本文主要是介绍Mysql+sphinx+中文分词简介(ubuntu),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、编译先前条件
确认是否已经安装以下软件,有些也许不是必须的,但建议还是都装上。
apt-get install autoconf automake autotools-dev cpp curl gawk gcc lftp libc6-dev linux-libc-dev make libpcre3-dev libpcrecpp0 g++ libtool libncurses5-dev
aptitude install libmysql++-dev libmysqlclient15-dev checkinstall
apt-get install python python-dev
二、安装所需文件
所需文件列表
mmseg-0.7.3.tar.gz 中文分词
mysql-5.1.26-rc.tar.gz mysql-5.1.26源代码
sphinx-0.9.8-rc2.tar.gz sphinx-0.9.8-rc2源代码
fix-crash-in-excerpts.patch sphinx支持分词补丁
sphinx-0.98rc2.zhcn-support.patch sphinx支持分词补丁
文件可以到官方下载,附件中我将会提供该系列文件。
三、开始安装
先将以上文件传到 root目录下
1、 mmseg-0.7.3 安装
先解压安装文件 tar -zxvf mmseg-0.7.3.tar.gz
cd mmseg-0.7.3/
./configure
make
make install
cd ../
到此mmseg安装完毕
可以尝试 输入mmseg 命令,看是否已经安装成功
2、 安装MySQL 5.1.26-rc、Sphinx、SphinxSE存储引擎
先解压 mysql和sphinx源文件
tar zxvf mysql-5.1.26-rc.tar.gz
tar zxvf sphinx-0.9.8-rc2.tar.gz
然后给sphinx打上补丁,这个是支持中文必须打的补丁
cd sphinx-0.9.8-rc2/
(请确认已经安装了patch,如果没有者 使用 apt-get install patch 安装)
patch -p1 < ../sphinx-0.98rc2.zhcn-support.patch
patch -p1 < ../fix-crash-in-excerpts.patch
接着将sphinx下的mysqlse 文件夹下的数据拷贝到mysql-5.1.26-rc/storage/sphinx 下面(这样才能在编译mysql的时候把SphinxSE存储引擎编译进去)
cp -rf mysqlse ../mysql-5.1.26-rc/storage/sphinx
到/mysql-5.1.26-rc/storage/sphinx目录下确认文件是否已经拷贝成功
cd ../
下面我们来编译安装mysql-5.1.26-rc
cd mysql-5.1.26-rc/
sh BUILD/autorun.sh 这步是必须的,请勿遗漏
使用configure命令确认安装
./configure --prefix=/usr/local/mysql --with-charset=utf8 --with-extra-charsets=all --with-plugins=sphinx
确认是否提示可使用make编译,如果是。
执行
make
这步执行时间比较长,一般在10-20分钟,主要看个人电脑配置
编译成功后.再执行安装命令(如果出现error,需要重新编译,一般80%的error都是编译环境没有装好(个人编译体会))
make install //这个过程大概需要1分钟不到的时间
这样mysql就已经安装完毕了
下面我们来配置和启动mysql
添加mysql用户组和用户
groupadd mysql
useradd -g mysql mysql
给mysql所在目录添加mysql用户权限
chown mysql:mysql /usr/local/mysql -R
将my-medium.cnf 拷贝到安装根目录
cp /usr/local/mysql/share/mysql/my-medium.cnf /usr/local/mysql/my.cnf
给my.cnf文件添加mysql用户权限
chown mysql:mysql /usr/local/mysql/my.cnf
然后修改my.cnf配置
在skip-external-locking上面插入(配置可以自定义)
user = mysql
pid-file = /usr/local/mysql/mysql.pid
socket = /tmp/mysq.sock
port = 3306
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
tmpdir = /tmp
language = /usr/local/mysql/share/mysql/English
将里面的# -skin-dbd 注释掉,否则在执行启动mysql命令 时会报错误
为了能在ubuntu系统下方便的使用mysql, 我们还需要安装 mysql-client-5.0 (客户端)
apt-get install mysql-client-5.0
初始化数据库
/usr/local/mysql/bin/mysql_install_db --defaults-file=/usr/local/mysql/my.cnf --user=mysql
执行结果
Installing MySQL system tables...
080917 14:36:16 [Warning] Storage engine 'SPHINX' has conflicting typecode. Assigning value 42.
OK
Filling help tables...
080917 14:36:16 [Warning] Storage engine 'SPHINX' has conflicting typecode. Assigning value 42.
OK
………………..
以上提示表示执行成功
此时你会发现/user/local/mysql 目录下多了一个data文件夹,这文件夹里存放的是mysql数据内容
我们需要给该目录赋予用户权限和写的权限
chown mysql:mysql -R /usr/local/mysql/data/
chmod -R o+w /usr/local/mysql/data/
将mysql.server 拷贝成 /etc/init.d/mysqld 文件
cp /usr/local/mysql/share/mysql/mysql.server /etc/init.d/mysqld
并给mysqld添加执行权利
chmod 700 /etc/init.d/mysqld
通过执行
/etc/init.d/mysqld start 启动mysql 也可以使用stop | restart 等一些命令
然后我们输入mysql 命令,进去
Mysql>
输入
show engines;
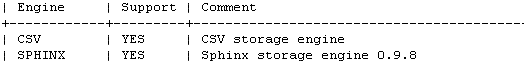
此时我们可以看到已经包含sphinxSE 引擎
到此myql部分启动完毕
接着我们来安装sphinx-0.9.8-rc2
cd sphinx-0.9.8-rc2/
CPPFLAGS=-I/usr/include/python2.4
LDFLAGS=-lpython2.4
./configure --prefix=/usr/local/sphinx --with-mysql=/usr/local/mysql
make
make install
cd ../
安装完成后
将sphinx.conf.dist拷贝成sphinx.conf文件
cp /usr/local/sphinx/etc/sphinx.conf.dist /usr/local/sphinx/etc/sphinx.conf
修改sphinx.conf中的配置如下:(配置可以自定义)
sql_host = localhost
sql_user = root
sql_pass =
sql_db = test
sql_port = 3306
加载索引
/usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf --all
注: 先要给libmysqlclient.so.16 建立软链接
ln -s /usr/local/mysql/lib/mysql/libmysqlclient.so.16 /usr/lib/libmysqlclient.so.16
再通过
/usr/local/sphinx/bin/searchd --config /usr/local/sphinx/etc/sphinx.conf 开启索引监听
为了下面测试方便,我们先将sphinx.conf自带的example.sql脚本倒入的mysql中
mysql < /usr/local/sphinx/etc/example.sql //创建了一个test库,并建立了documents测试表和数据
到此安装部分基本结束,大功告成了一半,下面我们来谈谈他们的使用。
四、开始使用
1、 在mysql中的使用SphinxSE方式调用Sphinx
首先建立一张索引专用表:
CREATE TABLE `sphinx` (
`id` int(11) NOT NULL,
`weight` int(11) NOT NULL,
`query` varchar(255) NOT NULL,
`CATALOGID` INT NOT NULL,
`EDITUSERID` INT NOT NULL,
`HITS` INT NULL,
`ADDTIME` INT NOT NULL, KEY
`Query` (`Query`)
) ENGINE=SPHINX DEFAULT CHARSET=utf8 CONNECTION='sphinx://localhost:3312/test1'
test1:索引的名称,可以在sphinx.conf中查找到
建立完索引专用表后,我们就可以在mysql中使用它了,例如,在mysql中输入
SELECT doc. * FROM documents doc JOIN sphinx ON ( doc.id = sphinx.id )
WHERE query = 'doc;mode= any '
运行后,结果记录中将会显示包含doc字符串的所用记录行
关于query的语法,还有sphinx的配置等信息你可以请参考:
http://www.sphinxsearch.com/doc.html
这里有十分详细的介绍,在这里我们只做一个简单的介绍,希望能起到抛砖引玉的效果。
2、 中文分词的应用
在应用之前我们先将apache2和 phpmyadmin装上,以便输入中文进行测试
apt-get install apache2
apt-get install phpmyadmin
访问:http://192.168.2.249/phpmyadmin/ 出现了熟悉的界面,ok,安装成功.
接着我们需要修改/etc/php5/apache2/php.ini 中的
mysql.default_socket 值 设置成 /tmp/mysql.sock
这样我们就可以在http://192.168.2.249/phpmyadmin/ 上通过root用户(密码空) 访问mysql了
生成和使用分词字典
mmseg -u /root/mmseg-0.7.3/data/unigram.txt
将生成unigram.txt.lib 文件
将文件拷贝到 /usr/local/sphinx/下面,命名为uni.lib
cp unigram.txt.lib /usr/local/sphinx/uni.lib
修改 sphinx.conf(/usr/local/sphinx/etc/sphinx.conf)配置文件
在索引中加入
charset_type = zh_cn.utf-8
charset_dictpath = /usr/local/sphinx/
配置
然后通过
/usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf -all
(如果searchd已经再运行,先kill 它再运行,下一部分,我们会介绍怎样在searchd运行的状态下,加载索引)
重建索引,成功后,开启索引监听
/usr/local/sphinx/bin/searchd --config /usr/local/sphinx/etc/sphinx.conf
这样,就可以在phpmyadmin中进行测试了。
SELECT doc. * FROM documents doc JOIN sphinx ON ( doc.id = sphinx.id )
WHERE query = '张学友;mode= any '
注意:在添加完数据后,需要重新加载索引,这样新的数据才能被缓存进去
五、实际应用介绍
通过以上的介绍,现在我们已经基本能使用这套东西了,下面我们来对索引的管理做一些介绍。
实时更新索引
在实际应用中往往有这么一种情况,数据库数据很大,比如我们的歌曲表,如果我们每次都去更新整个表的索引,对系统得开销将非常大,显然这是不合适,这时我们会发现,每天我们需要更新的数据相比较而言较少,在这种情况下我们就需要使用“主索引+增量索引”的模式来实现实时更新的功能。
这个模式实现的基本原理是设置两个数据源和两个索引,为那些基本不更新的数据建立主索引,而对于那些新增的数据建立增量索引。主索引的更新频率我们可以设置的长一些(可以设置在每天的午夜进行更新),而增量索引的更新频率,我们可以将时间设置的很短(几分钟左右),这样在用户搜索的时候,我们可以同时查询这两个索引的数据。
下面,我们通过一个简单的例子来描述一下怎样实现这种模式
以sphinx.conf中默认的数据为例:
先在mysql中插入一个计数表和两个索引表
CREATE TABLE sph_counter
(
counter_id INTEGER PRIMARY KEY NOT NULL,
max_doc_id INTEGER NOT NULL
);
//主索引使用(确认之前是否已经建立过该表,如果已经建立,这里就不需要重新建了)
CREATE TABLE `sphinx` (
`id` int(11) NOT NULL,
`weight` int(11) NOT NULL,
`query` varchar(255) NOT NULL,
`CATALOGID` INT NOT NULL,
`EDITUSERID` INT NOT NULL,
`HITS` INT NULL,
`ADDTIME` INT NOT NULL, KEY
`Query` (`Query`)
) ENGINE=SPHINX DEFAULT CHARSET=utf8 CONNECTION='sphinx://localhost:3312/test1'
//增量索引使用
CREATE TABLE `sphinx1` (
`id` int(11) NOT NULL,
`weight` int(11) NOT NULL,
`query` varchar(255) NOT NULL,
`CATALOGID` INT NOT NULL,
`EDITUSERID` INT NOT NULL,
`HITS` INT NULL,
`ADDTIME` INT NOT NULL, KEY
`Query` (`Query`)
)ENGINE=SPHINX DEFAULT CHARSET=utf8 CONNECTION='sphinx://localhost:3312/ test1stemmed '
数据库操作完毕后再来配置sphinx.conf
source src1
{
sql_query_pre = REPLACE INTO sph_counter SELECT 1, MAX(id) FROM documents
sql_query = "
SELECT id, group_id, UNIX_TIMESTAMP(date_added) AS date_added, title, content "
FROM documents "
WHERE id<=( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 )
………….. //其他可以默认
}
source src1throttled : src1
{
sql_ranged_throttle = 100
sql_query = "
SELECT id, group_id, UNIX_TIMESTAMP(date_added) AS date_added, title, content "
FROM documents "
WHERE id>( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 )
}
index test1 //主索引
{
source = src1
……….
}
index test1stemmed : test1 //增量索引
{
source = src1throttled
……
}
配置完成后,我在通过
/usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf -all 和
/usr/local/sphinx/bin/searchd --config /usr/local/sphinx/etc/sphinx.conf
重新加载索引,执行成功后我们就可以来使用它了。
你可以往documents表中添加新的数据,比如我们插入一条这样的数据:
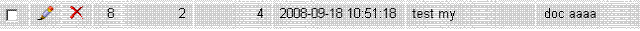
执行命令:
SELECT doc.* FROM documents doc join sphinx on (doc.id=sphinx.id) where query='test'
你会发现你刚添加的数据没有被检索出来
然后执行:
SELECT doc.* FROM documents doc join sphinx1 on (doc.id=sphinx1.id) where query='test'
你会发现数据是空的,这时我们就需要来更新增量索引了。
通过执行:
/usr/local/sphinx/bin/indexer --rotate --config /usr/local/sphinx/etc/sphinx.conf test1stemmed 命令来更新增量索引(正式使用时,我们可以将该命令配置到系统计划任务中,每格几分钟执行一次)
--rotate: 该参数可以使我们在不需要停止searchd的情况下,直接加载索引
执行完命令该命令后,我们再来查看一下增量索引的数据
SELECT doc.* FROM documents doc join sphinx1 on (doc.id=sphinx1.id) where query='test'
你会发现新添加的数据被检索出来的。
主索引的更新:
/usr/local/sphinx/bin/indexer --rotate --config /usr/local/sphinx/etc/sphinx.conf test1 (我们可以设置成每天的午夜执行)
只有在更新了主索引后,
SELECT doc.* FROM documents doc join sphinx on (doc.id=sphinx.id) where query='test'
的结果才会被更新
我们也可以通过合并索引的方式使主索引的数据保持更新
通过执行
/usr/local/sphinx/bin/indexer --merge test1 test1stemmed --merge-dst-range deleted 0 0 --rotate
可以将增量索引test1stemmed合并到主索引test1中去
注意:在你测试的过程中,mysql的查询缓存可能会给你带来一些困惑,所以测试时最好将其关闭。
关闭方法:
set global query_cache_size = 0; //禁止缓存开销
你可以通过 SHOW VARIABLES LIKE '%query_cache% 来察看缓存状态
到此Mysql+sphinx+中文分词的应用部分介绍完毕了。
总结
对于这块的学习,我也是刚起步,有些地方可能介绍的不是很到位,希望读者不要在意,
读者可以参考http://www.sphinxsearch.com/doc.html 的文档,那里有非常详细的介绍,对初学者来说,我这篇文章或许能帮上点忙。
转载请写明出处,谢谢!
这篇关于Mysql+sphinx+中文分词简介(ubuntu)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







