本文主要是介绍【数据库】7种图数据库简单比较,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、 图数据库排名
- 2、 图数据库比较表格
- 3 、各种图数据库属性
- 3.1 Neo4j(主流)
- 3.2 OrientDB(不推荐)
- 3.3 ArangoDB(不推荐)
- 3.4 JanusGraph(推荐)
- 3.5 HugeGraph(推荐)
- 3.6 Dgraph(推荐)
- 3.7 TigerGraph(不推荐)
- 4 、选型结论
1、 图数据库排名
图数据库排名:https://db-engines.com/en/ranking/graph+dbms

2、 图数据库比较表格
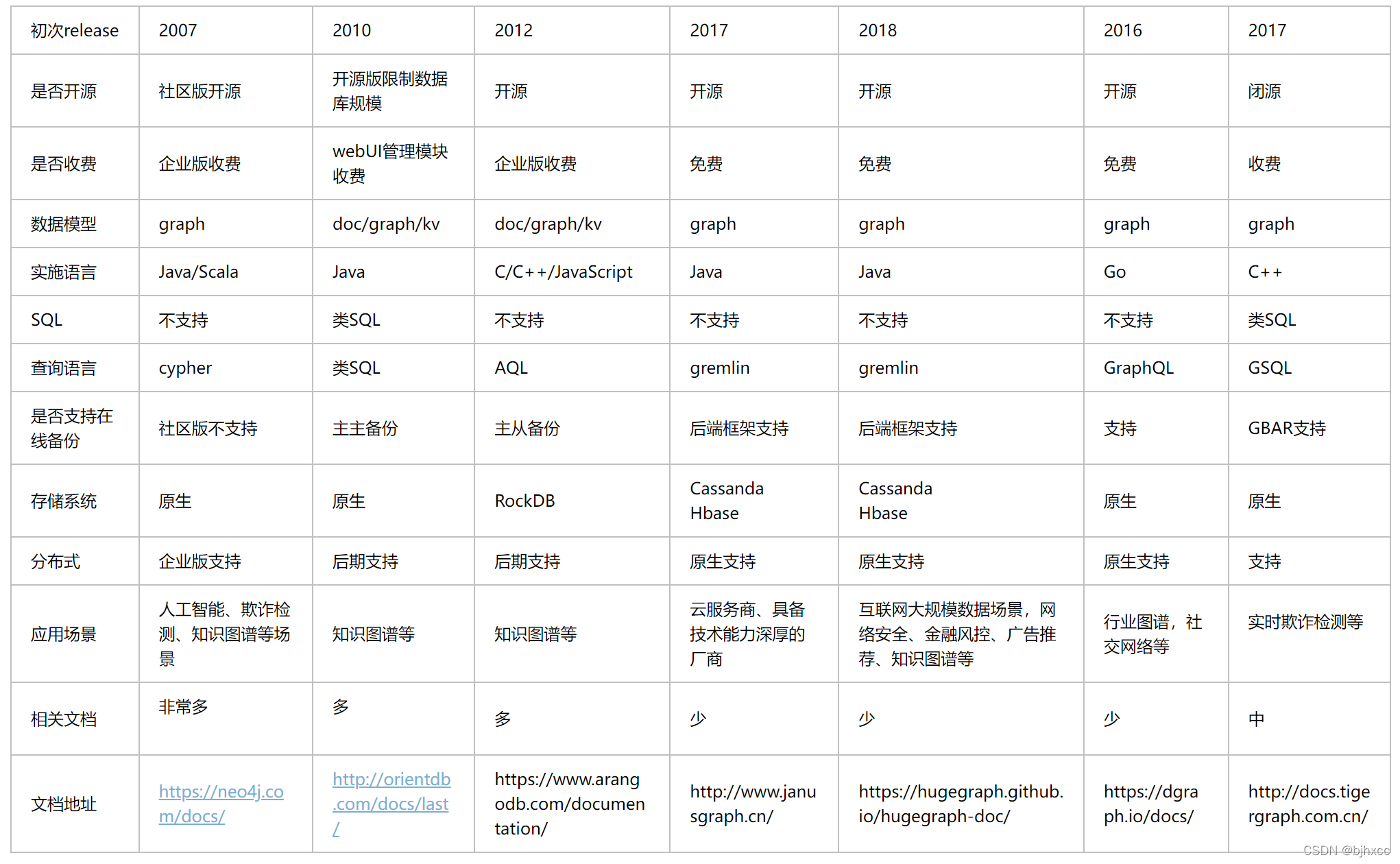
3 、各种图数据库属性
3.1 Neo4j(主流)
历史悠久且长期处于图数据库领域的主力地位,其功能强大,性能也不错,单节点的服务器可承载上亿级的节点和关系。社区版最多支持 320 亿个节点、320 亿个关系和 640 亿个属性。
优点:Neo4j有自己的后端存储,不必如同JanusGraph等一样还要依赖另外的数据库存储。 Neo4j在每个节点中存储了每个边的指针,因而遍历时效率相当高。
缺点:企业版付费。开源的社区版本只支持单机,不支持分布式。社区版只能部署成单实例,企业版可以部署成高可用集群,从而可以解决高并发量的问题;不能做集群,单个实例故障时影响系统正常运行。社区版只支持冷备份,即需要停止服务后才能进行备份。
3.2 OrientDB(不推荐)
OrientDB是第二代分布式图数据库,以混合数据模型为特点,它包括可以在最复杂的场景中使用复制和分片,并以Apache2许可证提供开放源代码。ORIENTDB工作速度快,能够在最常见的硬件上每秒存储220000条记录,并且支持无模式、完整和混合模式,可以使用SQL作为查询语言之一。
优点:ORIENTDB使用身份验证、密码和静态数据加密等方式为所有机密数据提供安全保护。OrientDB为确保更好的性能,最近引入了节点的快速重新同步,即使处理数十亿条记录,遍历速度也不会受到影响。OrientDB 是分布式多模型数据库,支持图数据模型,支持 sharding 机制,大规模查询情况下性能比较好;
缺点:开源版功能部分欠缺。起步较早,最初的时候都是一个单机的图数据库,然后随着用户数据量的不断增加,后期增加了分布式模式,支持集群和副本,但是由于后加的功能,其分布式支持的不是很好。
3.3 ArangoDB(不推荐)
Arangodb以一种非常创造性和灵活的方式安排数据。数据可以存储为键或值对、图或文档,所有这些都可以通过一种查询语言访问。为了更安全的选择,查询中可以使用声明性模型。用户可以在一个查询中组合不同的模型及其特性的原因是,ArangoDB对所有数据模型都使用相同的核心和相同的查询语言。
优点:Arangodb独特的特性是它能够在一个查询中组合不同的数据模型。这使得其展示方式令人印象深刻且美观。它比其他数据库具有更灵活的扩展性、增强的容错性、大容量的存储能力和更低的成本。arangodb最突出的特性是foxx,这是一个用于编写数据库中以数据为中心的javascript框架。
缺点:它们起步比较早,最初的时候都是一个单机的图数据库,然后随着用户数据量的不断增加,后期增加了分布式模式,支持集群和副本,但是经过调研发现,可能是由于后加的功能,他们的分布式支持的不是很好。
3.4 JanusGraph(推荐)
JanusGraph是可扩展的图数据库,底层依赖于大数据组件,对分布式支持的非常好,也都是完全的开源免费,存储数据模型也都是专为图数据而设计。JanusGraph基于Titan发展而来,包含其所有功能,采用Tikerpop的Gremlin图查询语言,有单独的后端存储,支持Cassandra/HBase/BerkeleyDB等做存储,支持Solr/ES/Lucence等做图索引 支持Spark GraphX/Giraph等图分析计算引擎及Hadoop分布式计算框架 原生支持集成了Tinkerpop系列组件:Gremlin查询语言,Gremlin-Server及Gremlin applications。 采用很友好的Apache2.0协议,支持对接可视化组件如Cytoscape,Gephi plugin for Apache TinkerPop,Graphexp,KeyLines by Cambridge Intelligence,Linkurious
优点:JanusGraph的存储系统依赖于像Cassandra、HBase(HBase又依赖于Zookeeper和HDFS)、BerkelyDB等等这样的存储系统,索引系统依赖于Elasticsearch、Solr、Lucene等等;也基于这些原因,它和大数据生态结合的非常好,可以很好地和Spark结合做一些大型的图计算。所以可以很好的和spark的大数据平台进行结合,并且能够支持实时图遍历和分析查询
缺点:其存储需要依赖于其他存储系统,JanusGraph使用HBase作为底层存储系统,而HBase又依赖于Zookeeper和HDFS,另外JanusGraph的索引又依赖于ES,所以想要搭建一套完整的JanusGraph,需要同时搭建维护好几套系统,维护成本非常大。另一问题就是稳定性,根据经验来看,系统越复杂,依赖系统越多,整体可控性就越差,稳定性风险就越大。并且三方的一些工具也存在一些问题,所以要用肯定要基于底层(读写)进行性能优化。
3.5 HugeGraph(推荐)
百度基于JanusGraph开源了HugeGraph,增加了很多特性,提高了易用性及性能,增加了一些图分析算法。实现了Apache ThinkerPop 3框架,支持Gremlin图查询语言。HugeGraph支持多用户并行操作,输入Gremlin查询语句,并及时得到图查询结果。也可以再用户程序中调用hugeGraph API进行图分析或查询。
优点:HugeGraph可以与Spark GraphX进行链接,借助Spark GraphX图分析算法(如PageRank、Connected Components、Triangle Count等)对HugeGraph的数据进行分析挖掘。HugeGraph还针对图数据库的高频应用(例如:ShortestPath、k-out、k-neighbor等)做了特定性能优化,并且为用户提供更为高效的使用体验
缺点:基于JanusGraph开源,存在和JanusGraph同样的问题,维护成本高。
3.6 Dgraph(推荐)
dgraph 是基于 golang 开发的开源的分布式图数据库。诞生时间不长, 发展却很迅速,从设计之初就考虑了分布式和扩展性,所以对分布式支持的非常好。
优点:Dgraph 不依赖与任何第三方系统,只有一个 Dgraph 可执行文件,只需在启动时通过参数指定是 Zero(管理节点)还是 Alpha(数据节点)即可,Dgraph 会自动组成集群,运维部署非常简单。Dgraph维护成本低很多。Dgraph 和 JanusGraph 性能差不多,但复杂查询下,Dgraph 性能远高于 JanusGraph。同时,Dgraph 的写入性能也整体高于 janusGraph。
缺点:比如还不支持多重边、一个集群只支持一个图、与大数据生态兼容不足等,这些都需要靠后期不断完善。
3.7 TigerGraph(不推荐)
TigerGraph是一个目前业界先进的企业级图数据库。系统完全闭源。部分查询算法开源。分为开发版和企业版。开发版免费,但功能受限,比如单点只能构建一个图。企业面收费,支持大规模集群,顶点表数量不受限制。
优点:TigerGraph可以通过GSQL实现类存储过程的算法封装,而且已经实现了很多图算法,但是语法结构要比Neo4j复杂的多。
缺点:付费图数据库。Neo4j按照cpu收费,TigerGraph按照数据容量(G)来收费,费用较贵。
4 、选型结论
推荐一:Neo4j。使用起来相当的方便,入门门槛很低,基本上拿来就能用,并且有很好的社区支持,三方库、第三方工具的支持,社区版本也可以支撑到不错的数据量(亿级没问题)。但是如果想挖掘海量数据,需要考虑的是海量数据的存储及计算,分布式存储是首选。开源版Neo4j并不支持分布式。
推荐二:Dgraph。Dgraph 除了运维成本低之外,整体读写性能也优于JanusGraph。缺点是文档社区支持较差。
推荐三:JanusGraph或HugeGraph。JanusGraph社区支持更全,复杂计算性能优于HugeGraph。
这篇关于【数据库】7种图数据库简单比较的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




