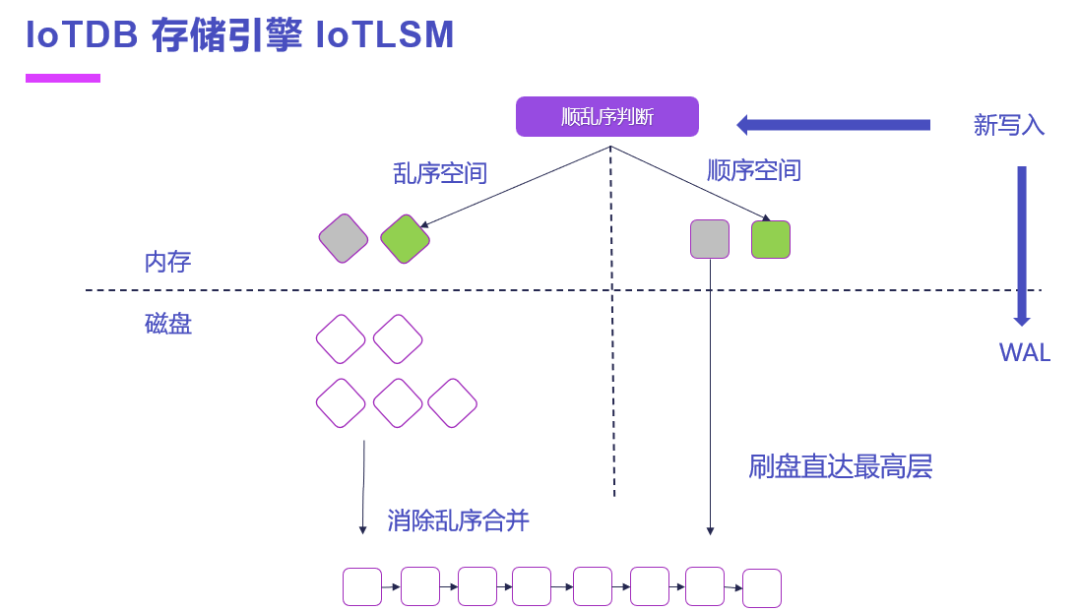
基于 TsFile 文件格式,IoTDB 进一步自研构建了顺乱序分离引擎 IoTLSM。当新数据写入时,首先记入预写日志(WAL),通过 IoTDB 独有的顺乱序判断机制,将这个数据分到顺序空间或乱序空间。
如果数据分到顺序空间,并触发刷盘,存储引擎会直接将数据文件刷到最高层,这便对顺序数据实现了最优先、最优化的处理。如果数据分到乱序空间,IoTDB 会通过多种空间类合并、跨空间合并方法消除乱序文件,从而解决了工业场景出现乱序数据、影响写入性能的痛点。
最后,对于前文提到的 LSM-tree 结构合并操作导致的写放大问题,IoTDB 的存储引擎结构也会明显地降低数据的写入次数、保障数据的高吞吐性能。可见,原生时序数据库在保障性能表现的基础上,通过其特性的各类技术,对于前文类型中数据库的结构痛点也能够进行优化。
04
总结
时序数据库的打造是一个系统工程,单个算法和机制不能决定一个时序数据库的性能和用户体验,需要将各个优化算法和处理机制统一融合到一个整体的系统中,来提高时序数据库的读写、压缩性能,其中也经常需要在不同技术之间进行权衡、互相补充。在时序数据库的众多架构路线中,原生时序数据库架构在迭代中受到的限制更小,能够更快地进行演进,这也是此类数据库最为流行的原因。
尽管时序数据库已经实现一些突破,但相关核心技术仍在飞速发展中,可以预见未来将有更多更新颖的架构、方法被提出,不妨祝愿现有的各类时序数据库产品加速发展,期待未来有更多高性能、高稳定性的新型产品出现,从而更好地挖掘急剧增加、亟待管理的工业数据价值。





这篇关于码住!详解时序数据库不同分类与性能对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





