本文主要是介绍首个文字生成手语模型来了!SignLLM通过文字描述来生成手语视频,目前已经支持八国手语!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SignLLM 是目前第一个通过文字描述生成手语视频的多语言手语模型。
该项目引入了首个多语言手语数据集 Prompt2Sign,它使用工具自动采集和处理网络上的手语视频,能够不断更新,且具有轻量化特点。
该模型当前支持 8 种手语类型。包括美国手语 、德国手语、瑞士德语手语、瑞士法语手语 、瑞士意大利语手语 、阿根廷手语 、韩国手语和土耳其手语。
PS:目前未提供代码(后续提供),也期待更新中文手语~


相关链接
论文:https://arxiv.org/pdf/2405.10718
项目:https://github.com/SignLLM/Prompt2Sign
论文阅读

摘要
在本文中,我们介绍了第一个综合性的多语言手语数据集Prompt2Sign,它建立于包括美国手语(ASL)和其他七种语言在内的公共数据。我们的数据集将大量视频转换成精简的,模型友好的格式,优化与翻译模型的训练比如seq2seq和text2text。
在这个新数据集的基础上,我们提出 SignLLM是第一个多语言手语制作(SLP)模型, 它包括两种新颖的多语言SLP模式,允许从输入文本或提示生成手语手势。两者都是 模式可以使用新的损失和基于强化学习的模块, 通过增强模型自主抽取高质量数据的能力,加快了训练速度。
我们给出的基准结果SignLLM,这表明我们的模型在跨八种手语的SLP任务中的表现达到了最先进的水平。
方法
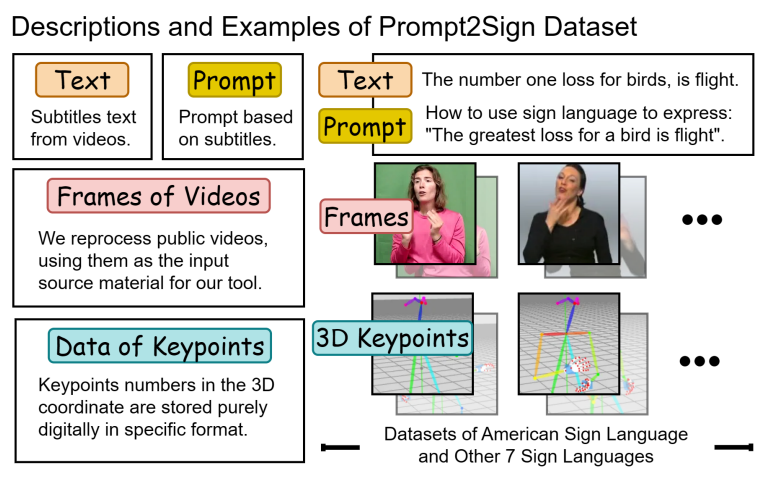
上图表示Prompt2Sign数据集主要组成部分,Prompt2Sign数据集是重新处理过的姿势数据, 哪些数据更有用,更适合训练。再处理的输入 工具是来自数据集或互联网的公共视频。
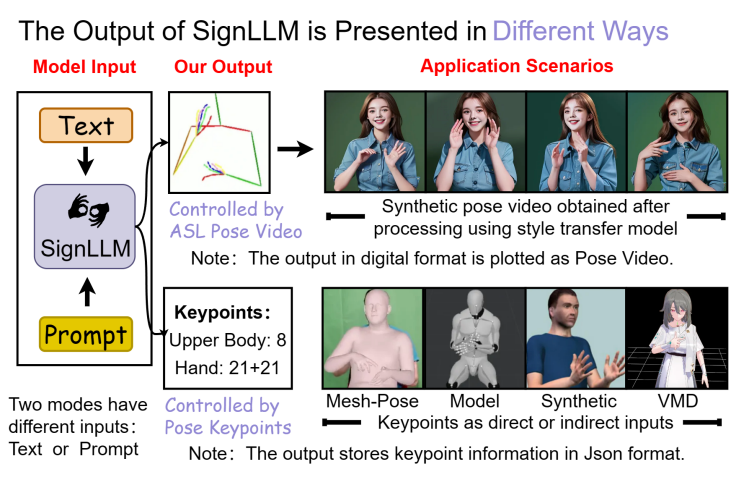
上图展示SignLLM旨在生成各种应用场景的手语姿势。
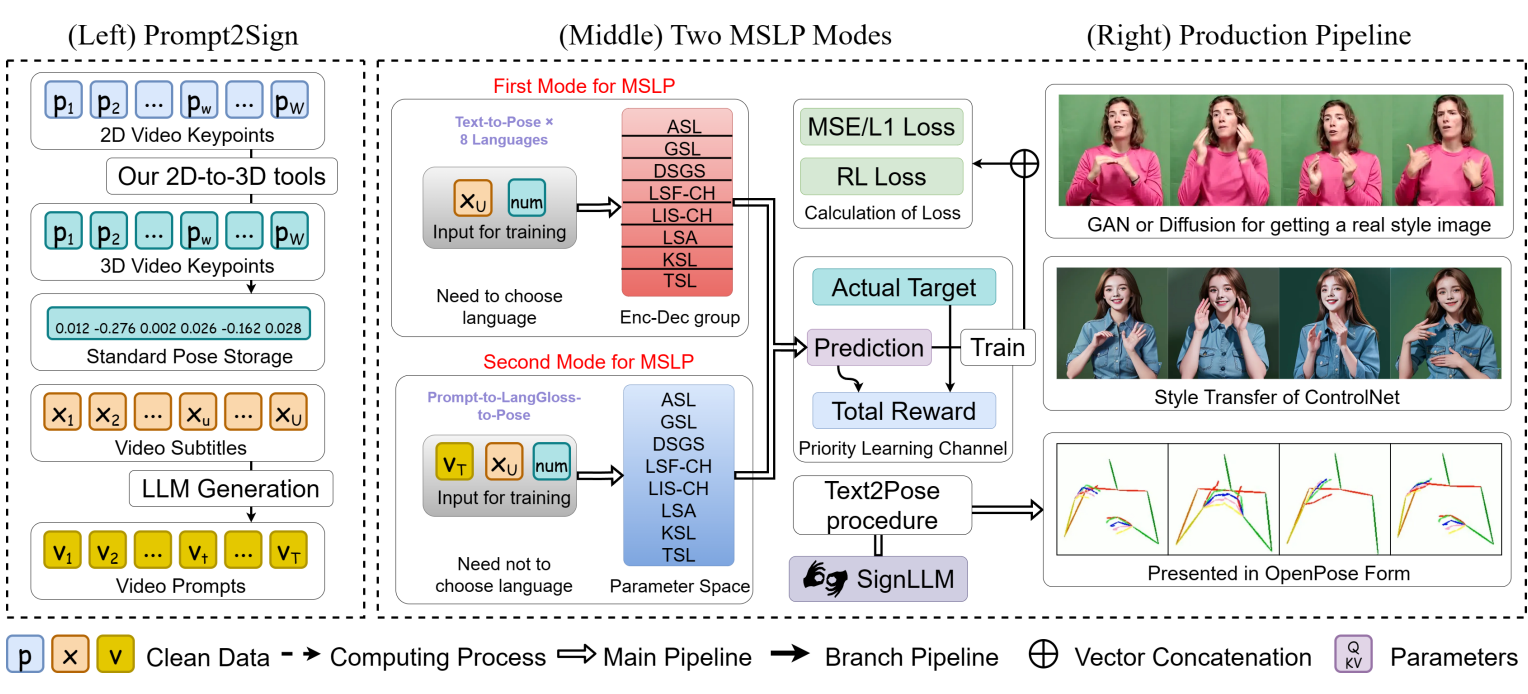
(左)Prompt2Sign数据集的数据类型和抽象表示。(中)Prompt2LangGloss和MLSF的训练过程,计算原理强化学习损失。(右)SignLLM的输出可以进行转换进入大多数姿势表示格式,然后可以渲染成现实的人类外观风格转移/特别微调生成模型。
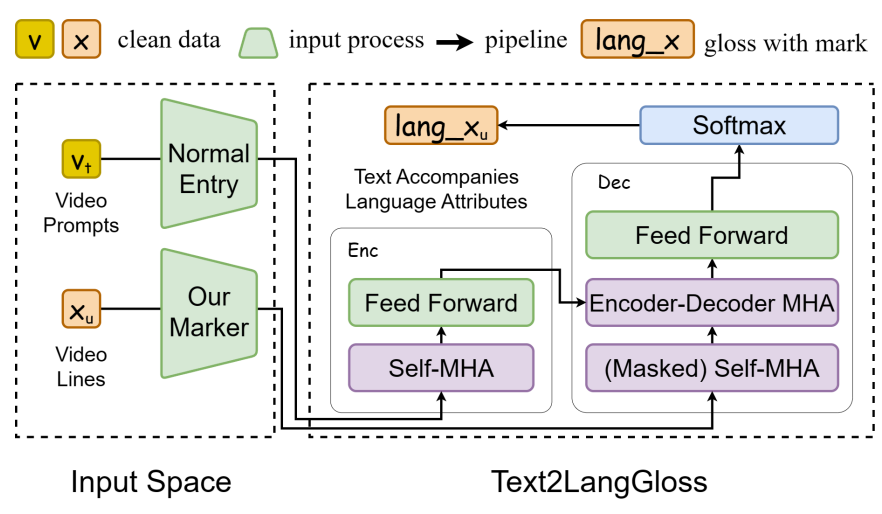
我们用a增强Text2Gloss标记生成具有语言学意义的Gloss属性。vt()和xu()表示数据类型和抽象表示。
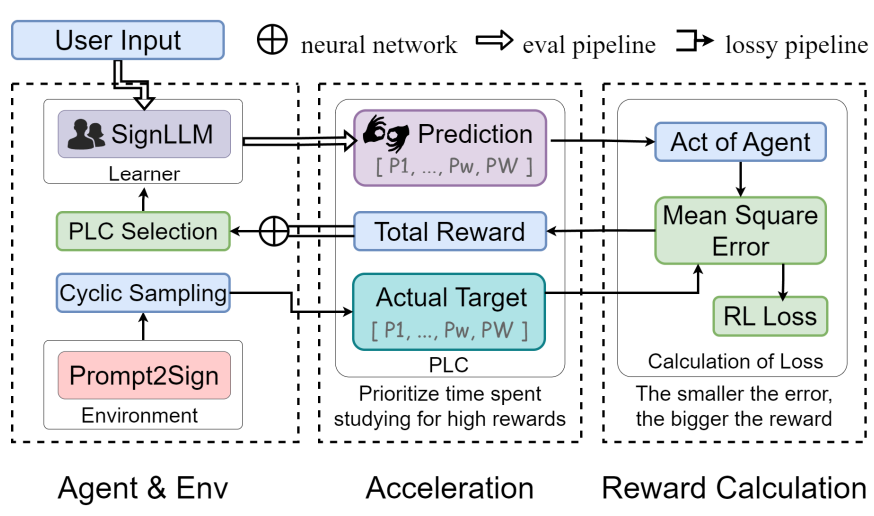
我们使用一些元素:User, Agent,环境,迭代更新过程,PLC的强化学习草图适用于序列预测的过程。
实验

(左)文本或提示作为模型输入。(右)我们用的是调整过的样式迁移模型,将预测的姿态视频转换为最终视频。


结论
我们提出了第一个多语言SLP模型SignLLM,该模型基于我们提出的标准化多语言手语数据集Prompt2Sign。我们的模型有两种模式,MLSF和Prompt2LangGloss,逐步融合了多样化的更多的手语,减轻了共享参数造成的问题。我们的新损耗和新模块解决了训练时间长的问题由于更大的数据集和更多的语言。
这篇关于首个文字生成手语模型来了!SignLLM通过文字描述来生成手语视频,目前已经支持八国手语!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



