本文主要是介绍【将xml文件转yolov5训练数据txt标签文件】连classes.txt都可以生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
将xml文件转yolov5训练数据txt标签文件
- 前言
- 一、代码
- 解析
- 二、使用方法
- 总结
前言
找遍全网,我觉得写得最详细的就是这个博文⇨将xml文件转yolov5训练数据txt标签文件
虽然我还是没有跑成功。那个正则表达式我不会改QWQ,但是不妨碍我会训练ai。
最终成功了,现在就把训练成功的代码贴上来,顺便加点注释,英雄不问出处吧!
-------2024/6/9
一、代码
# 实现xml格式转yolov5格式import os
import xml.etree.ElementTree as ET# 定义一个函数用于从XML文件中提取类别信息
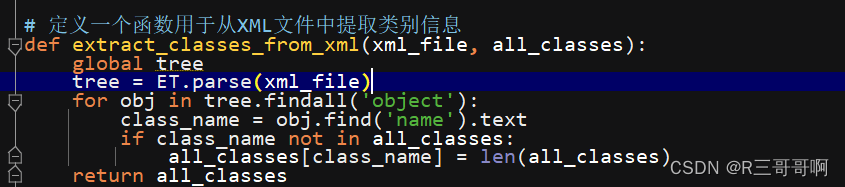
def extract_classes_from_xml(xml_file, all_classes):global treetree = ET.parse(xml_file)for obj in tree.findall('object'):class_name = obj.find('name').textif class_name not in all_classes:all_classes[class_name] = len(all_classes)return all_classesdef main():# 准备保存 classes 信息的文件classes_file_path = 'S:\\IMG\\PCB_DATASET_VOC\\VOCdevkit\\VOC2007\\labels\\classes.txt'# 遍历XML文件夹xml_folder = 'S:\\IMG\\PCB_DATASET_VOC\\VOCdevkit\\VOC2007\\Annotations'txt_folder = 'S:\\IMG\\PCB_DATASET_VOC\\VOCdevkit\\VOC2007\\labels'all_classes = {}# 准备保存类别信息的文件with open(classes_file_path, 'w') as classes_file:for xml_file in os.listdir(xml_folder):if not xml_file.endswith('.xml'):continueimage_id = os.path.splitext(xml_file)[0]# 从XML文件中提取类别信息all_classes = extract_classes_from_xml(os.path.join(xml_folder, xml_file), all_classes)with open(os.path.join(txt_folder, f'{image_id}.txt'), 'w') as txt_file:for obj in ET.parse(os.path.join(xml_folder, xml_file)).findall('object'):class_name = obj.find('name').textclass_id = all_classes[class_name]bbox = obj.find('bndbox')x_min = float(bbox.find('xmin').text)y_min = float(bbox.find('ymin').text)x_max = float(bbox.find('xmax').text)y_max = float(bbox.find('ymax').text)width = x_max - x_minheight = y_max - y_minx_center = x_min + width / 2y_center = y_min + height / 2img_width = float(tree.find('size').find('width').text)img_height = float(tree.find('size').find('height').text)x_center /= img_widthy_center /= img_heightwidth /= img_widthheight /= img_heightline = f"{class_id} {x_center} {y_center} {width} {height}\n"txt_file.write(line)print(f" {image_id}.xml to {image_id}.txt 转换完成")for class_name, class_id in all_classes.items():classes_file.write(f"{class_name}\n")print("转换完成,祝愿您顺利")if __name__ == "__main__":main()
解析
难点只有with open(classes_file_path, 'w') as classes_file这里的
从一个XML文件中读取标注信息,并将这些信息转换成用于训练图像识别模型的格式。
下面是对这段代码的逐行解释:
- 打开文件用于写入类别信息
with open(classes_file_path, 'w') as classes_file:
这里打开了classes_file_path指向的文件用于写入。classes_file会用来保存所有的类别名称。
- 这段代码遍历了xml_folder中的所有文件。os.listdir()返回一个包含指定目录中所有文件和目录名称的列表。
for xml_file in os.listdir(xml_folder):
- 这个条件检查确保只处理以.xml结尾的文件。如果不是XML文件,则跳过当前循环迭代。
if not xml_file.endswith('.xml'): continue
- 这里使用os.path.splitext()函数将文件名和扩展名分离,并获取文件名部分。image_id现在包含了没有扩展名的文件名。
image_id = os.path.splitext(xml_file)[0]
os.path.splitext()函数可以将文件路径分割成路径名和文件扩展名两部分,并以元组的形式返回。
这样做的原因是因为在很多操作系统中,文件名通常包含了文件的路径以及文件扩展名,如/path/to/file.xml。通过使用os.path.splitext(),我们可以方便地分离出文件名和扩展名部分,进而更方便地对它们进行处理。
例如,假设xml_file的值为"example.xml",那么os.path.splitext(xml_file)将返回(“example”, “.xml”),然后通过[0]索引取得文件名部分"example"。这样就实现了将文件名和扩展名分离的目的。
总的来说,os.path.splitext()函数在处理文件路径和文件名时非常实用,能够帮助我们轻松地获取文件名和扩展名,从而进行文件处理操作。
- 从XML文件中提取类别信息
all_classes = extract_classes_from_xml(os.path.join(xml_folder, xml_file), all_classes)
这里调用了extract_classes_from_xml()函数,一个从XML文件中提取所有类别名称的函数,并将这些类别名称保存到一个字典中,其中类别名称是键,而类别ID是值。
函数extract_classes_from_xml接收两个参数:xml_file和all_classes。
1、xml_file是XML文件的路径,
2、all_classes是一个字典,用于存储已知的所有类别名称和它们的ID。
在函数内部,首先使用ET.parse(xml_file)解析XML文件,并将其存储在全局变量tree中。然后,使用tree.findall(‘object’)遍历所有 < object >标签。对于每个< object >标签,提取其name标签中的文本,即类别名称。如果这个类别名称之前没有在all_classes字典中出现过,那么就将其添加到字典中,并设置其ID为当前类别ID。这里的类别ID是字典中类别名称的数量,即len(all_classes)。
最后,函数返回更新后的类别字典all_classes。这个字典包含了所有在XML文件中出现的类别名称及其对应的ID。
在主代码中,每次调用extract_classes_from_xml时,都会更新all_classes字典,因为它包含了所有之前遇到过的类别名称。这样,最终all_classes将包含所有的类别名称和它们的ID,这些信息将被用于创建训练数据文件和类别文件。
- 这段代码打开了一个文件用于写入,该文件位于txt_folder中,文件名是image_id加上.txt扩展名。
with open(os.path.join(txt_folder, f'{image_id}.txt'), 'w') as txt_file:
- 这段代码遍历了XML文档中的所有< object >标签。ET是ElementTree的缩写,.parse()函数解析XML文件
for obj in ET.parse(os.path.join(xml_folder, xml_file)).findall('object'):
- 这段代码从每个< object >标签中提取类别的名称,并通过all_classes字典将类别名称映射到一个类别ID。
class_name = obj.find('name').text
class_id = all_classes[class_name]
- 提取了边界框的四个坐标信息,即左上角和右下角的(x, y)值。
bbox = obj.find('bndbox')
x_min = float(bbox.find('xmin').text)
y_min = float(bbox.find('ymin').text)
x_max = float(bbox.find('xmax').text)
y_max = float(bbox.find('ymax').text)
- 计算了边界框的宽度、高度以及中心点的位置。
width = x_max - x_min
height = y_max - y_min
x_center = x_min + width / 2
y_center = y_min + height / 2
- 这里提取了图像的宽度和高度。
img_width = float(tree.find('size').find('width').text)
img_height = float(tree.find('size').find('height').text)
- 将边界框的坐标和尺寸进行归一化,即将它们除以图像的宽度和高度,使它们落在0到1之间。
x_center /= img_width
y_center /= img_height
width /= img_width
height /= img_height
- 生成了保存到文本文件的一行数据,其中包含了类别ID、归一化后的边界框中心坐标、宽度和高度。
line = f"{class_id} {x_center} {y_center} {width} {height}\n"
txt_file.write(line)
最后,将每个XML文件中的目标信息转换并写入一个对应的txt文件中,同时将类别信息写入classes_file中。整个过程将针对每个XML文件中的目标执行,最终完成目标检测训练数据的准备工作。
二、使用方法
网上下载的数据集有的是xml的,复制路径
创建一个目标位置的文件夹。
将地址填入合适的地方

运行就行了
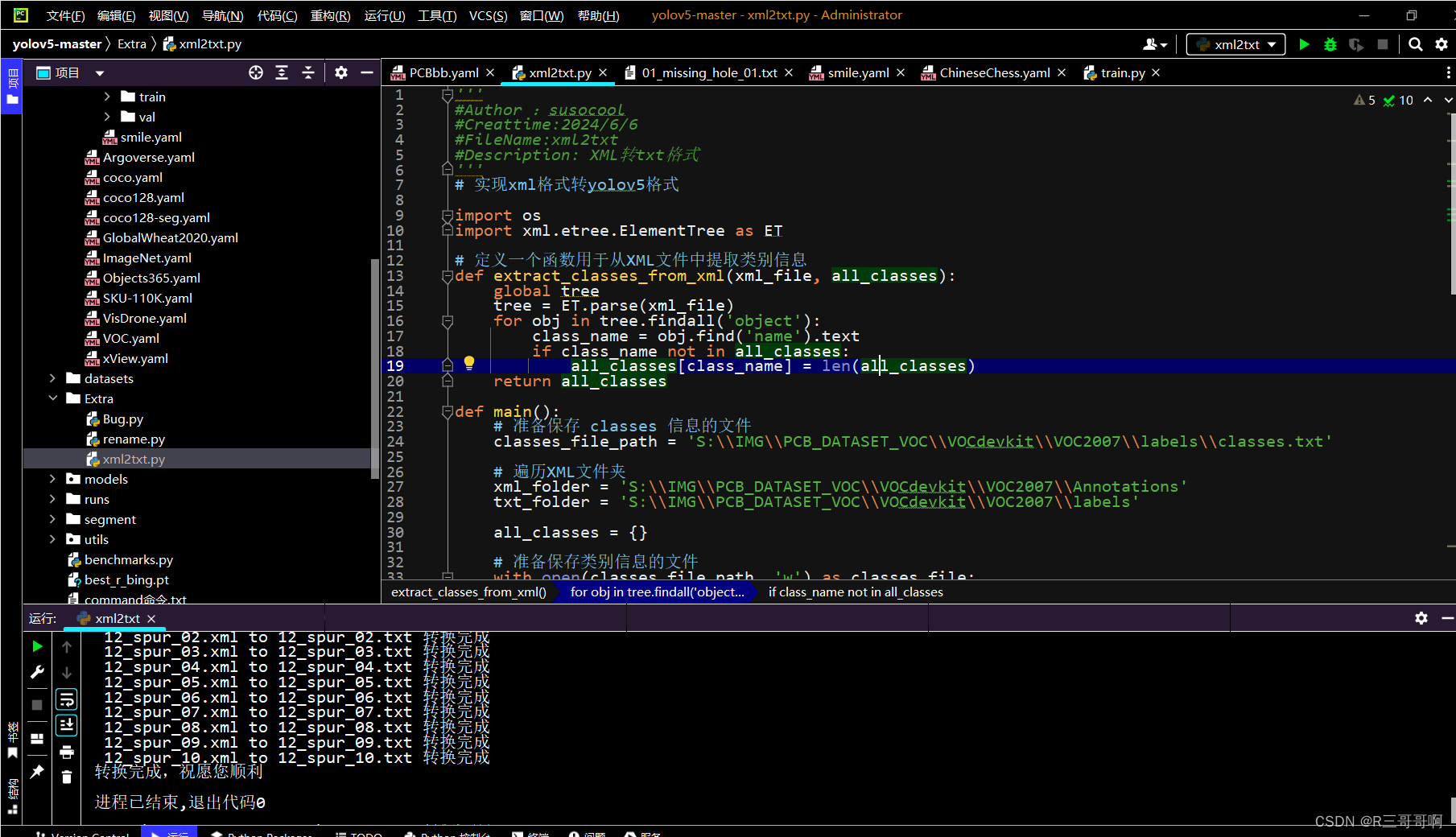
对应的文件也可以了
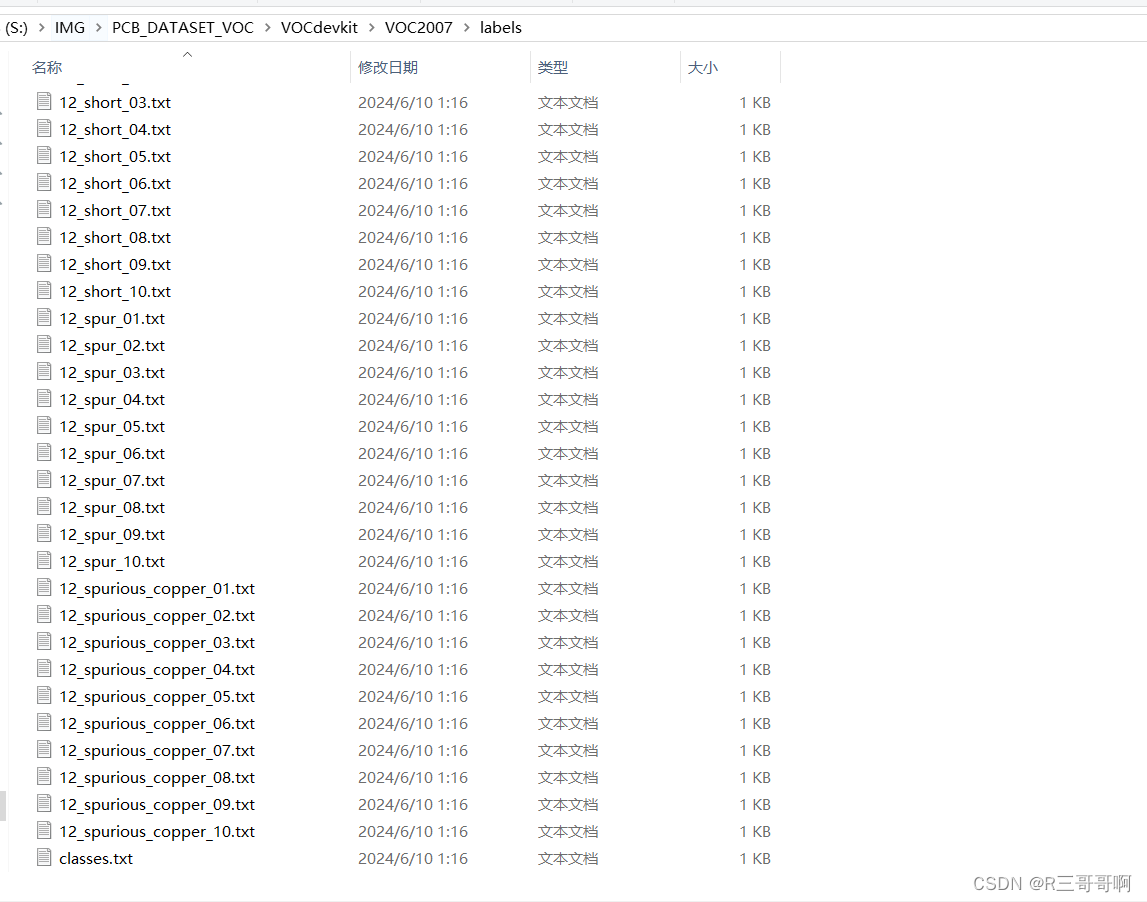
连classes都能识别出来!!!
总结
这篇文章依旧没有总结
这篇关于【将xml文件转yolov5训练数据txt标签文件】连classes.txt都可以生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




