本文主要是介绍Mac M3 Pro 部署Spark-2.3.2 On Hive-3.1.3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
mac的配置如下

1、下载安装包
官网
Apache Projects Releases
在search中搜索hadoop、hive
spark : Index of /dist/spark/spark-2.3.2
网盘
Hadoop https://pan.baidu.com/s/1p4BXq2mvby2B76lmpiEjnA?pwd=r62r 提取码: r62r
Hive https://pan.baidu.com/s/12PUQfy_mi914wd6p7iWsBw?pwd=bnrr 提取码: bnrr
Spark二进制包 https://pan.baidu.com/s/1fJ5yRH_9K7VFlixBJ1MH1g?pwd=v987 提取码: v987
Spark源码打好的包 https://pan.baidu.com/s/1H0OxQOnuswBfoIZjNB8jEA?pwd=9yks 提取码: 9yks
Spark源码包 https://pan.baidu.com/s/1p_IRlhwT1eQxrIK3jVHbww?pwd=bhkx 提取码: bhkx
Zookeeper https://pan.baidu.com/s/1j6iy5bZkrY-GKGItenRB2w?pwd=irrx 提取码: irrx
mysql-connector-java-8.0.15.jar https://pan.baidu.com/s/1YHVMrG66lIHVHEH-jcUsVQ?pwd=4ipc 提取码: 4ipc
与hive兼容的spark版本可通过hive源码的pom.xml中查看
2、解压安装
Hadoop、Zookeeper 请查看
Mac M3 Pro安装Hadoop-3.3.6-CSDN博客
Mac M3 Pro 安装 Zookeeper-3.4.6-CSDN博客
mysql 可直接使用 brew install mysql 进行安装
# 将安装包移动到目标目录
mv ~/Download/apache-hive-3.1.3-bin.tar.gz /opt/module
mv ~/Download/spark-2.3.2-bin-without-hadoop.tgz /opt/module# 进入目标目录
cd /opt/module# 解压安装包
tar -zxvf apache-hive-3.1.3-bin.tar.gz
tar -zxvf spark-2.3.2-bin-without-hadoop.tgz# 修改目录名
mv apache-hive-3.1.3-bin hive
mv spark-2.3.2-bin-without-hadoop spark# 添加mysql-connector-java-8.0.15.jar到lib目录
mv ~/Download/mysql-connector-java-8.0.15.jar /opt/module/hive/lib# 添加环境变量sudo vim /etc/profileexport JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk8/Contents/Home"
export MYSQL_HOME="/opt/homebrew/Cellar/mysql@8.0/8.0.36_1"export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/opt/module/hadoop
export JAVA_LIBRARY_PATH="$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR="$HADOOP_HOME/lib/native"
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HIVE_HOME=/opt/module/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=$HIVE_HOME/lib
export HADOOP_USER_NAME=hdfs
export SPARK_HOME=/opt/module/spark
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH="$JAVA_HOME/bin:$MYSQL_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$SPARK_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH:."# 保存后使其生效
source /etc/profile3、修改配置
cd /opt/module/hive/conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
vim hive-env.sh
# 添加
export HADOOP_HEAPSIZE=4096vim hive-site.xml# 下面的内容与本地环境比较,存在的则修改,不存在的则添加<property><name>hive.execution.engine</name><value>spark</value></property>
<property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property><!--元数据是否校验--><property><name>hive.metastore.schema.verification</name><value>false</value></property><property><name>hive.server2.thrift.port</name><value>10000</value><description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description></property><property><name>spark.yarn.jars</name><value>hdfs:///spark/spark-jars/*.jar</value></property><property><name>hive.spark.client.connect.timeout</name><value>1000ms</value></property><property><name>hive.exec.scratchdir</name> <value>/tmp/hive</value></property><property><name>hive.querylog.location</name><value>${java.io.tmpdir}/${user.name}</value></property><property><name>hive.server2.thrift.port</name><value>10000</value></property><property><name>hive.server2.webui.host</name><value>0.0.0.0</value></property><property><name>hive.server2.webui.port</name><value>10002</value></property> <property><name>hive.server2.long.polling.timeout</name><value>5000ms</value></property><property><name>hive.server2.enable.doAs</name><value>false</value></property><property><name>spark.home</name><value>/opt/module/spark</value></property> <property><name>spark.master</name><value>spark://127.0.0.1:7077</value></property><property><name>spark.submit.deployMode</name><value>client</value></property> <property><name>spark.eventLog.enabled</name><value>true</value></property><property><name>spark.eventLog.dir</name><value>hdfs:///spark/log</value></property><property><name>spark.serializer</name><value>org.apache.spark.serializer.KryoSerializer</value></property><property><name>spark.executor.memeory</name><value>8g</value></property><property><name>spark.driver.memeory</name><value>8g</value></property><property><name>spark.executor.extraJavaOptions</name><value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value></property><property><name>hive.support.concurrency</name><value>true</value></property><property><name>hive.exec.dynamic.partition.mode</name><value>nonstrict</value></property>cd /opt/module/spark/conf
cp slaves.template slaves
vim slaves# 末尾添加
127.0.0.1cp spark-env.sh.template spark-env.shvim spark-env.sh# 末尾添加export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk8/Contents/Home
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop/export SPARK_MASTER_HOST=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_HOST=127.0.0.1
export SPARK_LOCAL_IP=127.0.0.1
export SPARK_EXECUTOR_MEMORY=8192mcp spark-defaults.conf.template spark-defaults.confvim spark-defaults.conf# 末尾添加spark.master spark://master:7077
spark.home /opt/module/spark
spark.eventLog.enabled true
spark.eventLog.dir hdfs:///spark/log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 4g
spark.driver.memory 4g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.yarn.archive hdfs:///spark/jars/spark2.3.2-without-hive-libs.jar
spark.yarn.jars hdfs:///spark/jars/spark2.3.2-without-hive-libs.jar# 拷贝hive-site.xml到spark的conf目录cp /opt/module/hive/conf/hive-site.xml /opt/module/spark/conf4、将spark的jars上传到hdfs
# hdfs上创建必要的目录
hdfs dfs -mkdir /tmp
hdfs dfs -mkdir /tmp/hive
hdfs dfs -mkdir /tmp/logs
hdfs dfs -mkdir /tmp/sparkhdfs dfs -mkdir /spark
hdfs dfs -mkdir /spark/jars
hdfs dfs -mkdir /spark/spark-jars
hdfs dfs -mkdir /spark/log# 安装目录创建目录
mkdir -p $SPARK_HOME/work $SPARK_HOME/logs $SPARK_HOME/run
mkdir -p $HIVE_HOME/logs# Spark 安装包默认会缺少 log4j slf4j 和 hadoop-comment之类的jar包,需要从hadoop、hive按照包目录中去复制到jars下去,如果没有就从开发时的maven仓库中去拷贝,或者到下载的spark-package-2.3.2.tgz中获取slf4j-api-1.7.21.jar
slf4j-log4j12-1.7.21.jar
log4j-1.2-api-2.17.1.jar
log4j-api-2.17.1.jar
log4j-core-2.17.1.jar
log4j-slf4j-impl-2.17.1.jar
log4j-web-2.17.1.jar
hadoop-common-3.3.6.jar
spark-network-common_2.11-2.3.2.jar# 进入spark安装包目录,将jars进行打包
cd /opt/module/sparkjar cv0f spark-2.3.2-without-hive-libs.jar -C ./jars .# 在hdfs上创建存放jar包目录
hdfs dfs -put spark2.3.2-without-hive-libs.jar /spark/jars/
hdfs dfs -put jars/* /spark/spark-jars
5、mysql中创建hive库
CREATE DATABASE hive;6、hive初始化数据库
cd /opt/module/hive/binschematool -initSchema -dbType mysql --verbose
7、启动Spark
# 先跑一下测试示例验证spark是否正常
cd /opt/module/spark/binspark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1G \
--num-executors 3 \
--executor-memory 1G \
--executor-cores 1 \
/opt/module/spark/examples/jars/spark-examples_*.jar 10# 如果出现下面的计算结果则表示成功
Pi is roughly 3.1391191391191393# 启动spark
cd ..
./bin/start-all.sh# 通过jps查看进程是否正常
jps -l# 查看是否有如下进程
org.apache.spark.deploy.master.Master
org.apache.spark.deploy.worker.Worker
org.apache.spark.executor.CoarseGrainedExecutorBackend# 如未启动成功请到日志目录中/opt/module/spark/logs 查看时间为最近的日志文件,根据报错进程排查
# 启动成功后可访问web ui界面,打开地址 http://127.0.0.1:8080/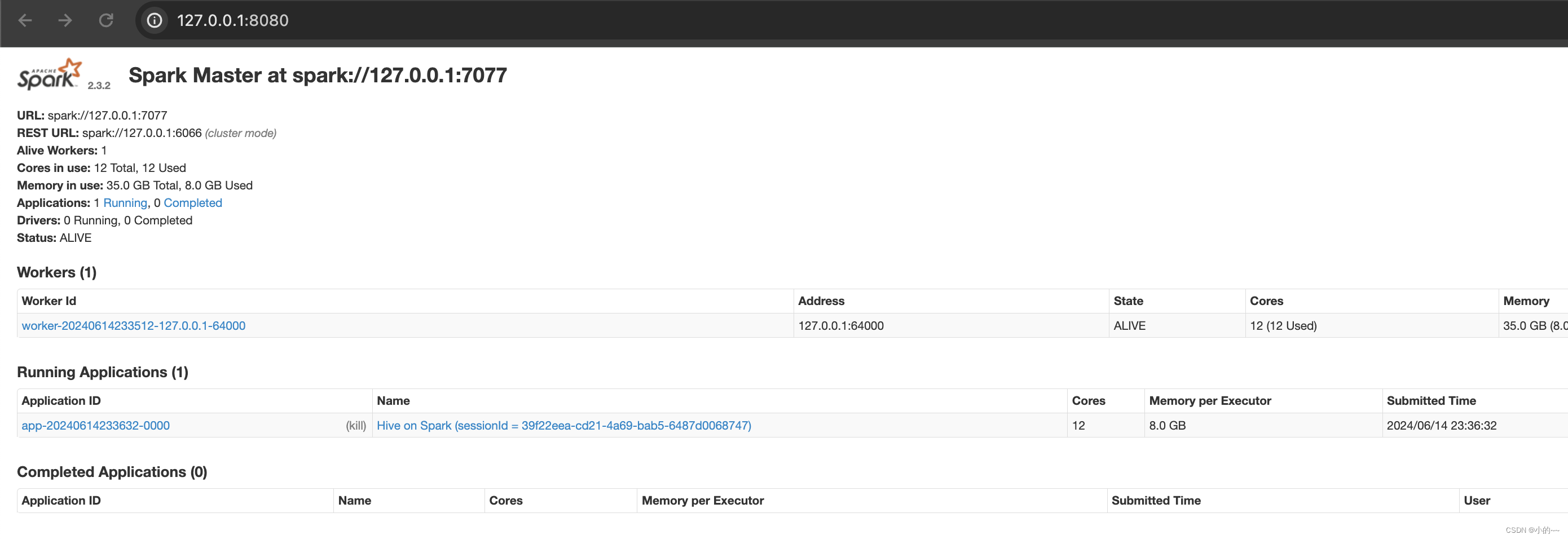
8、启动HIVE
cd /opt/module/hivenohup ./bin/hive --service metastore &
nohup ./bin/hive --service hiveserver2 &# 检查是否启动成功ps -ef | grep HiveMetaStoreps -ef | grep hiveserver2# 如果启动失败 可以tail -999f nohup.out文件# 如果成功则可以看下hive的webui界面,http://127.0.0.1:10002/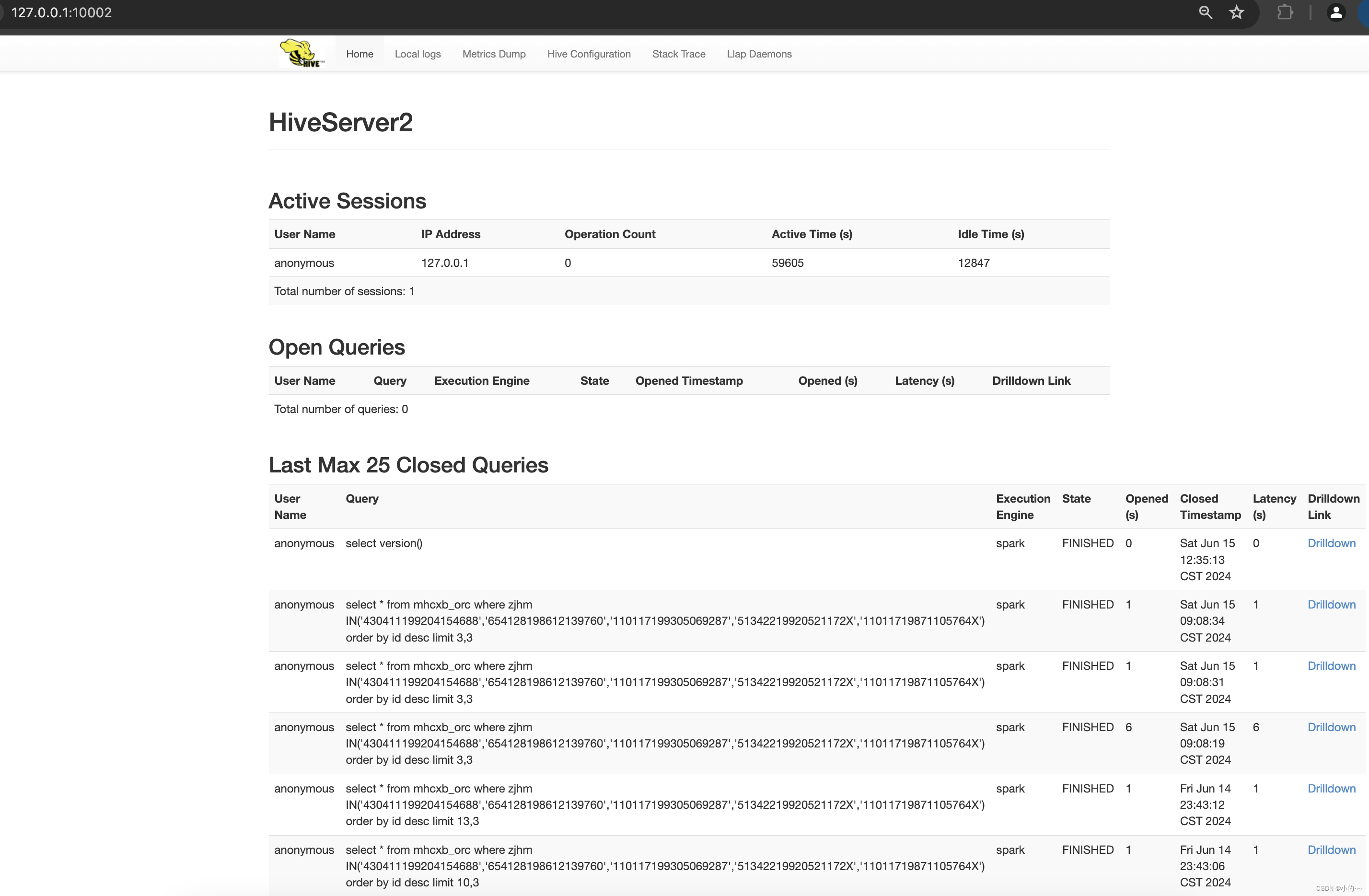
9、检查是否成功
# 使用beeline 进入hive
beeline -u 'jdbc:hive2://127.0.0.1:10000'select version();select current_user();set hive.execution.engine;# 创建表 t1CREATE TABLE `t1`(`id` bigint,`name` string,`address` string);# 向表t1中插入数据INSERT INTO t1 VALUES(1,'one','beijing'),(2,'two','shanghai'),(3,'three','guangzhou'),(4,'four','shenzhen'),(5,'five','huzhou'),(6,'six','jiaxing'),(7,'seven','ningbo'),(8,'eight','shaoxing'),(9,'nine','nanjing');
10、执行表操作后查看控制台
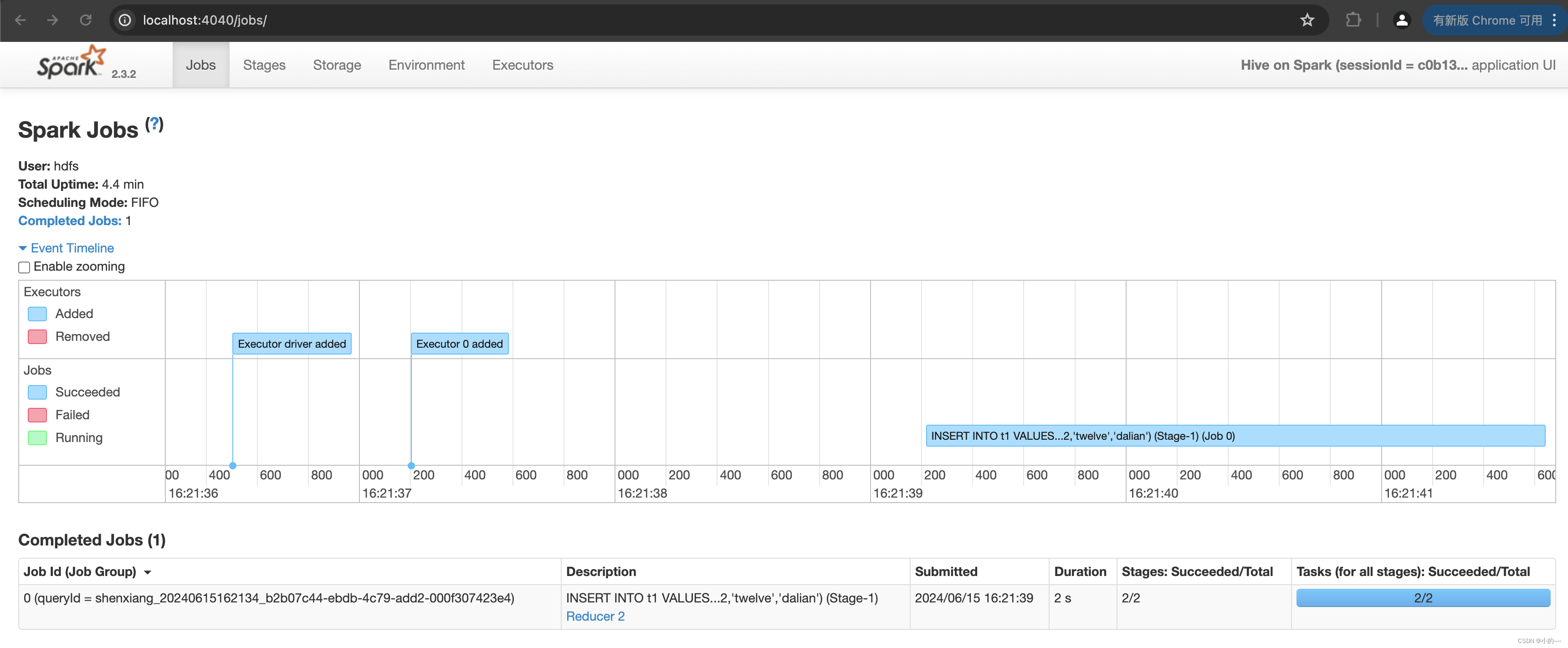
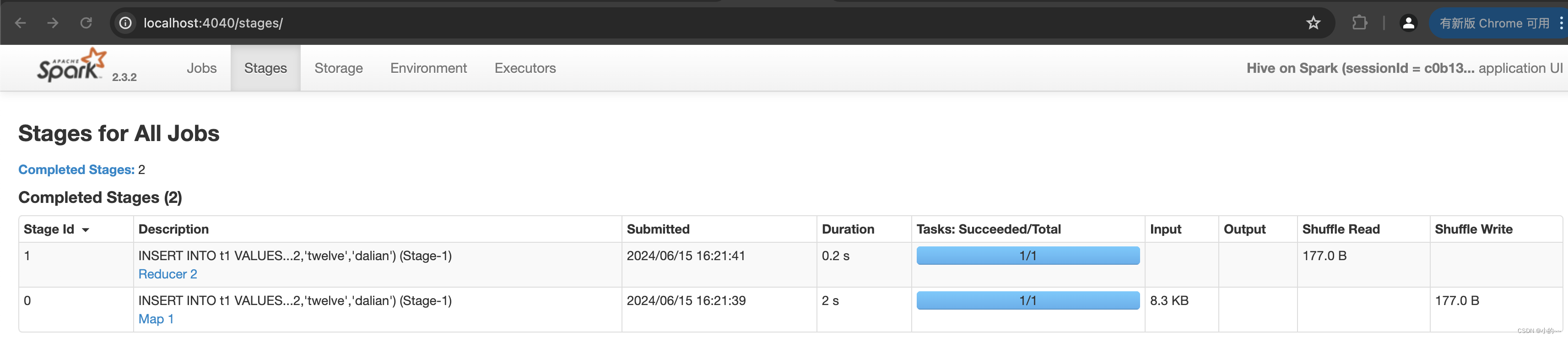
参考地址
https://blog.csdn.net/qq_35745940/article/details/122152096
https://www.cnblogs.com/lenmom/p/10356643.html
这篇关于Mac M3 Pro 部署Spark-2.3.2 On Hive-3.1.3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








