本文主要是介绍实时流Streaming大数据:Storm,Spark和Samza,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当前有许多分布式计算系统能够实时处理大数据,这篇文章是对Apache的三个框架进行比较,试图提供一个快速的高屋建瓴地异同性总结。
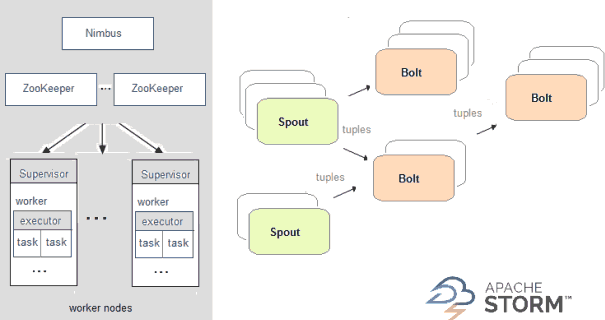
Apache Storm
在Storm中,你设计的实时计算图称为toplogy,将其以集群方式运行,其主节点会在工作节点之间分发代码并执行,在一个topology中,数据是在spout之间传递,它发射数据流作为不可变的key-value匹配集合,这种key-value配对值称为tuple,bolt是用来转换这些流如count计数或filter过滤等,bolt它们自己也可选择发射数据到其它流处理管道下游的bolt。
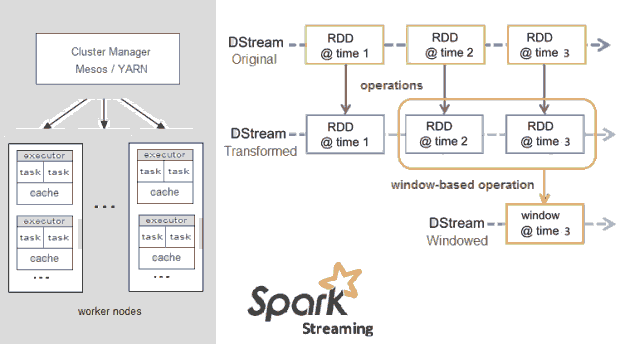
Apache Spark
Spark Streaming是核心Spark的一个拓展,并不是像Storm一次处理流,而是将它们分成片段,变成小批量时间间隔处理,Spark抽象一个持续的数据流称为DStream(离散流),一个DStream是RDD(弹性分布式数据集的简称)的微批次 micro-batch,RDD是分布式集合能够并行地被任何函数操作,也可以通过一个滑动窗口的数据(窗口计算)进行变换。
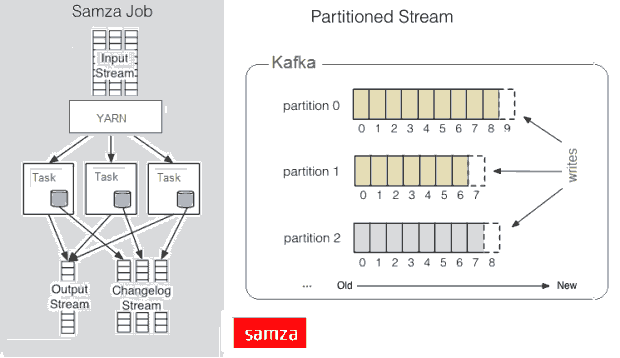
Apache Samza
Samza 的目标是将流作为接受到的消息处理,同时,Samza的流初始元素并不是一个tuple或一个DStream,而是一个消息,流被划分到分区,每个分区是一个只读消息的排序的序列,每个消息有一个唯一的ID(offset),系统也支持批处理,从同样的流分区以顺序消费几个消息,尽管Samza主要是依赖于Hadoop的Yarn和Apache Kafka,但是它的Execution & Streaming模块是可插拔的。
共同点
这三个实时计算系统都是开源的,低延迟的,分布式的,可扩展的和容错的,他们都允许你在有错误恢复的集群中通过并行任务执行流处理代码,他们也提供简单的API抽象底层和复杂的实现。
这三个框架使用不同的词汇表达相似的概念:
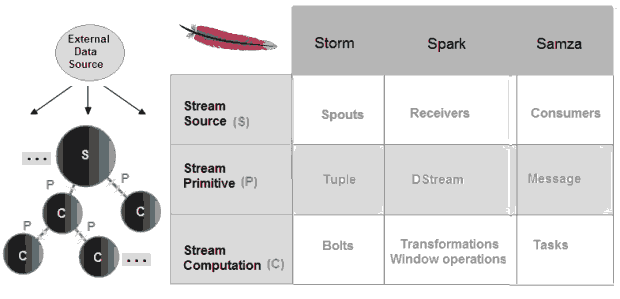
不同点
不同点总结如下表:

有三个delivery模式:
- At-most-once: 消息也许丢失,这通常是最不理想的结果。
- At-least-once: 消息可以被退回(没有损失,但是会重复),这足够支持很多用例场景了。
- Exactly-once: 每个消息只传递一次,也只有一次(不会丢失,无重复),这是一个理想功能,在所有情况下很难达到。
另外一个方面是状态管理,有许多不同的策略来存储状态,Spark Streaming写数据到分布式文件系统如HDFS,而Samza使用一个嵌入的key-value存储,Storm则或在应用层使用自己的状态管理,或使用一个高层次抽象称为:Trident.
使用场景
所有这三个框架都特别适合处理连续的大量的实时数据,那么选择哪一个呢?并没有硬性规则,基本是通用的指南。
如果你想要一个高速事件流处理系统,能够进行增量计算,那么Storm将非常适合,如果你还需要按需运行分布式计算,而客户端正在同步等待结果,那么你得在其外面使用分布式RPC(DRPC),最后但并非最不重要的是:因为Storm使用Apache Thrift,你能以任何语言编写拓扑topology,如果你需要状态持久或exactly-once传递,那么你应当看看高级别的Trident API,它也提供微批处理(micro-batching)
使用Storm的公司有 Twitter, Yahoo!, Spotify, The Weather Channel...
谈到微批处理,如果你必须有有态计算,exactly-once传递和不介意高延迟,你可以考虑Spark Streaming,特别如果计划实现图操作,机器学习或访问SQL,Apache Spark能让你通过结合Spark SQL, MLlib, GraphX几个库包实现,这些提供方便的统一的编程模型,特别是流算法如流k-means允许Spark实时进行决策。
使用Spark有:Amazon, Yahoo!, NASA JPL, eBay Inc., Baidu
如果你有大量的状态,比如每个分区有很多G字节,Samza协同存储和在同一机器处理的模型能让你有效处理状态,且不会塞满内存。这个框架提供灵活的可插拔API:它的默认execution 消息和存储引擎能够被你喜欢的选择替代,更有甚者,如果你有很多流处理过程,它们分别来自于不同的代码库不同的团队,Samza细粒度的工作特点将特别适合,因为它们能最小的影响来进行加入和移除。
这篇关于实时流Streaming大数据:Storm,Spark和Samza的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




