本文主要是介绍Elastic Connectors:增量同步对性能的影响,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Artem Shelkovnikov
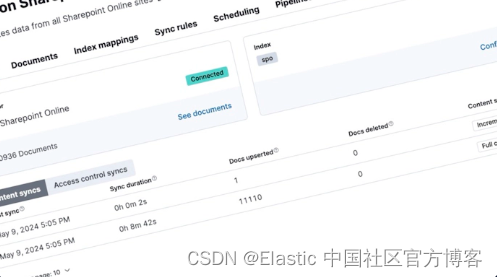
Elastic 连接器是一种 Elastic 集成,可将数据从原始数据源同步到 Elasticsearch 索引。连接器使你能够创建可搜索的只读数据源副本。
有许多连接器支持各种第三方,例如:
- MongoDB
- 各种 SQL DBMS,例如 MySQL、PostgreSQL、MSSQL 和 OracleDB
- Sharepoint Online
- Amazon S3
- 还有更多。完整列表可在此处查看。
连接器支持两种类型的内容同步作业:完全同步和增量同步。
完全同步
完全同步是从第三方服务中提取所有所需文档并将其导入 Elasticsearch 的同步。因此,如果你已将网络驱动器连接器设置为从文件夹 “\Documents/Reports\2022**.docx” 导入所有文档,则在完全同步期间,连接器将获取符合此条件的所有文档并将其全部发送到 Elasticsearch。简化的伪代码如下所示:
connector = NetworkDriveConnector(host="192.168.0.105",path="\\Documents\Reports\2025\**.doc"
)for incoming_document_metadata in connector.extract_documents():content = connector.download(incoming_document_metadata)document = {"id": incoming_document_metadata["id"]"content": content}elasticsearch.ingest(document)
这种方法效果很好,直到同步开始耗时过长。这可能是因为连接器获取了比所需更多的数据。例如,为什么要获取未更改的旧文件并将其发送到 Elasticsearch?有人可能会说文件的元数据可能不可靠,因此需要再次获取所有文件并将其发送到 Elasticsearch。确实,情况可能如此,但如果我们可以信任从第三方获取的数据的元数据,我们就可以提取更少的数据。增量同步是实现此目的的方法。
增量同步
大多数情况下,如果编写得当,连接器会花大量时间执行 IO 操作。回到示例代码,有 3 个地方会发生 IO:
connector = NetworkDriveConnector(host="192.168.0.105",path="\\Documents\Reports\2025\**.doc"
)# Place #1: reading document metadata from 3rd-party system
for incoming_document_metadata in connector.extract_documents():# Place #2: reading document content from 3rd-party systemcontent = connector.download(incoming_document_metadata)document = {"id": incoming_document_metadata["id"]"content": content}# Place #3: ingesting the resulting document into Elasticsearchelasticsearch.ingest(document)
这些地方都可能成为瓶颈,并在同步过程中耗费大量时间。
这就是增量同步发挥作用的地方。其目的是尽可能减少任何阶段的 IO 量。
潜在的优化
从第三方系统获取更少的文档
修改上面的示例,代码可能如下所示:
connector = NetworkDriveConnector(host="192.168.0.105",path="\\Documents\Reports\2025\**.doc"
)# We can store last sync time somewhere
last_sync_time = connector.fetch_last_sync_time()# And later use it querying Network Drive
for incoming_document_metadata in connector.extract_documents(from=last_sync_time):content = connector.download(incoming_document_metadata)document = {"id": incoming_document_metadata["id"]"content": content}elasticsearch.ingest(document)
如果我们的第三方系统中只有少量文档发生变化,我们可以显著加快提取过程。但是,对于网络驱动器(netword drive)来说,这是不可能的 - 它的 API 不支持通过元数据过滤文档。我们将无法避免扫描网络驱动器的全部内容。
跳过下载自上次同步以来未发生更改的文件内容
在同步过程中,下载文件内容需要花费大量时间。如果文件相当大、连接不稳定或吞吐量较低,则在同步第三方内容时,下载文件内容将花费大部分时间。如果我们跳过下载其中一些文件,这已经可以显著加快连接器的速度。
考虑以下示例伪代码:
connector = NetworkDriveConnector(host="192.168.0.105",path="\\Documents\Reports\2025\**.doc"
)last_sync_time = connector.fetch_last_sync_time()for incoming_document_metadata in connector.extract_documents():# If document timestamp did not change then not fetching# document content can save us a lot of timeif incoming_document_metadata["last_updated_at"] > last_sync_timecontent = connector.download(incoming_document_metadata)document = {"id": incoming_document_metadata["id"]"content": content}elasticsearch.ingest(document)
如果没有更新文档,同步速度实际上会比完全同步内容快几个数量级。
跳过将未修改的文档提取到 Elasticsearch 的过程
虽然这看起来微不足道,但将数据提取到 Elasticsearch 需要花费大量时间 - 尽管通常比从第三方系统下载内容的时间要短。我们可以开始存储每个文档的时间戳,如果时间戳没有改变,则不将文档发送到 Elasticsearch。
我们可以将此方法与之前的方法结合起来,以在同步期间节省尽可能多的时间。
connector = NetworkDriveConnector(host="192.168.0.105",path="\\Documents\Reports\2025\**.doc"
)# We need to fetch only IDs and timestamps as it's sufficient to make a decision.
# For large indices it can still take a good amount of RAM, but that's the price.
existing_documents = connector.fetch_existing_documents(fields=["id", "_timestamp"])for incoming_document_metadata in connector.extract_documents():existing_document_metadata = existing_documents[document_metadata["id"]]# If a document for this 3rd-party record exists in Elasticsearch index# and timestamp did not change, then skip downloading its content# and skip ingesting the documentif existing_document_metadata:incoming_document_timestamp = incoming_document_metadata["last_updated_at"]existing_document_timestamp = existing_document_metadata["_timestamp"]if incoming_document_timestamp == existing_document_timestamp:# Skip the document for goodcontinue;content = connector.download(incoming_document_metadata)document = {"id": incoming_document_metadata["id"]"content": content,"_timestamp" = incoming_document_metadata["last_updated_at"]}elasticsearch.ingest(document)
这种方法有助于在运行同步时节省更多时间。现在让我们看看此类改进的性能考虑因素。
增量同步性能
现在,既然我们已经研究了简化的代码,了解了增量同步的工作原理,我们可以尝试估计潜在的性能改进。
对于某些连接器,增量同步以某种方式实现,以优化从第三方获取数据的方式。例如,Sharepoint Online 连接器通过增量 API 获取一些数据 - 仅收集上次同步后更改的文档。这以明显的方式提高了性能 - 更少的数据 -> 更少的时间将数据同步到最新状态。
对于其他连接器(目前除 Sharepoint Online 连接器外的所有连接器),增量同步由框架以通用方式完成,这在前面的章节之一 “跳过将未修改的文档提取到 Elasticsearch” 中进行了描述。
连接器仍然从第三方数据源收集所有数据(因为它不提供仅提取更改的记录的方法)。但是,如果此数据包含时间戳,则连接器框架会将已提取文档的文档 ID 和时间戳与传入文档进行比较。如果 Elasticsearch 中存在文档,并且时间戳与从第三方数据源收到的时间戳相同,则不会将此文档发送到 Elasticsearch。
我们已经描述了使用增量同步来提高性能的抽象方法,但我们已经在连接器中实现了这些方法,所以让我们深入研究一下实际数字吧!
性能测试
我们将通过这些性能测试估计增量同步的粗略改进幅度,但目标不是高精度。
之所以选择 Google Drive 和 Github 作为本次测试的两个连接器,是因为它们具有不同的 IO 配置文件。
Google Drive 就像一个文件存储。它:
- 有一个快速的 API,不会过早节流
- 通常存储大量可变大小的二进制内容 - 从小到非常大
- 通常存储少量记录 - 数万或数十万而不是数百万
GitHub 数据是通过更经典的 API 提取的,它:
- 经常节流
- 包含许多比 Google Drive 中的记录小得多的记录
- 根本不发送二进制内容
由于这些差异,增量同步性能将有很大不同。
两项测试都包含以下强制性步骤:
- 对第三方系统进行完全同步
- 修改第三方系统上的某些文档
- 运行增量同步并检查所需的时间
此设置非常简单,但已经可以很好地表明性能改进的程度。两项测试略有不同,我将在下一节中提供结果和评论。
设置 #1 - Google Drive 连接器
初始设置如下:
- Google Drive 上有 1 个文件夹,其中包含 1553 个文件(其中 100 个大小为 2MB,1443 个大小为 5KB)
- 执行完全同步并将这些数据输入 Elasticsearch
- 将更多文件添加到 Google Drive 中,使其文件数达到 10144 个(其中 100 个大小为 2MB,其余文件大小均为 5KB)
- 再次执行增量同步以提取新数据
- 然后对 Google Drive 上的文件进行一些细微更改(添加 1 个,删除 2 个)
- 再次执行增量同步
- 再次执行完全同步以将运行时间与增量同步进行比较
下表包含所述测试的结果和注释:
| Sync 描述 | 运行时间 | 添加文档数 | 文档删除数 | 注释 |
|---|---|---|---|---|
| 初始完全同步 | 0h 4m 0s | 1553 | 0 | 这是初始同步 - 它会提取所有文档 |
| 在 Google Drive 中添加更多数据后进行增量同步 | 0h 20m 9s | 7939 | 0 | 运行时间如预期一样长 - 大量文档输入 |
| Google Drive 中的部分数据发生轻微更改后进行增量同步 | 0h 1m 25s | 1 | 2 | 运行速度非常快。它仍然大量调用 Google Drive API,但不必将 200+MB 的数据导入 Elasticsearch |
| 完全同步以比较性能 | 0h 23m 23s | 10144 | 0 | 正如预期的那样,这需要花费大量时间 —— 所有数据都从 Google Drive 下载并发送到 Elasticsearch,即使数据没有变化。我们可以假设下载数据并将其上传到 Elasticsearch 进行设置需要 22 分钟 |
总之,增量同步显著提高了连接器的性能,因为大部分时间都花在连接器下载文件内容并将这些内容发送到 Elasticsearch 上。完全同步带来 2 * 100 + 1443 * 5 / 1024 = 207MB 的内容 - 既由连接器下载,又被提取到 Elasticsearch 中。如果只更改 1 个大文件,则这个数量只会变为 2MB - 变化幅度为 100。这很好地解释了性能改进。
设置 #2:GitHub 连接器
GitHub 连接器非常不同,因为它同步的实际数据量相对较小 - 问题、拉取请求等相当小,而它们却很多。此外,GitHub 有严格的限制政策,并且会大量限制连接器。
为了给出一个很好的现实世界示例,我们将使用 Kibana Github 存储库和 GitHub 连接器并观察其性能。
| Sync 描述 | 运行时间 | 添加的文档数 | 删除的文档数 | 注释 |
|---|---|---|---|---|
| 初始完全同步 | 8h 40m 1s | 147421 | 0 | --- |
| 增量同步立即运行 | 9h 6m 7s | 59 | 0 | 这次同步花费了更多时间,主要是因为它不断受到限制。连接器必须从 GitHub 获取所有数据,但只发送了 59 条记录,总容量不到 1MB |
| 下一次增量同步 | 9h 2m 52s | 191 | 1 | 本次同步是在上一次增量同步完成后立即触发的。由于数据几乎相同,且节流是连接器运行时间的主要因素,因此运行时间相同 |
关键要点
如你所见,增量同步对 Github 连接器的性能没有任何改进 - 几乎没有任何优化空间,因为连接器大部分时间都花在查询系统和等待节流停止上。
提取的文档相当小,因此网络吞吐量使用量很小。为了缩短连接器的运行时间,增量同步实际上必须限制对 Github 的查询次数,但目前它尚未在连接器中实现。
总结
影响增量同步性能的主要因素是什么?简而言之,就是提取的原始数据量。
对于 Sharepoint Online 连接器,有一种特殊的逻辑可以通过增量 API 获取较少的数据。这节省了大量时间,因为增量 API 允许连接器不提取未更改的文件。文件往往很大,因此不下载和提取它们将节省大量时间。
对于其他连接器,增量同步是通用的 - 它只是在将文档提取到 Elasticsearch 之前检查文档时间戳 - 如果此文档已在索引中并且时间戳没有更改,则不会提取它。它比 Sharepoint Online 采用的以前的方法节省的时间更少,但适用于所有连接器。一些连接器(包含大型文档的连接器)从这种逻辑中受益匪浅,而其他连接器(受到第三方系统限制且包含相对较小的文档的连接器)则无法从增量同步中获益。
此外,如果 Elasticsearch 负载过重,增量同步不太可能受到 Elasticsearch 的限制,从而使其在负载下性能更高。
让我们看看下面的图表:
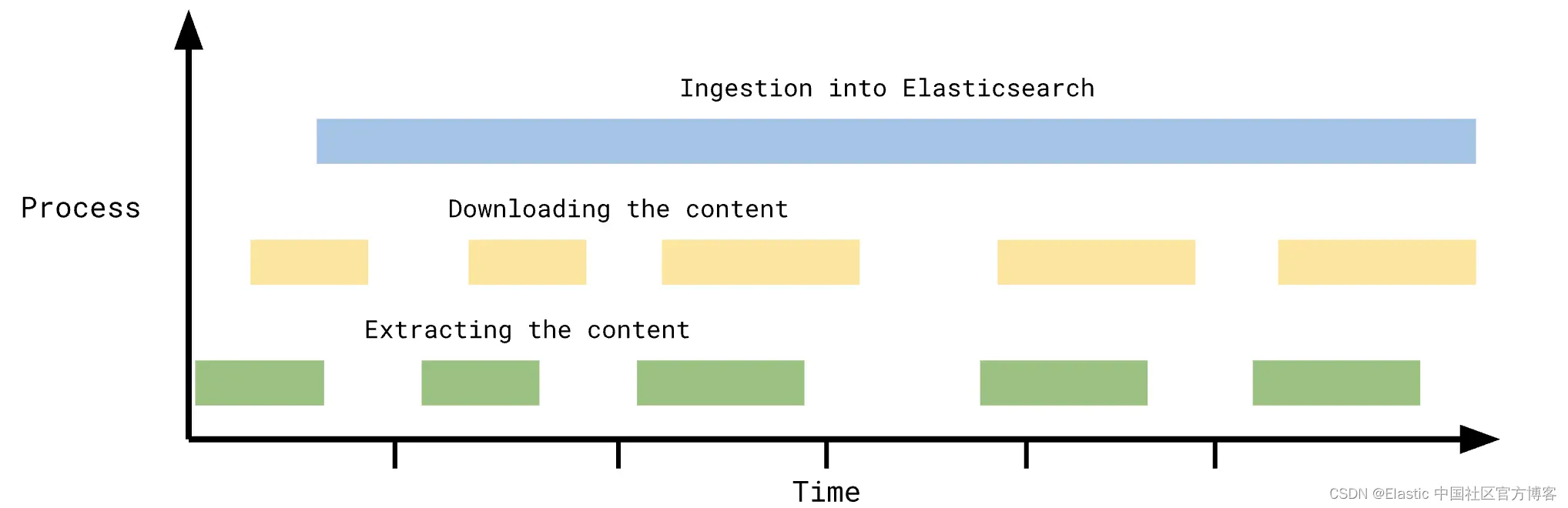
在图表中,你可以看到内容提取和提取的每个部分在时间线上花费了多少时间。在上面的例子中,连接器花费最多的时间用于提取数据,甚至暂停提取和下载内容。在这种情况下,增量同步有可能将同步的运行时间提高 30 - 40%。
让我们看另一个例子 - 一个具有节流和低吞吐量但在 Elasticsearch 中存储很少数据的系统(Sharepoint Online、GitHub、Jira、Confluence):
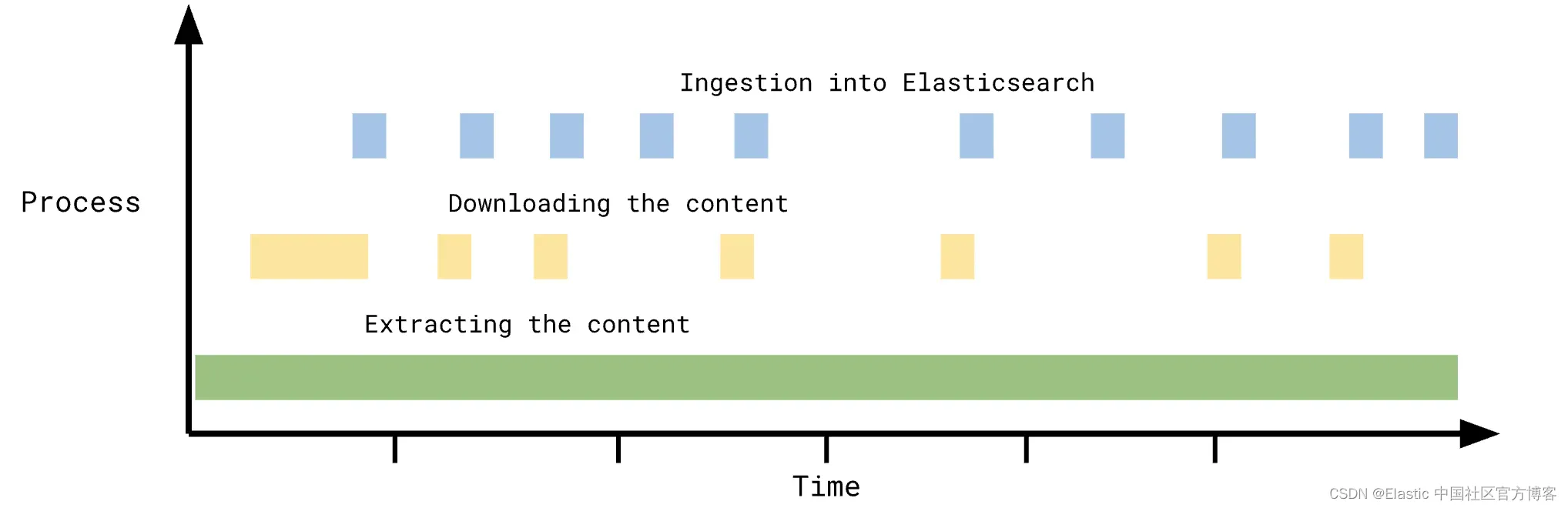
该系统不会从通用增量同步中受益太多 - 大部分时间都花在从第三方系统提取内容上。
最后一个例子 - 快速且可访问的系统,在 Elasticsearch(Google Drive、Box、OneDrive、Network Drive)中存储大量数据:
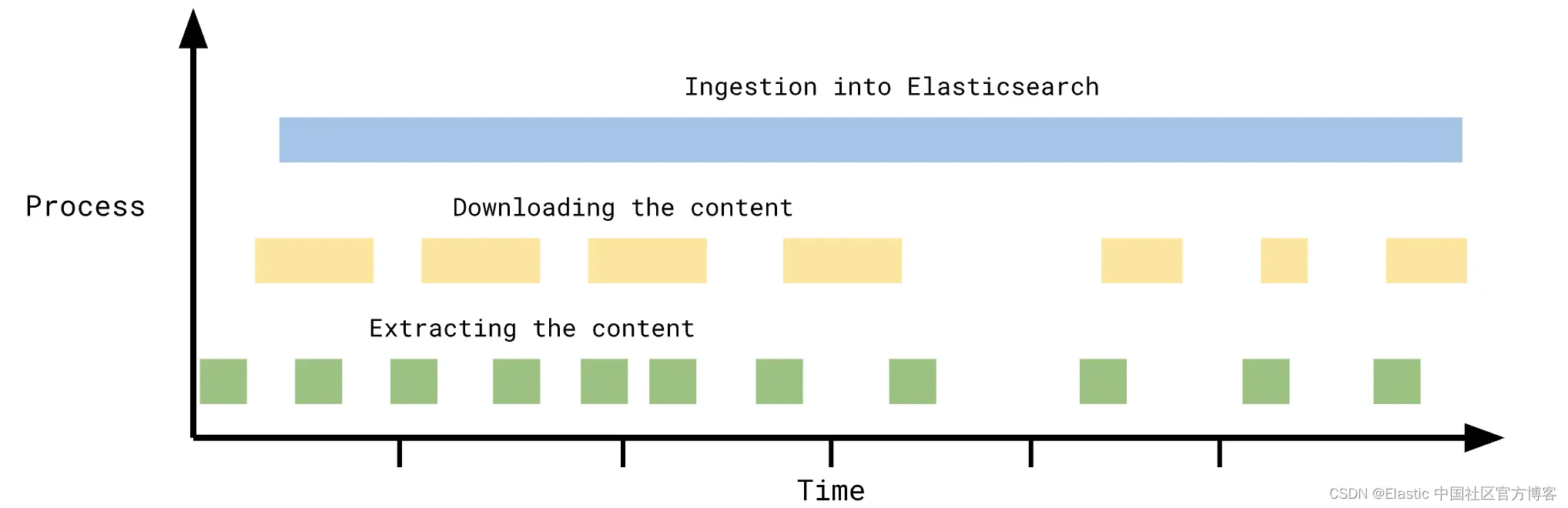
如果在同步之间,此类系统中没有太多条目发生变化,则通用增量同步将使该系统受益匪浅。
目前,可能从增量同步中获益最多的连接器有:
- Azure Blob Storage
- Box
- Dropbox
- Google Cloud Storage
- Google Drive
- Network Drive
- OneDrive
- S3
- Sharepoint Online
其他连接器从增量同步中获益较少,或者根本没有获益,但这里没有一刀切的答案。性能在很大程度上取决于所摄取数据的概况。每个单独的文档越大,收益就越大。
你可以使用来自任何来源的数据构建搜索。查看此网络研讨会,了解 Elasticsearch 支持的不同连接器和来源。
准备好自己尝试一下了吗?开始免费试用。
原文:Elastic Connectors: Performance impact of incremental syncs — Elastic Search Labs
这篇关于Elastic Connectors:增量同步对性能的影响的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







