本文主要是介绍Ubuntu20.04配置ORBSLAM2并在kitti数据集序列进行实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、ORB-SLAM2 安装和编译
1.ORB-SLAM2下载
用以下命令在终端上下载
git clone https://github.com/raulmur/ORB_SLAM2
2.安装Pangolin
在下载了ZIP压缩包后解压缩放在ubantu的/home下(此处只要是英文路径都可以),但别急着安装Pangolin我们还需要安装一些必要的库
sudo apt install libgl1-mesa-dev sudo apt-get install libglew-dev sudo apt-get install libboost-dev libboost-thread-dev libboost-filesystem-dev sudo apt-get install libpython2.7-dev
接下来就可以安装Pangolin了
cd Pangolin mkdir build cd build cmake .. cmake --build .
3.安装OpenCV3
自己去官网下个opencv3系列,下载完成后,将其提取到主目录。,将该文件夹重命名为opencv3。
sudo apt-get install cmake sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg-dev libswscale-dev libtiff5-dev sudo apt-get install libgtk2.0-dev sudo apt-get install pkg-config
解压后,将文件夹放自己喜欢的地方,将解压后的文件夹重新命为opencv3
在opencv3文件夹下新建build文件夹
终端运行
make build
进入build文件夹下
cd build
在build目录下运行
sudo cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
编译
sudo make -j8
sudo make install
修改ld.so.conf文件 用gedit打开/etc/ld.so.conf 在文件中加上一行 /usr/loacal/lib 其中/user/loacal是opencv安装路径也就是makefile中指定的安装路径 终端执行
sudo gedit /etc/ld.so.conf
输入
include /usr/local/lib
保存退出
运行下面语句刷新库链接配置
sudo ldconfig
终端执行
sudo gedit /etc/bash.bashrc
在文件末尾加入
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig export PKG_CONFIG_PATH

保存退出
然后在命令行中输入刷新
source /etc/bash.bashrc
在命令行中输入如下命令
pkg-config opencv --modversion

4.安装Eigen3
ZIP文件下载后解压放到ubantu中,进入eigen文件加中执行以下步骤
mkdir build cd build cmake .. sudo make install
5.Ceres安装
先安装依赖项:sudo apt-get install liblapack-dev libsuitesparse-dev libcxsparse3 libgflags-dev libgoogle-glog-dev libgtest-dev git clone https://github.com/ceres-solver/ceres-solver.git 编译: cd ceres-solver mkdir build && cd build cmake .. sudo make -j8 sudo make install
6.DBoW3安装
git下来 mkdir build cd build/ cmake .. make sudo make install
7.g2o安装

安装依赖:sudo apt-get install qt5-qmake qt5-default libqglviewer-dev-qt5 libsuitesparse-dev libcxsparse3 libcholmod3 git下来 编译: cd g2o mkdir build && cd build cmake .. sudo make -j8 sudo make install
8.安装运行ORB_SLAM2
cd ORB_SLAM2 chmod +x build.sh ./build.sh

二、运行Kitee数据集
数据集准备
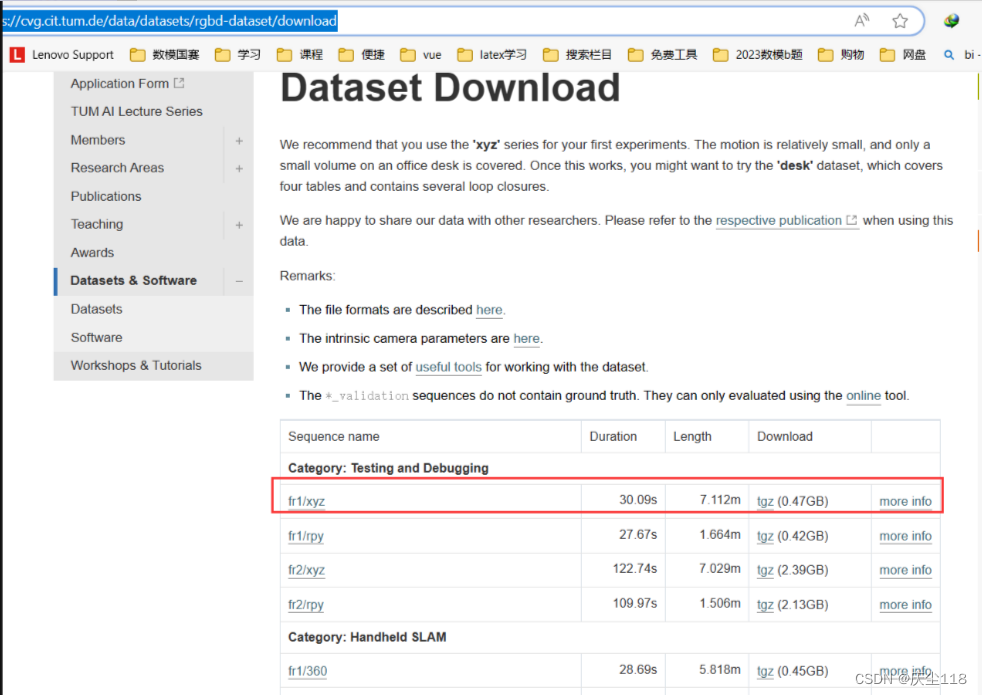
下载好后,进入ORB_SLAM2文件夹创建一个文件夹:data,将下载好的数据集压缩包提取到data下面,然后打开一个新终端输入以下命令

cd ORB_SLAM2 ./Examples/Monocular/mono_tum Vocabulary/ORBvoc.txt Examples/Monocular/TUM1.yaml data/rgbd_dataset_freiburg1_xyz

这篇关于Ubuntu20.04配置ORBSLAM2并在kitti数据集序列进行实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






