本文主要是介绍【30天精通Prometheus:一站式监控实战指南】第14天:jmx_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

亲爱的读者们👋
欢迎加入【30天精通Prometheus】专栏!📚 在这里,我们将探索Prometheus的强大功能,并将其应用于实际监控中。这个专栏都将为你提供宝贵的实战经验。🚀
Prometheus是云原生和DevOps的核心监控工具,我们将从基础概念开始,逐步涵盖配置、查询、告警和可视化。💪
在接下来的30天里,我们将解锁Prometheus的实战技巧,通过案例和分享,助你深入理解其工作原理。📆
目标:30天后,你将熟练掌握Prometheus,为未来的项目挑战做好准备!💯
这是一段精彩旅程,期待你的加入!🎉
文章目录
- 一、jmx_exporter概述📘
- 二、安装jmx_exporter💾
- 2.1 访问jmx_exporter官方网站 🌐
- 2.2 选择适合的版本🔍
- 2.3 下载jmx_prometheus_javaagent-1.0.0.jar⬇️
- 2.4 运行jmx_exporter🚀
- 三、jmx_exporter指标和配置详解📖
- 3.1 config.yaml
- 四、实战演练:生产环境搭建指南🔨
- 4.1 使用jmx_exporter监控kafka
- 4.1.1 上传jmx_prometheus_javaagent-1.0.0.jar
- 4.1.2 创建kafka监控的kafka-common.yaml文件
- 4.1.3 修改kafka的启动脚本
- 4.1.4 重启kafka
- 4.1.5 查看数据
- 相关资料下载地址📚
一、jmx_exporter概述📘
定义
jmx_exporter是一个开源工具,它能够将Java应用程序的JMX(Java Management Extensions)指标导出为Prometheus可以识别的度量数据格式。JMX Exporter充当了一个桥梁,使得Prometheus能够监控和收集Java应用的性能数据。
功能
度量数据导出:JMX Exporter可以从Java应用程序中选择并配置需要导出的JMX指标,这些指标既可以是JVM内部的性能数据,如内存使用情况、线程状态等,也可以是应用程序特定的自定义指标。
数据格式转换:导出的JMX指标会被JMX Exporter转换为Prometheus格式的度量数据,这是一种易于阅读和处理的文本格式,非常适合Prometheus服务器的存储和查询。
配置灵活性:用户可以通过配置文件定义需要导出的JMX指标以及相关的匹配规则,提供了高度的定制性和配置灵活性。
支持标签:与Prometheus一致,JMX Exporter也支持为导出的度量数据添加标签(labels),这些标签可以作为元数据,帮助用户更容易地进行数据查询和可视化。
轻量级与高性能:JMX Exporter被设计为轻量级且高性能,旨在最小化对监控系统的性能影响。
应用场景
Java应用程序性能监控:对于任何支持JMX的Java应用程序,包括独立的Java进程、Web服务器(如Tomcat)或Spring Boot应用程序等,JMX Exporter都能帮助导出关键的性能指标,供Prometheus监控和分析。
故障排查与性能优化:当Java应用程序出现异常或性能下降时,通过JMX Exporter导出的数据,开发者和运维人员可以快速定位问题所在,分析性能瓶颈,并进行相应的优化。
自动警报与通知:结合Prometheus的警报机制,当某个JMX指标超出预设的阈值时,可以自动触发警报并发送通知,从而实现快速响应和故障处理。
数据可视化:通过将JMX数据导入可视化工具(如Grafana),可以创建丰富的仪表板,直观地展示Java应用程序的运行状态和性能数据。
二、安装jmx_exporter💾
注意事项和常见问题
环境配置:确保Java环境已经正确安装并配置,因为jmx_exporter是一个Java程序,检查系统是否有足够的权限来安装和运行jmx_exporter。
版本兼容性:选择与你的Java应用程序和Prometheus版本兼容的jmx_exporter版本。
配置文件:在安装之前,准备好jmx_exporter的配置文件(如jmx_exporter.yml),以便能够正确地导出所需的JMX指标。
确保jmx_exporter将要监听的端口没有被其他服务占用。
2.1 访问jmx_exporter官方网站 🌐
- 打开浏览器,访问jmx_exporter的官方下载页面,通常位于Github网站的子目录下:https://github.com/prometheus/jmx_exporter/tree/release-1.0.0/docs
2.2 选择适合的版本🔍
- 在下载页面,你将看到jmx_prometheus_javaagent-1.0.0.jar源码包。根据你的操作系统选择适合的版本
2.3 下载jmx_prometheus_javaagent-1.0.0.jar⬇️
- 点击所选版本的下载链接,将jmx_prometheus_javaagent-1.0.0.jar的二进制包下载到你的本地计算机。
2.4 运行jmx_exporter🚀
java -javaagent:./jmx_prometheus_javaagent-1.0.0.jar=12345:config.yaml -jar yourJar.jar
三、jmx_exporter指标和配置详解📖
3.1 config.yaml
---
startDelaySeconds: 0
hostPort: 127.0.0.1:1234
username:
password:
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
includeObjectNames: ["org.apache.cassandra.metrics:*"]
excludeObjectNames: ["org.apache.cassandra.metrics:type=ColumnFamily,*"]
autoExcludeObjectNameAttributes: true
excludeObjectNameAttributes:"java.lang:type=OperatingSystem":- "ObjectName""java.lang:type=Runtime":- "ClassPath"- "SystemProperties"
rules:- pattern: 'org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)'name: cassandra_$1_$2value: $3valueFactor: 0.001labels: {}help: "Cassandra metric $1 $2"cache: falsetype: GAUGEattrNameSnakeCase: false
- startDelaySeconds: 0
设置jmx_exporter在启动后延迟开始抓取指标的时间(以秒为单位),设置为0意味着jmx_exporter会立即开始抓取指标,这个延迟可以用于等待应用程序完全启动并初始化其JMX MBeans。 - hostPort: 127.0.0.1:1234
指定通过远程 JMX 连接到的主机和端口,jmx_exporter将尝试连接到这个地址和端口来抓取JMX指标。如果既没有指定 this 也没有指定 jmxUrl,则将与本地 JVM 通信 - username
用于远程 JMX 密码认证的用户名,如果JMX代理配置了身份验证,这个参数是必需要配置的。 - password
用于远程 JMX 密码认证的密码,如果JMX代理配置了身份验证,这个参数是必需要配置的,与username一起用于身份验证。 - jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
要连接到的完整 JMX URL,它告诉jmx_exporter如何连接到JMX代理。如果你指定了jmxUrl,那么hostPort就不需要了,因为jmxUrl已经包含了连接所需的所有信息。如果 hostPort 是,则不应指定 - ssl: false
是否应通过 SSL 完成 JMX 连接,设置为false意味着不使用SSL。如果需要通过安全的SSL连接进行JMX通信,应将其设置为true。若要配置证书,必须设置以下系统属性:
-Djavax.net.ssl.keyStore=/home/user/.keystore
-Djavax.net.ssl.keyStorePassword=changeit
-Djavax.net.ssl.trustStore=/home/user/.truststore
-Djavax.net.ssl.trustStorePassword=changeit
- lowercaseOutputName: false
控制输出的指标名称是否应该被转换为小写。设置为false时,指标名称将保持原始大小写;设置为true时,所有输出的指标名称将被转换为小写。对于保持指标名称的一致性很有帮助,特别是当JMX MBeans的属性名称大小写不一致时 - lowercaseOutputLabelNames: false
控制输出的指标标签名称是否应该被转换为小写。设置为false时,标签名称将保持原始大小写。设置为true时,所有输出的标签名称将被转换为小写。有助于确保标签名称的一致性,便于在Prometheus中进行查询和聚合 - includeObjectNames: [“org.apache.cassandra.metrics:*”]
定义一个ObjectName的列表,jmx_exporter将只收集这些ObjectName对应的JMX MBeans的指标。在这个例子中,配置为只收集以“org.apache.cassandra.metrics:”开头的ObjectName对应的MBeans。这是一种过滤机制,用于减少收集的数据量,只关注感兴趣的部分。如果不配置,默认为:所有mBeans - excludeObjectNames: [“org.apache.cassandra.metrics:type=ColumnFamily,*”]
定义一个不被收集的ObjectName的列表。在这个例子中,配置为排除所有以“org.apache.cassandra.metrics:type=ColumnFamily,”开头的ObjectName。这可以用于进一步细化includeObjectNames中定义的列表,排除某些不需要的MBeans。默认值为:无 - autoExcludeObjectNameAttributes: true
控制当某些ObjectName的属性无法转换为标准的Prometheus指标类型时,是否自动排除这些属性。设置为true时,这样的属性将被自动排除。设置为false时,即使属性无法转换,也会被尝试收集,这可能会导致错误或不可预测的行为。这个选项有助于避免收集无效或不可用的数据。默认值为:true - excludeObjectNameAttributes
允许指定要从JMX指标收集中排除的特定ObjectName的属性。这个参数非常有用,当你想要收集大部分JMX MBean的属性,但又想排除某些不需要或者不适合作为监控指标的属性时。excludeObjectNameAttributes的结构是一个映射(map),其中键(key)是ObjectNames(需要采用规范形式),值(value)是一个字符串列表,表示要从该ObjectName中排除的属性名称。下述是一个例子:
"java.lang:type=OperatingSystem": ["ObjectName"]
"java.lang:type=Runtime": ["ClassPath","SystemProperties"]
- rules
一个规则列表,其中每个规则定义了如何从JMX MBeans中提取信息,并将其转换为Prometheus指标。规则会按顺序应用,一旦找到匹配的规则,处理就会停止,不匹配的属性将不会被收集。如果未指定,则默认以默认格式收集所有内容- pattern: ‘org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)’
一个正则表达式,用于匹配JMX MBean的属性。'org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)'这个正则表达式用于匹配Cassandra的JMX指标。捕获组(例如(\w+))可以在其他选项中使用,以便从匹配的字符串中提取信息 - name: cassandra_$1_$2
定义要设置的Prometheus指标的名称。可以使用正则表达式中的捕获组来动态构建指标名称,例如cassandra_$1_$2 - value: $3
指定指标的值。这可以是静态值,也可以是使用正则表达式捕获组提取的值,例如$3。如果未指定,则将使用抓取的 mBean 值 - valueFactor: 0.001
可选数字(如果未指定,则为抓取的 mBean 值)乘以,主要用于将 mBean 值从毫秒转换为秒 - labels: {}
标签名称到标签值对的映射。可以在每个中使用捕获组。 必须设置为使用此项。空名称和值将被忽略。如果未指定且未使用默认格式,则不会设置任何标签 - help: “Cassandra metric $1 $2”
指标的帮助文本。可以使用从中捕获组。 必须设置为使用此项。默认为 mBean 属性描述、属性域和属性名称 - cache: false
是否将 Bean 名称表达式缓存到规则计算(匹配和不匹配)。不建议对 Bean 值进行规则匹配,因为只有第一次抓取的值才会被缓存和重用。这可以提高收集大量 mban 时的性能。默认值为:false - type: GAUGE
指标的类型,必须设置为使用此项。默认值为:GAUGE、COUNTER、UNTYPED、name、UNTYPED - attrNameSnakeCase: false
将属性名称转换为蛇形大小写。这在与模式和默认格式匹配的名称中可以看出。例如,anAttrName 设置为 an_attr_name。默认值为:false
- pattern: ‘org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)’
四、实战演练:生产环境搭建指南🔨
4.1 使用jmx_exporter监控kafka
- 注意:kafka要对应exporter合适的版本
- 此处jmx_exporter版本为:jmx_prometheus_javaagent-1.0.0.jar
- kafka版本为:无zk,3.4.1的kafka kraft单节点
- kafka部署路径为:/home/deploy/kafka_2.13-3.4.1
4.1.1 上传jmx_prometheus_javaagent-1.0.0.jar
mv jmx_prometheus_javaagent-1.0.0.jar /home/deploy/kafka_2.13-3.4.1/libs/
4.1.2 创建kafka监控的kafka-common.yaml文件
vi /home/deploy/kafka_2.13-3.4.1/config/kraft/kafka-common.yml
lowercaseOutputName: truerules:
# Special cases and very specific rules
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Valuename: kafka_server_$1_$2type: GAUGElabels:clientId: "$3"topic: "$4"partition: "$5"
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), brokerHost=(.+), brokerPort=(.+)><>Valuename: kafka_server_$1_$2type: GAUGElabels:clientId: "$3"broker: "$4:$5"
- pattern : kafka.coordinator.(\w+)<type=(.+), name=(.+)><>Valuename: kafka_coordinator_$1_$2_$3type: GAUGE# Quota specific rules
- pattern: kafka.server<type=(.+), user=(.+), client-id=(.+)><>([a-z-]+)name: kafka_server_quota_$4type: GAUGElabels:resource: "$1"user: "$2"clientId: "$3"
- pattern: kafka.server<type=(.+), client-id=(.+)><>([a-z-]+)name: kafka_server_quota_$3type: GAUGElabels:resource: "$1"clientId: "$2"
- pattern: kafka.server<type=(.+), user=(.+)><>([a-z-]+)name: kafka_server_quota_$3type: GAUGElabels:resource: "$1"user: "$2"# Generic gauges with 0-2 key/value pairs
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+), (.+)=(.+)><>Valuename: kafka_$1_$2_$3type: GAUGElabels:"$4": "$5""$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+)><>Valuename: kafka_$1_$2_$3type: GAUGElabels:"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>Valuename: kafka_$1_$2_$3type: GAUGE# Emulate Prometheus 'Summary' metrics for the exported 'Histogram's.
#
# Note that these are missing the '_sum' metric!
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+), (.+)=(.+)><>Countname: kafka_$1_$2_$3_counttype: COUNTERlabels:"$4": "$5""$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.*), (.+)=(.+)><>(\d+)thPercentilename: kafka_$1_$2_$3type: GAUGElabels:"$4": "$5""$6": "$7"quantile: "0.$8"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+)><>Countname: kafka_$1_$2_$3_counttype: COUNTERlabels:"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.*)><>(\d+)thPercentilename: kafka_$1_$2_$3type: GAUGElabels:"$4": "$5"quantile: "0.$6"
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>Countname: kafka_$1_$2_$3_counttype: COUNTER
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>(\d+)thPercentilename: kafka_$1_$2_$3type: GAUGElabels:quantile: "0.$4"# Generic gauges for MeanRate Percent
# Ex) kafka.server<type=KafkaRequestHandlerPool, name=RequestHandlerAvgIdlePercent><>MeanRate
- pattern: kafka.(\w+)<type=(.+), name=(.+)Percent\w*><>MeanRatename: kafka_$1_$2_$3_percenttype: GAUGE
- pattern: kafka.(\w+)<type=(.+), name=(.+)Percent\w*><>Valuename: kafka_$1_$2_$3_percenttype: GAUGE
- pattern: kafka.(\w+)<type=(.+), name=(.+)Percent\w*, (.+)=(.+)><>Valuename: kafka_$1_$2_$3_percenttype: GAUGElabels:"$4": "$5"
4.1.3 修改kafka的启动脚本
vi /home/deploy/kafka_2.13-3.4.1/bin/kafka-run-class.sh
- 加在脚本的最开始
......
export JMX_PORT="9999"
export KAFKA_OPTS="-javaagent:/home/deploy/kafka_2.13-3.4.1/libs/jmx_prometheus_javaagent-1.0.0.jar=9998:/home/deploy/kafka_2.13-3.4.1/config/kraft/kafka-kraft-3_0_0.yml"
4.1.4 重启kafka
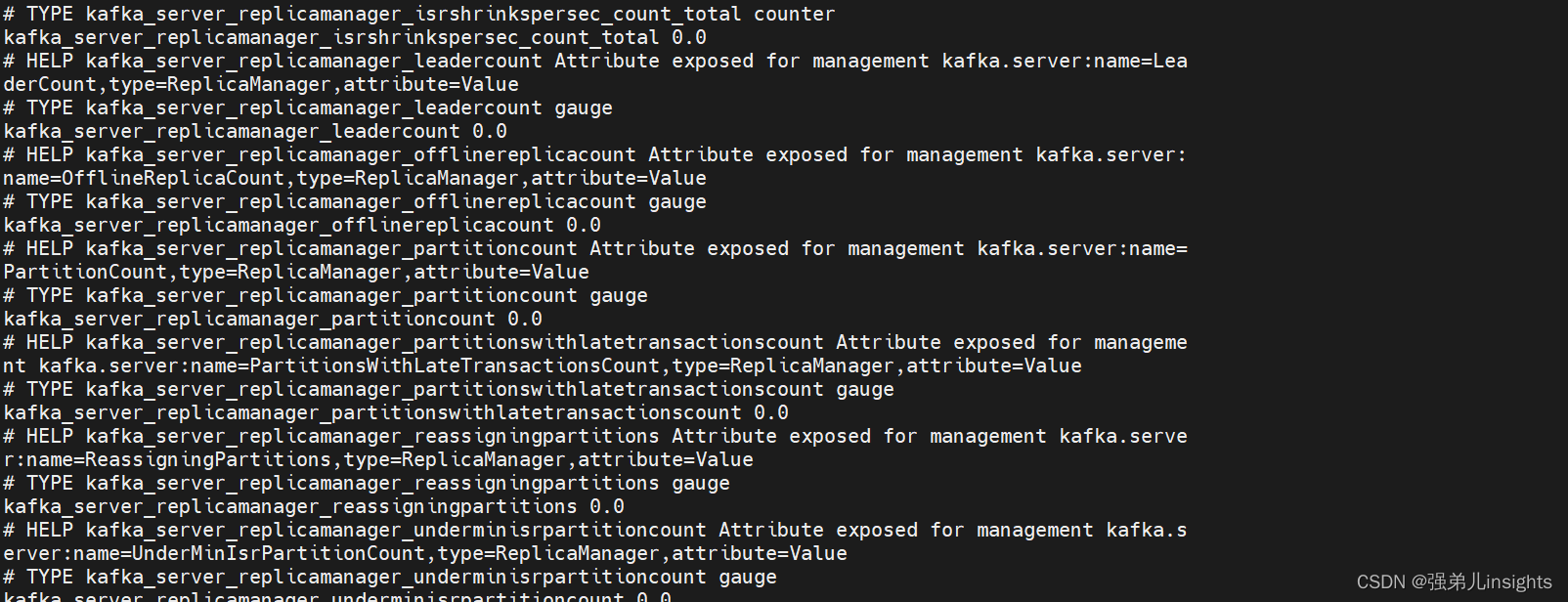
4.1.5 查看数据
curl http://localhost:9998/metrics
相关资料下载地址📚
- 官方文档:https://prometheus.io/docs/introduction/overview/
- 下载地址:https://github.com/prometheus/prometheus/releases/tag/v2.52.0
- 文档地址:https://prometheus.io/docs/prometheus/latest/installation/
- 离线包下载链接:https://pan.baidu.com/s/1ANF_AlFnM5_FMIbKBuzBmg 提取码:yqpt
这篇关于【30天精通Prometheus:一站式监控实战指南】第14天:jmx_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





