本文主要是介绍hadoop入门3:MR实现Join逻辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果看详细的代码模板,请看我的hadoop入门1里有详细的模板,也有详细的解释
今天用两组数据进行join;其实数据很简单,
订单表:
id 日期 产品id 数量
1001 20180923 a001 2
1002 20180923 a002 1
1003 20180923 a001 3
1004 20180923 a003 1
1005 20180923 a003 2
产品表:
产品id 产品名称 分类id 价格
a001 华为手机 1000 2799
a002 惠普笔记本 1000 8799
a003 苹果平板 1000 5799
需求是:需要这两张表进行关联一张表;在SQL中很简单:select * from order o left join product t on o.pid = t.id;
用hadoop实现:具体请看代码:
1、创建关联表的映射类:
/*** Project Name:hadoopMapReduce* File Name:InfoBean.java* Package Name:com.zsy.mr.rjoin* Date:2018年9月23日下午5:17:59* Copyright (c) 2018, zhaoshouyun All Rights Reserved.*
*/package com.zsy.mr.rjoin;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class InfoBean implements WritableComparable<InfoBean> {private int orderId;private String dateString;private String pId;private int amount;private String pName;private int categoryId ;private float price;private String flag ;//0订单 1商品@Overridepublic void readFields(DataInput input) throws IOException {this.orderId = input.readInt();this.dateString = input.readUTF();this.pId = input.readUTF();this.amount = input.readInt();this.pName = input.readUTF();this.categoryId = input.readInt();this.price = input.readFloat();this.flag = input.readUTF(); }/*** private int orderId;private String dateString;private int pId;private int amount;private String pName;private int categoryId ;private float price;*/@Overridepublic void write(DataOutput output) throws IOException {output.writeInt(orderId);output.writeUTF(dateString);output.writeUTF(pId);output.writeInt(amount);output.writeUTF(pName);output.writeInt(categoryId);output.writeFloat(price);output.writeUTF(flag);}@Overridepublic int compareTo(InfoBean o) {return this.price > o.price ? -1 : 1;}public int getOrderId() {return orderId;}public void setOrderId(int orderId) {this.orderId = orderId;}public String getDateString() {return dateString;}public void setDateString(String dateString) {this.dateString = dateString;}public int getAmount() {return amount;}public void setAmount(int amount) {this.amount = amount;}public String getpId() {return pId;}public void setpId(String pId) {this.pId = pId;}public String getpName() {return pName;}public void setpName(String pName) {this.pName = pName;}public int getCategoryId() {return categoryId;}public void setCategoryId(int categoryId) {this.categoryId = categoryId;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}public float getPrice() {return price;}public void setPrice(float price) {this.price = price;}/*** Creates a new instance of InfoBean.** @param orderId* @param dateString* @param pId* @param amount* @param pName* @param categoryId* @param price*/public void set(int orderId, String dateString, String pId, int amount, String pName, int categoryId, float price, String flag) {this.orderId = orderId;this.dateString = dateString;this.pId = pId;this.amount = amount;this.pName = pName;this.categoryId = categoryId;this.price = price;this.flag = flag;}/*** Creates a new instance of InfoBean.**/public InfoBean() {}@Overridepublic String toString() {return orderId + "\t" + dateString + "\t" + amount + "\t" + pId+ "\t" + pName + "\t" + categoryId + "\t" + price+"\t"+flag;}}2、编写具体的业务
/*** Project Name:hadoopMapReduce* File Name:Rjoin.java* Package Name:com.zsy.mr.rjoin* Date:2018年9月23日下午5:16:11* Copyright (c) 2018, zhaoshouyun All Rights Reserved.*
*/
/*** Project Name:hadoopMapReduce* File Name:Rjoin.java* Package Name:com.zsy.mr.rjoin* Date:2018年9月23日下午5:16:11* Copyright (c) 2018, zhaoshouyun All Rights Reserved.**/package com.zsy.mr.rjoin;import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
import java.util.List;import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** ClassName: Rjoin * Function: TODO ADD FUNCTION. * date: 2018年9月23日 下午5:16:11 * @author zhaoshouyun* @version * @since 1.0*/
public class RJoin {static class RJoinMapper extends Mapper<LongWritable, Text, Text, InfoBean>{InfoBean bean = new InfoBean();Text text = new Text();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, InfoBean>.Context context)throws IOException, InterruptedException {//由于读取文件后,获取的内容不好区分,是订单文件还是产品文件,我们可以通过分区来获取文件名来去人,我的订单文件名是包含order的FileSplit split = (FileSplit) context.getInputSplit();//获取文件名称String fileName = split.getPath().getName();//通过空格分割String[] strs = value.toString().split(" ");String flag = "";//标记String pId = "";//产品idif(fileName.contains("order")){//处理订单信息//订单idint orderId = Integer.parseInt(strs[0]);String dateString = strs[1];//产品id pId = strs[2];int amount = Integer.parseInt(strs[3]);flag = "0";bean.set(orderId, dateString, pId, amount, "", 0, 0, flag);}else{//处理产品信息pId = strs[0];String pName = strs[1];int categoryId = Integer.parseInt(strs[2]);float price = Float.parseFloat(strs[3]);flag = "1";bean.set(0, "", pId, 0, pName, categoryId, price, flag);}text.set(pId);context.write(text, bean);}}static class RJoinReducer extends Reducer<Text, InfoBean, InfoBean, NullWritable>{@Overrideprotected void reduce(Text key, Iterable<InfoBean> infoBeans,Reducer<Text, InfoBean, InfoBean, NullWritable>.Context context) throws IOException, InterruptedException {InfoBean pBean = new InfoBean();List<InfoBean> list = new ArrayList<>();for (InfoBean infoBean : infoBeans) {if("1".equals(infoBean.getFlag())){//flag 0是订单信息 1是产品信息try {BeanUtils.copyProperties(pBean, infoBean);//数据必须进行拷贝,不可直接赋值} catch (IllegalAccessException | InvocationTargetException e) {e.printStackTrace();}}else{//处理订单信息InfoBean orderBean = new InfoBean();try {BeanUtils.copyProperties(orderBean, infoBean);} catch (IllegalAccessException | InvocationTargetException e) {e.printStackTrace();}//由于订单和产品的关系是多对一的关系,所有订单要用list临时存放起来list.add(orderBean);}} for (InfoBean orderBean : list) {orderBean.setCategoryId(pBean.getCategoryId());orderBean.setpName(pBean.getpName());orderBean.setPrice(pBean.getPrice());//写出context.write(orderBean, NullWritable.get());}}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();/*conf.set("mapreduce.framework.name", "yarn");conf.set("yarn.resoucemanger.hostname", "hadoop01");*/Job job = Job.getInstance(conf);job.setJarByClass(RJoin.class);//指定本业务job要使用的业务类job.setMapperClass(RJoinMapper.class);job.setReducerClass(RJoinReducer.class);//指定mapper输出的k v类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(InfoBean.class);//指定最终输出kv类型(reduce输出类型)job.setOutputKeyClass(InfoBean.class);job.setOutputValueClass(NullWritable.class);//指定job的输入文件所在目录FileInputFormat.setInputPaths(job, new Path(args[0]));//指定job的输出结果目录FileOutputFormat.setOutputPath(job, new Path(args[1]));//将job中配置的相关参数,以及job所有的java类所在 的jar包,提交给yarn去运行//job.submit();无结果返回,建议不使用它boolean res = job.waitForCompletion(true);System.exit(res?0:1);}}输入文件:
输出结果:
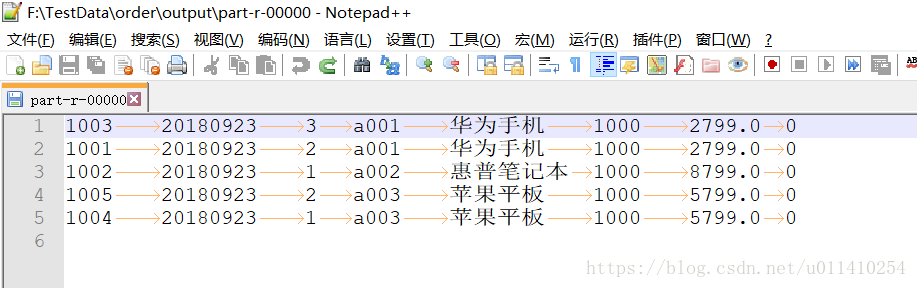
本次运行时在本地的eclipse运行的,本地运行正常,放到集群里也就没什么问题了
这篇关于hadoop入门3:MR实现Join逻辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





